
python爬虫之selenium库的安装及使用教程
更新时间:2021年05月23日 15:02:23 作者:念惟忆
今天带大家来学习怎么安装使用selenium库,文中有非常详细的图文介绍,对正在学习python爬虫的小伙伴们很有帮助,需要的朋友可以参考下
第一步:python中安装selenium库
和其他所有Python库一样,selenium库需要安装
pip install selenium # Windows电脑安装selenium pip3 install selenium # Mac电脑安装selenium
第二步:下载谷歌浏览器驱动并合理放置
selenium的脚本可以控制所有常见浏览器,在使用之前需要安装浏览器端的驱动
注意:驱动和浏览器要版本对应
推荐使用Chrome浏览器:谷歌浏览器驱动
打开chrome浏览器,在网址栏中输入chrome://version/打开关于版本页面,根据版本信息下载相应chrome驱动

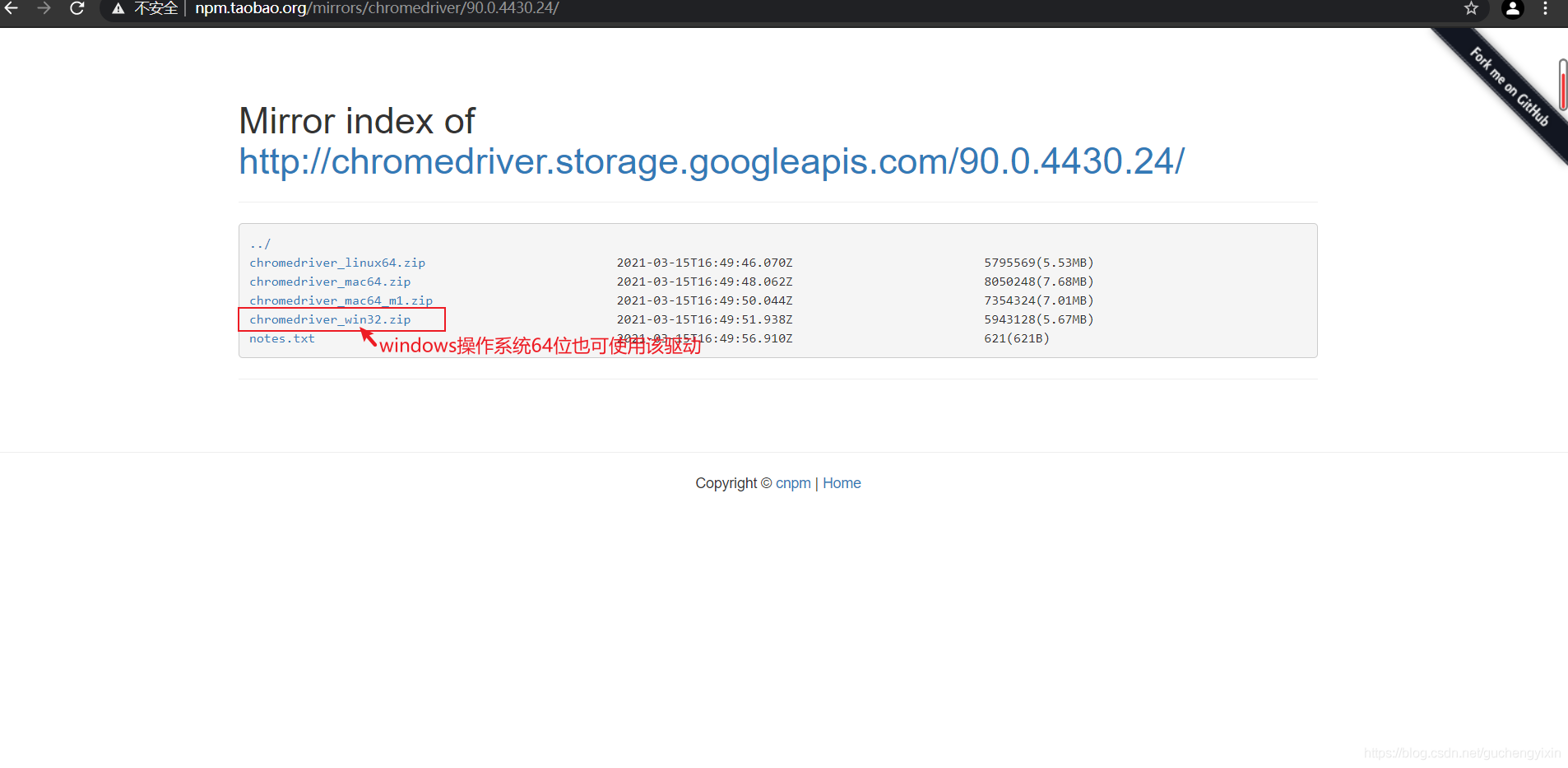
将驱动放在python的安装目录(我的python集成在Anaconda3)

