
python中pandas对多列进行分组统计的实现
更新时间:2021年06月18日 16:02:01 作者:光于前裕于后
分组统计在很多时候都需要用到,可以实现很多数据库函数的功能。本文主要介绍了python中pandas对多列进行分组统计的实现,感兴趣的可以了解一下
使用groupby([ ]).size()统计的结果,值相同的字段值会不显示
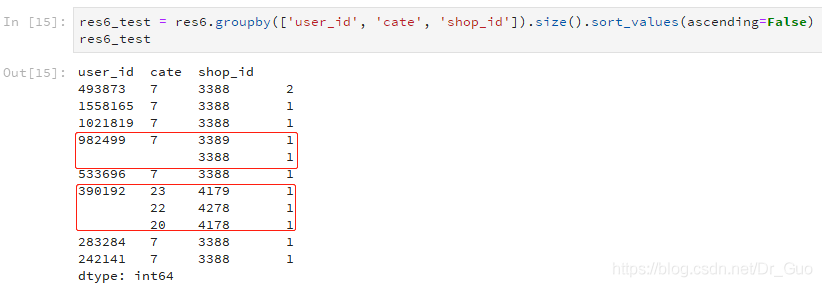
如上图所示,第一个空着的行是982499 7 3388 1,因为此行与前面一行的这两个字段值是一样的,所以不显示。第二个空着的行是390192 22 4278 1,因为此行与前面一行的第一个字段值是一样的,所以不显示。这样的展示方式更直观,但对于刚用的人,可能会让其以为是缺失值。
如果还不明白可以看下面的全部数据及操作。
import pandas as pd
res6 = pd.read_csv('test.csv')
res6.shape
(12, 3)
res6.columns
Index(['user_id', 'cate', 'shop_id'], dtype='object')
res6.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 12 entries, 0 to 11 Data columns (total 3 columns): user_id 12 non-null int64 cate 12 non-null int64 shop_id 12 non-null int64 dtypes: int64(3) memory usage: 368.0 bytes
res6.describe()
| user_id | cate | shop_id | |
|---|---|---|---|
| count | 1.200000e+01 | 12.000000 | 12.000000 |
| mean | 6.468688e+05 | 10.666667 | 3594.000000 |
| std | 3.988181e+05 | 6.665151 | 373.271775 |
| min | 2.421410e+05 | 7.000000 | 3388.000000 |
| 25% | 3.901920e+05 | 7.000000 | 3388.000000 |
| 50% | 4.938730e+05 | 7.000000 | 3388.000000 |
| 75% | 9.824990e+05 | 10.250000 | 3586.250000 |
| max | 1.558165e+06 | 23.000000 | 4278.000000 |
res6
| user_id | cate | shop_id | |
|---|---|---|---|
| 0 | 390192 | 20 | 4178 |
| 1 | 390192 | 23 | 4179 |
| 2 | 390192 | 22 | 4278 |
| 3 | 1021819 | 7 | 3388 |
| 4 | 242141 | 7 | 3388 |
| 5 | 283284 | 7 | 3388 |
| 6 | 1558165 | 7 | 3388 |
| 7 | 533696 | 7 | 3388 |
| 8 | 982499 | 7 | 3388 |
| 9 | 493873 | 7 | 3388 |
| 10 | 493873 | 7 | 3388 |
| 11 | 982499 | 7 | 3389 |
res6['user_id'].value_counts()
390192 3 982499 2 493873 2 242141 1 1021819 1 533696 1 1558165 1 283284 1 Name: user_id, dtype: int64
res6.groupby(['user_id']).size().sort_values(ascending=False)
user_id 390192 3 982499 2 493873 2 1558165 1 1021819 1 533696 1 283284 1 242141 1 dtype: int64
res6.groupby(['user_id', 'cate']).size().sort_values(ascending=False)
user_id cate
982499 7 2
493873 7 2
1558165 7 1
1021819 7 1
533696 7 1
390192 23 1
22 1
20 1
283284 7 1
242141 7 1
dtype: int64
res6_test = res6.groupby(['user_id', 'cate', 'shop_id']).size().sort_values(ascending=False) res6_test
user_id cate shop_id
493873 7 3388 2
1558165 7 3388 1
1021819 7 3388 1
982499 7 3389 1
3388 1
533696 7 3388 1
390192 23 4179 1
22 4278 1
20 4178 1
283284 7 3388 1
242141 7 3388 1
dtype: int64
到此这篇关于python中pandas对多列进行分组统计的实现的文章就介绍到这了,更多相关pandas多列分组统计内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

解决python将xml格式文件转换成txt文件的问题(xml.etree方法)
从数据分析的角度去看xml格式的数据集,具有简单性,结构和内容分离、可扩展性的特征,今天通过本文给大家分享python将xml格式文件转换成txt文件的问题及解决方法(xml.etree方法),感兴趣的朋友一起看看吧2021-09-09 本文通过实例代码给大家介绍了Python用for循环实现九九乘法表的方法,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2018-05-05
本文通过实例代码给大家介绍了Python用for循环实现九九乘法表的方法,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2018-05-05 这篇文章主要介绍了Python爬取YY评级分数并保存数据实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了Python爬取YY评级分数并保存数据实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06 接触python有一段时间了,一直没有系统的学习过,也对copy,deepcoy傻傻的分不清,故抽出时间来理一下。 下面这篇文章主要给大家介绍了关于python中copy()与deepcopy()的区别的相关资料,需要的朋友可以参考下2018-08-08
接触python有一段时间了,一直没有系统的学习过,也对copy,deepcoy傻傻的分不清,故抽出时间来理一下。 下面这篇文章主要给大家介绍了关于python中copy()与deepcopy()的区别的相关资料,需要的朋友可以参考下2018-08-08 这篇文章主要介绍了python使用nb_log模块捕获日志,文中给大家介绍了nb_log模块的使用方式,本文给大家介绍的非常详细,需要的朋友可以参考下2021-12-12
这篇文章主要介绍了python使用nb_log模块捕获日志,文中给大家介绍了nb_log模块的使用方式,本文给大家介绍的非常详细,需要的朋友可以参考下2021-12-12 这篇文章主要介绍了简单了解python调用其他脚本方法实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-03-03
这篇文章主要介绍了简单了解python调用其他脚本方法实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-03-03 这篇文章主要介绍了Python初识逻辑与if语句,文中给大家提到了if语句功能及用法讲解,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了Python初识逻辑与if语句,文中给大家提到了if语句功能及用法讲解,需要的朋友可以参考下2021-08-08 这篇文章主要介绍了Python安装tar.gz格式文件方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-01-01
这篇文章主要介绍了Python安装tar.gz格式文件方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-01-01 在日常工作中,除了会涉及到使用Python处理文本文件,有时候还会涉及对压缩文件的处理。本文为大家总结了利用Python可以实现的几种文件压缩与解压缩实现代码,需要的可以参考一下2022-03-03
在日常工作中,除了会涉及到使用Python处理文本文件,有时候还会涉及对压缩文件的处理。本文为大家总结了利用Python可以实现的几种文件压缩与解压缩实现代码,需要的可以参考一下2022-03-03
Python使用Selenium获取Web页面信息的流程步骤
在 Web 自动化测试和数据抓取中,获取页面信息是一个基本且重要的操作,通过 Selenium,您可以轻松地获取页面的各种信息,这些信息不仅可以用于验证测试结果,还可以用于数据分析和处理,所以本文给大家介绍了Python使用Selenium获取Web页面信息的流程步骤2025-03-03










最新评论