
python爬虫之bs4数据解析
更新时间:2021年04月26日 10:45:09 作者:世界的隐喻
这篇文章主要介绍了python爬虫之bs4数据解析,文中有非常详细的代码示例,对正在学习python爬虫的小伙伴们有非常好的帮助,需要的朋友可以参考下
一、实现数据解析
因为正则表达式本身有难度,所以在这里为大家介绍一下 bs4 实现数据解析。除此之外还有 xpath 解析。因为 xpath 不仅可以在 python 中使用,所以 bs4 和 正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义)。以后的重点会在 xpath 上。
二、安装库
闲话少说,我们先来安装 bs4 相关的外来库。比较简单。
1.首先打开 cmd 命令面板,依次安装bs4 和 lxml。
2. 命令分别是 pip install bs4 和 pip install lxml 。
3. 安装完成后我们可以试着调用他们,看看会不会报错。
因为本人水平有限,所以如果出现报错,兄弟们还是百度一下好啦。(总不至于 cmd 命令打错了吧 ~~)
三、bs4 的用法
闲话少说,先简单介绍一下 bs4 的用法。
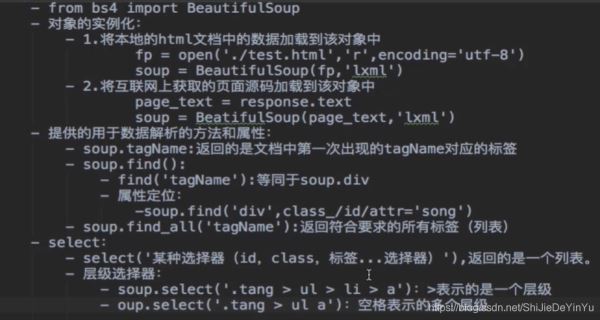

四、爬取图片
import requests
from bs4 import BeautifulSoup
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("./糗图(bs4)"):
os.mkdir("./糗图(bs4)")
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
for i in range(1, 3): # 翻两页
url = "https://www.qiushibaike.com/imgrank/page/%s/" % str(i)
# 获取源码数据
page = requests.get(url = url, headers = header).text
# 数据解析
soup = BeautifulSoup(page, "lxml")
data_list = soup.select(".thumb > a")
for data in data_list:
url = data.img["src"]
title = url.split("/")[-1]
new_url = "https:" + url
photo = requests.get(url = new_url, headers = header).content
# 存储
with open("./糗图(bs4)/" + title, "wb") as fp:
fp.write(photo)
print(title, "下载完成!!!")
print("over!!!")
五、爬取三国演义
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
# URL
url = "http://sanguo.5000yan.com/"
# 请求命令
page_text = requests.get(url = url, headers = header)
page_text.encoding = "utf-8"
page_text = page_text.text
soup = BeautifulSoup(page_text, "lxml")
# bs4 解析
li_list = soup.select(".sidamingzhu-list-mulu > ul > li")
for li in li_list:
print(li)
new_url = li.a["href"]
title = li.a.text
# 新的请求命令
response = requests.get(url = new_url, headers = header)
response.encoding = "utf-8"
new_page_text = response.text
new_soup = BeautifulSoup(new_page_text, "lxml")
page = new_soup.find("div", class_ = "grap").text
with open("./三国演义.txt", "a", encoding = "utf-8") as fp:
fp.write("\n" + title + ":" + "\n" + "\n" + page)
print(title + "下载完成!!!")
到此这篇关于python爬虫之bs4数据解析的文章就介绍到这了,更多相关python bs4数据解析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python sep参数使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python sep参数使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02 这篇文章主要给大家介绍了关于python nonlocal用法的相关资料,最近在python学习中遇到了nonlocal关键字但是感到困惑,于是记录nonlocal关键字用法,需要的朋友可以参考下2023-10-10
这篇文章主要给大家介绍了关于python nonlocal用法的相关资料,最近在python学习中遇到了nonlocal关键字但是感到困惑,于是记录nonlocal关键字用法,需要的朋友可以参考下2023-10-10
使用 Python 和 OpenCV 实现摄像头人脸检测并截图功能
在现代应用中,人脸检测是一项非常重要的技术,广泛应用于安全监控、身份验证等领域,本文详细介绍了如何使用 Python 和 OpenCV 库实现摄像头人脸检测并截图,并通过具体的代码示例展示了整个过程,感兴趣的朋友一起看看吧2024-11-11 这篇文章主要给大家分享Python Flask + Redis 程序的练习,准备一个Python文件,名字为 app.py 提供一个web服务,可以访问地址,返回一个Hello Container World!并且记录访问的次数,下面来看看有趣的练习过程吧2022-01-01
这篇文章主要给大家分享Python Flask + Redis 程序的练习,准备一个Python文件,名字为 app.py 提供一个web服务,可以访问地址,返回一个Hello Container World!并且记录访问的次数,下面来看看有趣的练习过程吧2022-01-01 这篇文章主要为大家详细介绍了Python如何利用docx模块实现快速操作word文件,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2022-09-09
这篇文章主要为大家详细介绍了Python如何利用docx模块实现快速操作word文件,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2022-09-09
点云地面点滤波(Cloth Simulation Filter, CSF)
这篇文章主要介绍了点云地面点滤波(Cloth Simulation Filter, CSF)“布料”滤波算法介绍,本文从基本思想到实现思路一步步给大家讲解的非常详细,需要的朋友可以参考下2021-08-08
在pytorch中为Module和Tensor指定GPU的例子
今天小编就为大家分享一篇在pytorch中为Module和Tensor指定GPU的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08 这篇文章主要介绍了python通过Seq2Seq实现闲聊机器人,文中有非常详细的代码示例,对正在学习python的小伙伴们有很好的帮助,需要的朋友可以参考下2021-04-04
这篇文章主要介绍了python通过Seq2Seq实现闲聊机器人,文中有非常详细的代码示例,对正在学习python的小伙伴们有很好的帮助,需要的朋友可以参考下2021-04-04 这篇文章主要介绍了Python桌面文件清理脚本,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11
这篇文章主要介绍了Python桌面文件清理脚本,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11 这篇文章主要介绍了Python爬虫爬取电影票房数据及图表展示操作,结合实例形式分析了Python爬虫爬取、解析电影票房数据并进行图表展示操作相关实现技巧,需要的朋友可以参考下2020-03-03
这篇文章主要介绍了Python爬虫爬取电影票房数据及图表展示操作,结合实例形式分析了Python爬虫爬取、解析电影票房数据并进行图表展示操作相关实现技巧,需要的朋友可以参考下2020-03-03










最新评论