
单身狗福利?Python爬取某婚恋网征婚数据
更新时间:2021年06月03日 17:02:38 作者:武亮宇
今天我就当回媒婆,给男性程序员来点福利.今天目标爬取征婚网上呈现出来的女生信息保存成excel表格供大家筛选心仪的女生,需要的朋友可以参考下
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1
一、打开界面

鼠标右键打开检查,方框里为你一个文小姐的征婚信息。。由此判断出为同步加载

点击elements,定位图片地址,方框里为该女士的url地址及图片地址
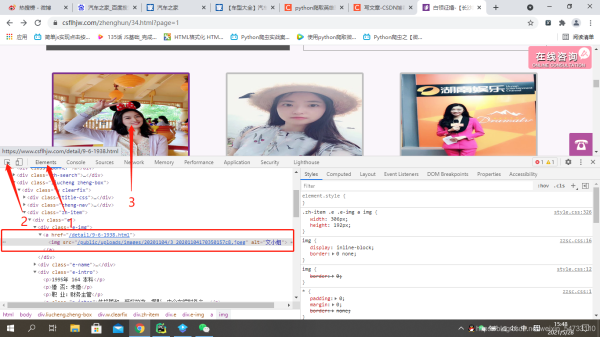
可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化
点击第2页
https://www.csflhjw.com/zhenghun/34.html?page=2
点击第3页
https://www.csflhjw.com/zhenghun/34.html?page=3
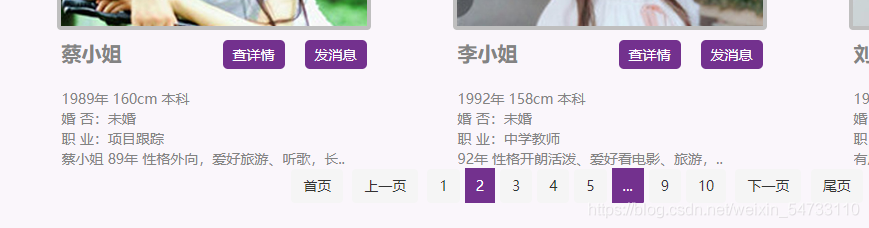
可以看出变化在最后
做一下fou循环格式化输出一下。。一共10页
二、代码解析
1.获取所有的女士的url,xpath的路径就不详细说了。。

