
Pandas中的 transform()结合 groupby()用法示例详解
首先,假设我们有如下餐厅数据集:
import pandas as pd
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]
})
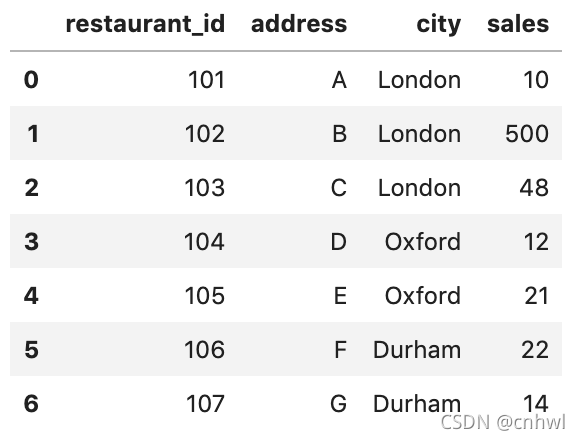
如果我们想知道:每个餐厅在城市中所占的销售额百分比是多少?预期得到的输出是:

相比于原来的数据集,多了两列,分别是某个城市所有餐厅的销售总额,以及每个餐厅在城市中所占的销售额百分比。解决方案有两个:
方案一(较麻烦):
1、使用 groupby('city') 基于城市进行分组,对于这些组中的每一个组,选中其销售额列 ['sales'],然后使用函数 apply(sum) 或者sum() 对城市的销售额进行求和。
之后,新列被重命名为 city_total_sales 并且索引被重置(注意不能漏了 reset_index() ,因为 groupby('city') 生成的索引是城市,而我们希望城市作为普通列)。
city_sales = df.groupby('city')['sales']
.sum().rename('city_total_sales').reset_index()
得到的 city_sales 如下:

2、用 merge() 函数把 city_sales 合并回去,得到的 df_new 如下:
df_new = pd.merge(df, city_sales, how='left')

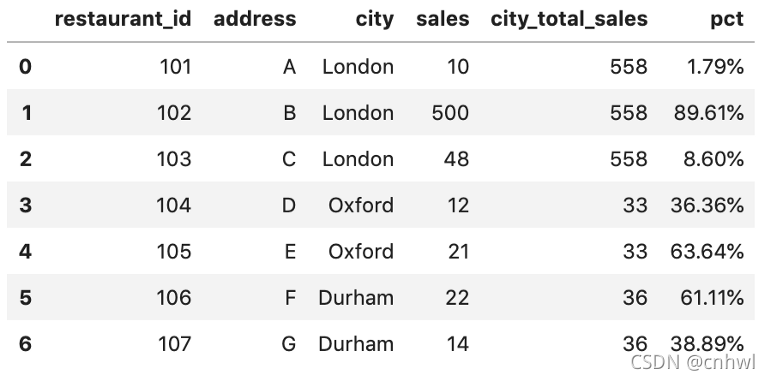
3、最后,求百分比并保留两位小数,结果如下:
df_new['pct'] = df_new['sales'] / df_new['city_total_sales'] df_new['pct'] = df_new['pct'].apply(lambda x: format(x, '.2%'))
方案二(便捷):
1、
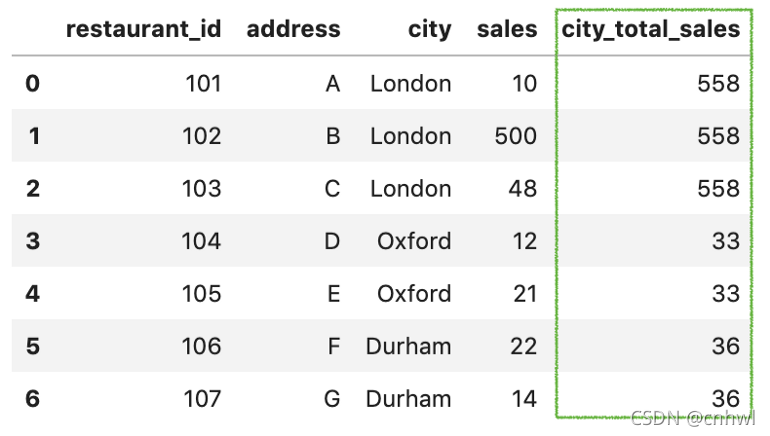
transform() 函数在执行转换后保留与原始数据集相同数量的项目。因此,使用 groupby() 然后使用 transform(sum) 会返回相同的输出,结果如下图:
df['city_total_sales'] = df.groupby('city')['sales']
.transform('sum')
代码翻译过来就是:数据集基于城市进行分组,然后选定销售额列,对每组的销售额进行求和,返回一个和原列长度一样的新列。
2、
与方案一相同。
df['pct'] = df['sales'] / df['city_total_sales'] df['pct'] = df['pct'].apply(lambda x: format(x, '.2%'))
总结:可以看出,在对 DataFrame 进行分组 groupby() 之后,如果是使用 apply() 或者直接使用某个统计函数,得到的新列的长度与分组得到的组数是一样的;而如果使用 transform() ,得到的新列与 DataFrame 中列的长度是一样的。
到此这篇关于Pandas中的 transform()结合 groupby()用法示例详解的文章就介绍到这了,更多相关Pandas groupby() 用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python常见模块与用法,文中有非常详细的代码示例,对正在学习python的小伙伴们有一定的帮助,需要的朋友可以参考下2021-04-04
这篇文章主要介绍了python常见模块与用法,文中有非常详细的代码示例,对正在学习python的小伙伴们有一定的帮助,需要的朋友可以参考下2021-04-04 这篇文章主要介绍了Python+Opencv身份证号码区域提取及识别实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08
这篇文章主要介绍了Python+Opencv身份证号码区域提取及识别实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08 今天小编就为大家分享一篇Python PIL图片添加字体的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08
今天小编就为大家分享一篇Python PIL图片添加字体的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08
Pandas数据结构详细说明及如何创建Series,DataFrame对象方法
本篇文章中,我们主要侧重于介绍Pandas数据结构本身的特性,以及如何创建一个Series或者DataFrame数据对象,并填入一些数据2021-10-10 这篇文章主要介绍了Python3实现二叉树的最大深度, 文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-09-09
这篇文章主要介绍了Python3实现二叉树的最大深度, 文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-09-09 这篇文章主要介绍了Python中def的用法以及def是什么意思的相关资料,文中介绍了Python中函数的定义和使用方法,还给出了详细的代码示例,需要的朋友可以参考下2024-10-10
这篇文章主要介绍了Python中def的用法以及def是什么意思的相关资料,文中介绍了Python中函数的定义和使用方法,还给出了详细的代码示例,需要的朋友可以参考下2024-10-10 这篇文章主要介绍了python中字典的常见操作总结,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-07-07
这篇文章主要介绍了python中字典的常见操作总结,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-07-07 这篇文章主要介绍了Python之维度dim的定义及其理解使用方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了Python之维度dim的定义及其理解使用方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要介绍了详解Python的Django框架中的Cookie相关处理,Cookie存储是每个开发框架都会着重注意的重要功能,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了详解Python的Django框架中的Cookie相关处理,Cookie存储是每个开发框架都会着重注意的重要功能,需要的朋友可以参考下2015-07-07 这篇文章主要介绍了关于PyTorch中nn.Module类的简介,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了关于PyTorch中nn.Module类的简介,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02










最新评论