
Python爬虫基础之requestes模块
更新时间:2021年04月26日 09:59:57 作者:世界的隐喻
这篇文章主要介绍了Python爬虫基础之requestes模块,文中有非常详细的代码示例,对正在学习python爬虫的小伙伴们有非常好的帮助,需要的朋友可以参考下
一、爬虫的流程
开始学习爬虫,我们必须了解爬虫的流程框架。在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步:
1.指定 url,可以简单的理解为指定要爬取的网址
2.发送请求。requests 模块的请求一般为 get 和 post
3.将爬取的数据存储
二、requests模块的导入
因为 requests 模块属于外部库,所以需要我们自己导入库
导入的步骤:
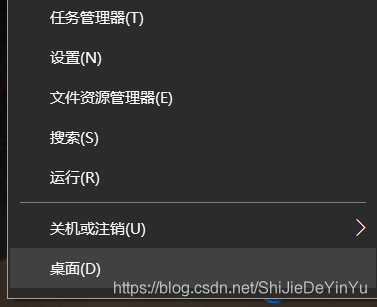
1.右键Windows图标
2.点击“运行”
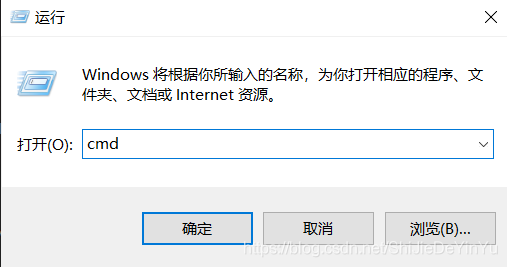
3.输入“cmd”打开命令面板
4.输入“pip install requests”,等待下载完成
如图:

如果还是下载失败,我的建议是百度一下,你就知道(我也是边学边写,是在是水平有限)
欧克,既然导入成功后我们就简单的来爬取一下搜狗的首页吧!
三、完整代码
import requests
if __name__ == "__main__":
# 指定url
url = "https://www.sougou.com/"
# 发起请求
# get方法会返回一个响应数据
response = requests.get(url)
# 获取响应数据
page_txt = response.text # text返回一个字符串的响应数据
# print(page_txt)
# 存储
with open("./sougou.html", "w", encoding = "utf-8") as fp:
fp.write(page_txt)
print("爬取数据结束!!!")
我们打开保存的文件,如图
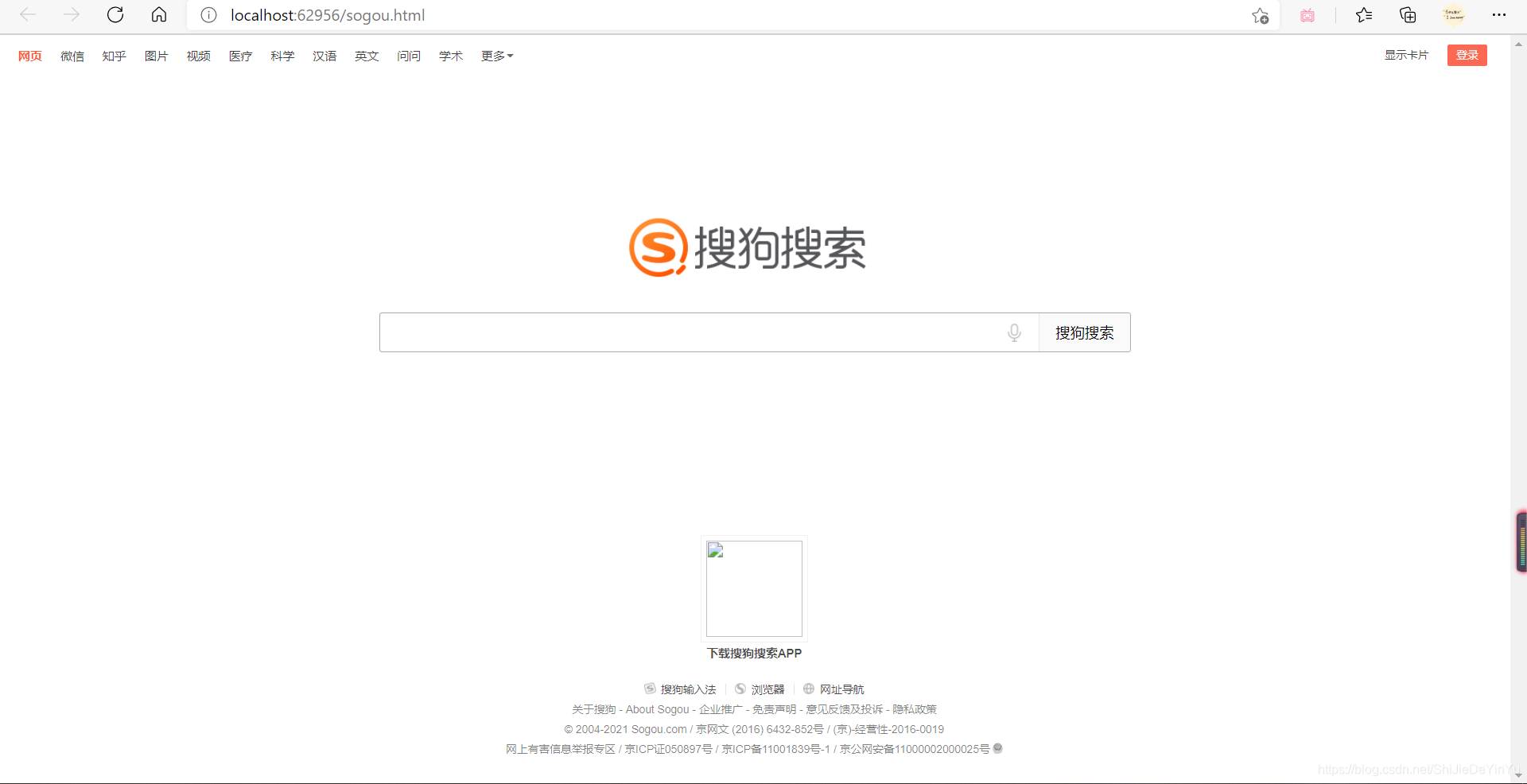
欧克,这就是最基本的爬取,如果学会了,那就试一试爬取 B站 的首页吧。
到此这篇关于Python爬虫基础之requestes模块的文章就介绍到这了,更多相关Python requestes模块内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python 图形绘制详细代码,文章主要从最简单图像的开始,在同一图上绘制两条或多条线一些简单操作,想了解的小伙伴可以学习一下,希望对你的学习有所帮助2021-12-12
这篇文章主要介绍了Python 图形绘制详细代码,文章主要从最简单图像的开始,在同一图上绘制两条或多条线一些简单操作,想了解的小伙伴可以学习一下,希望对你的学习有所帮助2021-12-12 使用Python处理PPT文件通常需要使用第三方库来简化对PPT文件的读取、写入和修改操作,本文将给大家介绍一个小案例,使用Python批量生成PPT版荣誉证书,感兴趣的同学跟着小编一起来看看吧2023-08-08