2.构造每一位女士的url地址

3.然后点开一位女士的url地址,用同样的方法,确定也为同步加载

4.之后就是女士url地址html的xpath提取,每个都打印一下,把不要的过滤一下

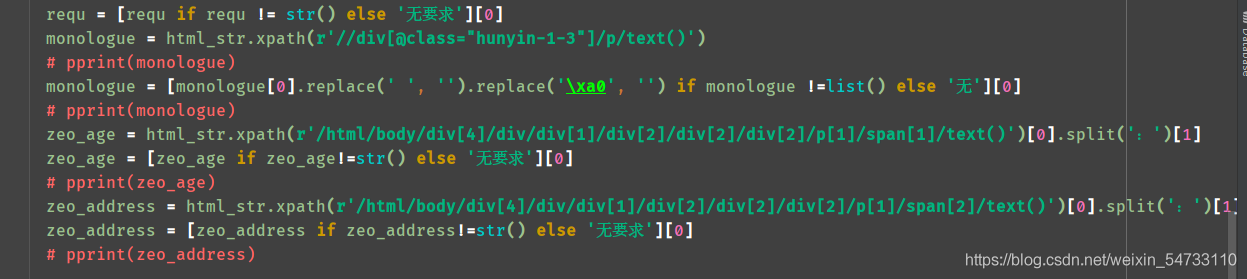
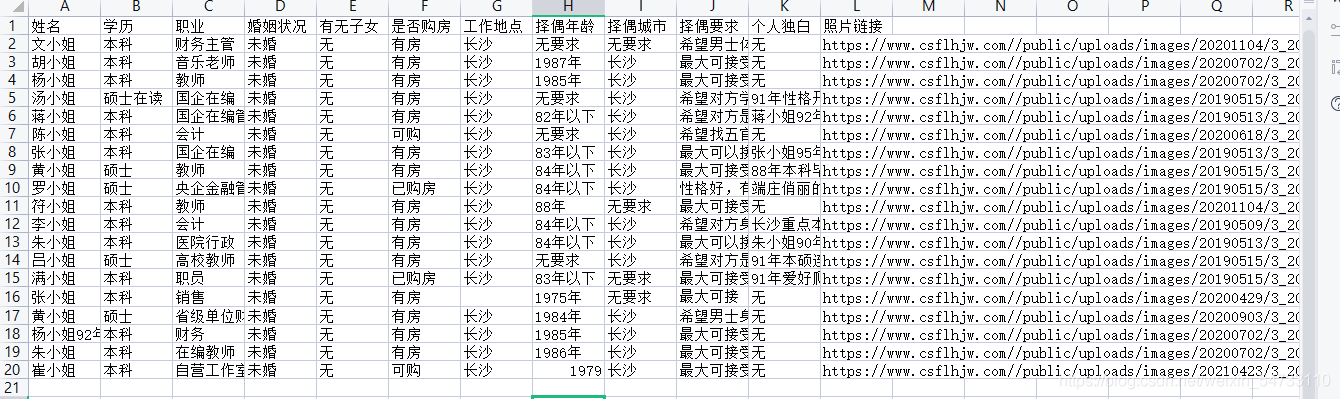
5.最后就是文件的保存
打印结果:
三、完整代码
# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, csv
from pprint import pprint
from lxml import etree
def main():
for i in range(1, 11):
start_url = 'https://www.csflhjw.com/zhenghun/34.html?page={}'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(start_url, headers=headers).content.decode()
# # pprint(response)
# 3 解析数据
html_str = etree.HTML(response)
info_urls = html_str.xpath(r'//div[@class="e"]/div[@class="e-img"]/a/@href')
# pprint(info_urls)
# 4、循环遍历 构造img_info_url
for info_url in info_urls:
info_url = r'https://www.csflhjw.com' + info_url
# print(info_url)
# 5、对info_url发请求,解析得到img_urls
response = requests.get(info_url, headers=headers).content.decode()
html_str = etree.HTML(response)
# pprint(html_str)
img_url = 'https://www.csflhjw.com/' + html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[1]/div['
r'1]/img/@src')[0]
# pprint(img_url)
name = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/h2/text()')[0]
# pprint(name)
xueli = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[1]/text()')[0].split(':')[1]
# pprint(xueli)
job = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[2]/text()')[0].split(':')[1]
# pprint(job)
marital_status = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[3]/text()')[0].split(
':')[1]
# pprint(marital_status)
is_child = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[4]/text()')[0].split(':')[1]
# pprint(is_child)
home = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[5]/text()')[0].split(':')[1]
# pprint(home)
workplace = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[6]/text()')[0].split(':')[1]
# pprint(workplace)
requ = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[2]/span/text()')[0].split(':')[1]
# pprint(requ)
requ = [requ if requ != str() else '无要求'][0]
monologue = html_str.xpath(r'//div[@class="hunyin-1-3"]/p/text()')
# pprint(monologue)
monologue = [monologue[0].replace(' ', '').replace('\xa0', '') if monologue !=list() else '无'][0]
# pprint(monologue)
zeo_age = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[1]/text()')[0].split(':')[1]
zeo_age = [zeo_age if zeo_age!=str() else '无要求'][0]
# pprint(zeo_age)
zeo_address = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[2]/text()')[0].split(':')[1]
zeo_address = [zeo_address if zeo_address!=str() else '无要求'][0]
# pprint(zeo_address)
if not os.path.exists(r'./{}'.format('妹子信息数据')):
os.mkdir(r'./{}'.format('妹子信息数据'))
csv_header = ['姓名', '学历', '职业', '婚姻状况', '有无子女', '是否购房', '工作地点', '择偶年龄', '择偶城市', '择偶要求', '个人独白', '照片链接']
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'w', newline='', encoding='gbk') as file_csv:
csv_writer_header = csv.DictWriter(file_csv, csv_header)
csv_writer_header.writeheader()
try:
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'a+', newline='',
encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息数据:{}'.format(name))
except Exception as e:
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'a+', newline='',
encoding='utf-8') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息数据保存成功:{}'.format(name))
if __name__ == '__main__':
main()
到此这篇关于单身狗福利?Python爬取某婚恋网征婚数据的文章就介绍到这了,更多相关Python爬取征婚数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了将Python的Django框架与认证系统整合的方法,包括指定认证后台和编写认证后台等内容,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了将Python的Django框架与认证系统整合的方法,包括指定认证后台和编写认证后台等内容,需要的朋友可以参考下2015-07-07 大家好,本篇文章主要讲的是Python进制转换用法详解,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下2022-01-01
大家好,本篇文章主要讲的是Python进制转换用法详解,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下2022-01-01 今天小编就为大家分享一篇python调用staf自动化框架的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇python调用staf自动化框架的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 这篇文章主要介绍了Python 数据可视化pyecharts的使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-06-06
这篇文章主要介绍了Python 数据可视化pyecharts的使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-06-06 这篇文章主要为大家介绍了Python如何对接文心一言的操作实例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01
这篇文章主要为大家介绍了Python如何对接文心一言的操作实例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01 这篇文章主要为大家介绍了Python GUI布局工具Tkinter的基础,Tkinter 作为 Python 的标准库,是非常流行的 Python GUI 工具,同时也是非常容易学习的,今天我们就来开启 Tkinter的入门之旅2022-08-08
这篇文章主要为大家介绍了Python GUI布局工具Tkinter的基础,Tkinter 作为 Python 的标准库,是非常流行的 Python GUI 工具,同时也是非常容易学习的,今天我们就来开启 Tkinter的入门之旅2022-08-08
Python Setuptools的 setup.py实例详解
setup.py是一个 python 文件,它的存在表明您要安装的模块/包可能已经用 Setuptools 打包和分发,这是分发 Python 模块的标准。 它的目的是正确安装软件,本文给大家讲解Python Setuptools的 setup.py感兴趣的朋友跟随小编一起看看吧2022-12-12
解决新版Pycharm中Matplotlib图像不在弹出独立的显示窗口问题
今天小编就为大家分享一篇解决新版Pycharm中Matplotlib图像不在弹出独立的显示窗口问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 下面小编就为大家带来一篇python 把数据 json格式输出的实例代码。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-10-10
下面小编就为大家带来一篇python 把数据 json格式输出的实例代码。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-10-10 下面小编就为大家带来一篇python字典键值对的添加和遍历方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-09-09
下面小编就为大家带来一篇python字典键值对的添加和遍历方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-09-09










最新评论