第三步:使用selenium爬取QQ音乐歌词(简单示例)
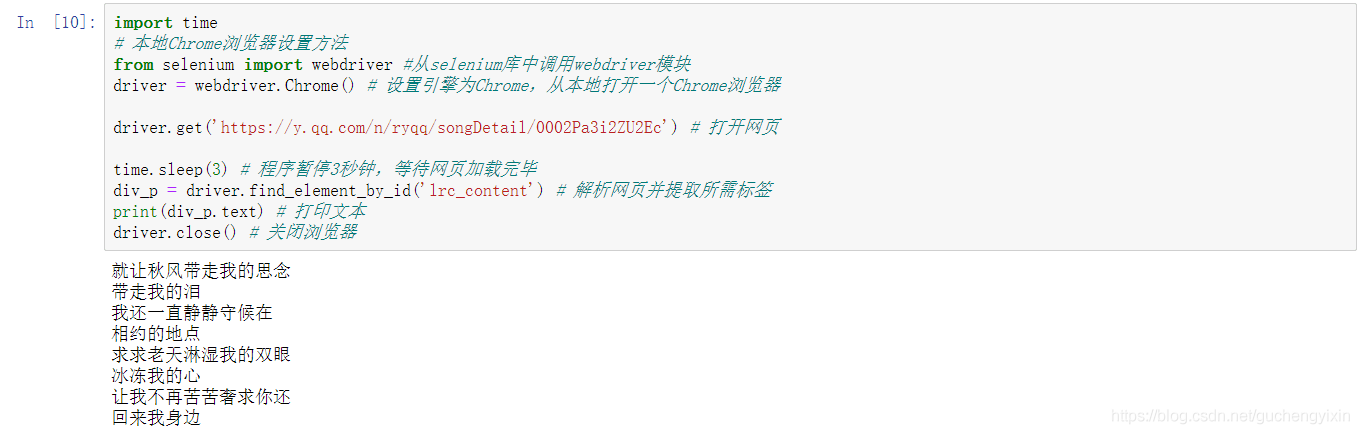
import time
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,从本地打开一个Chrome浏览器
driver.get('https://y.qq.com/n/ryqq/songDetail/0002Pa3i2ZU2Ec') # 打开网页
time.sleep(3) # 程序暂停3秒钟,等待网页加载完毕
div_p = driver.find_element_by_id('lrc_content') # 解析网页并提取所需标签
print(div_p.text) # 打印文本
driver.close() # 关闭浏览器

到此这篇关于python爬虫之selenium库的安装及使用教程的文章就介绍到这了,更多相关selenium库的安装使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python探索之ModelForm代码详解,具有一定参考价值,需要的朋友可以了解下。2017-10-10
这篇文章主要介绍了Python探索之ModelForm代码详解,具有一定参考价值,需要的朋友可以了解下。2017-10-10 这篇文章主要介绍了Python中安装easy_install的方法,需要的朋友可以参考下2018-11-11
这篇文章主要介绍了Python中安装easy_install的方法,需要的朋友可以参考下2018-11-11 这篇文章主要介绍了Python将多个图像合并输出的实现方法,本文介绍了两种将多个图像合并为一个输出的方法:使用PIL库或使用OpenCV和NumPy,这些库都可以使用Python中的简单语法和少量的代码来完成此任务,需要的朋友可以参考下2023-06-06
这篇文章主要介绍了Python将多个图像合并输出的实现方法,本文介绍了两种将多个图像合并为一个输出的方法:使用PIL库或使用OpenCV和NumPy,这些库都可以使用Python中的简单语法和少量的代码来完成此任务,需要的朋友可以参考下2023-06-06 这篇文章主要为大家介绍了如何利用Python中的Pygame模块实现英文版猜单词游戏,文中的示例代码讲解详细,对我们学习Python游戏开发有一定帮助,需要的可以参考一下2022-08-08
这篇文章主要为大家介绍了如何利用Python中的Pygame模块实现英文版猜单词游戏,文中的示例代码讲解详细,对我们学习Python游戏开发有一定帮助,需要的可以参考一下2022-08-08 这篇文章主要介绍了Python常见工厂函数用法,简单描述了工厂函数的功能、定义并结合具体实例形式分析了Python常见工厂函数的相关使用技巧,需要的朋友可以参考下2018-03-03
这篇文章主要介绍了Python常见工厂函数用法,简单描述了工厂函数的功能、定义并结合具体实例形式分析了Python常见工厂函数的相关使用技巧,需要的朋友可以参考下2018-03-03 今天下午想要复现一下学长的recursion file,想模仿源码里的精髓:迭代器遇到了bug,花了一两个小时才解决。现总结如下,有需要的朋友也可借鉴参考下2021-09-09
今天下午想要复现一下学长的recursion file,想模仿源码里的精髓:迭代器遇到了bug,花了一两个小时才解决。现总结如下,有需要的朋友也可借鉴参考下2021-09-09
Python在centos7.6上安装python3.9的详细教程(默认python版本为2.7.5)
这篇文章主要介绍了Python在centos7.6上安装python3.9(默认python版本为2.7.5)的方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2020-10-10 在前面一篇文章中,我们对pandas做了一些入门介绍。本文是它的进阶篇。在这篇文章中,我们会讲解一些更深入的知识2018-04-04
在前面一篇文章中,我们对pandas做了一些入门介绍。本文是它的进阶篇。在这篇文章中,我们会讲解一些更深入的知识2018-04-04
Python3使用requests包抓取并保存网页源码的方法
这篇文章主要介绍了Python3使用requests包抓取并保存网页源码的方法,实例分析了Python3环境下requests模块的相关使用技巧,需要的朋友可以参考下2016-03-03 今天小编就为大家分享一篇关于Python字符串逆序输出的实例讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-02-02
今天小编就为大家分享一篇关于Python字符串逆序输出的实例讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-02-02










最新评论