使用Python处理PPT文件通常需要使用第三方库来简化对PPT文件的读取、写入和修改操作,本文将给大家介绍一个小案例,使用Python批量生成PPT版荣誉证书,感兴趣的同学跟着小编一起来看看吧2023-08-08 这篇文章主要介绍了scrapy中如何设置应用cookies的方法(3种),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09
这篇文章主要介绍了scrapy中如何设置应用cookies的方法(3种),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09 字符串驻留机制是Python针对字符串对象采取的一种内存优化技术。其目标是减少内存使用并提高程序的性能。这篇文章主要介绍了字符串驻留机制的简单应用,需要的可以参考一下2023-04-04
字符串驻留机制是Python针对字符串对象采取的一种内存优化技术。其目标是减少内存使用并提高程序的性能。这篇文章主要介绍了字符串驻留机制的简单应用,需要的可以参考一下2023-04-04
python进阶教程之循环相关函数range、enumerate、zip
这篇文章主要介绍了python进阶教程之循环相关函数range、enumerate、zip,在使用循环程序经常要配合这些函数来完成循环,需要的朋友可以参考下2014-08-08 缺失值是指粗糙数据中由于缺少信息而造成的数据的聚类、分组、删失或截断,下面这篇文章主要给大家介绍了关于Python处理缺失值的8种不同方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-06-06
缺失值是指粗糙数据中由于缺少信息而造成的数据的聚类、分组、删失或截断,下面这篇文章主要给大家介绍了关于Python处理缺失值的8种不同方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-06-06 本文主要为没有使用正则表达式经验的新手入门所写。由浅入深介绍了Python 正则表达式,有需要的朋友可以看下2016-12-12
本文主要为没有使用正则表达式经验的新手入门所写。由浅入深介绍了Python 正则表达式,有需要的朋友可以看下2016-12-12
Python使用BeautifulSoup和Scrapy抓取网页数据的具体教程
在当今信息爆炸的时代,数据无处不在,如何有效地抓取、处理和分析这些数据成为了许多开发者和数据科学家的必修课,本篇博客将深入探讨如何使用Python中的两个强大工具:BeautifulSoup和Scrapy来抓取网页数据,需要的朋友可以参考下2025-01-01 网络设备配置备份与恢复在网络安全管理中起着至关重要的作用,本文为大家介绍了如何通过Python实现网络设备配置备份与恢复,需要的可以参考下2025-03-03
网络设备配置备份与恢复在网络安全管理中起着至关重要的作用,本文为大家介绍了如何通过Python实现网络设备配置备份与恢复,需要的可以参考下2025-03-03 PyTorch的torch.matmul是一个强大的矩阵乘法函数,支持不同维度张量的乘法运算,包括广播机制。提供了矩阵乘法的语法,参数说明,以及使用示例,帮助理解其应用方式和乘法规则2024-09-09
PyTorch的torch.matmul是一个强大的矩阵乘法函数,支持不同维度张量的乘法运算,包括广播机制。提供了矩阵乘法的语法,参数说明,以及使用示例,帮助理解其应用方式和乘法规则2024-09-09










最新评论