
Python爬虫实战之网易云音乐加密解析附源码
更新时间:2021年10月15日 08:51:36 作者:松鼠爱吃饼干
读万卷书不如行万里路,学的扎不扎实要通过实战才能看出来,本篇文章手把手带你解析网易云音乐数据,大家可以在实战过程中更有效的掌握python
环境
- python3.8
- pycharm2021.2
知识点
- requests >>> pip install requests
- execjs >>> pip install PyExecJS
第一步
打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id
去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
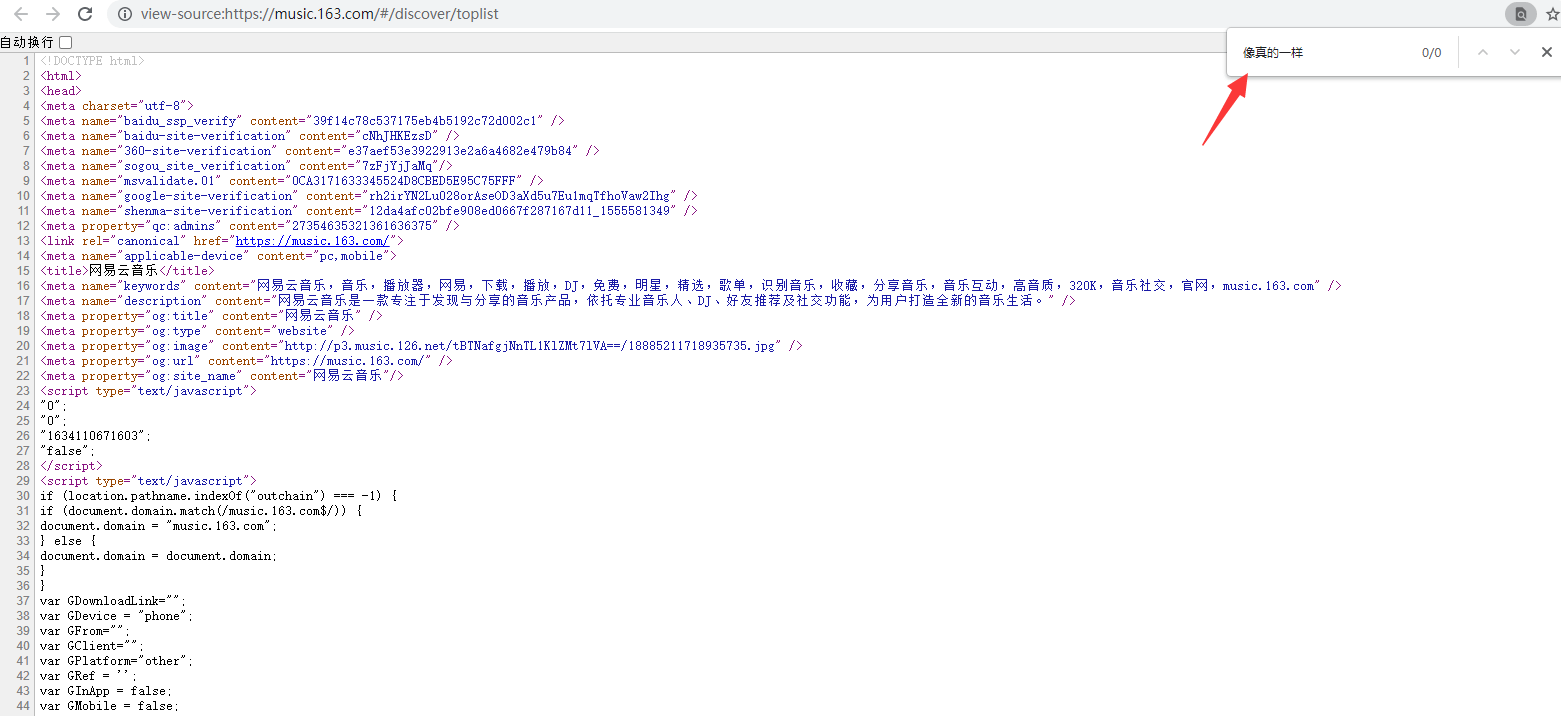
打开开发者工具,找到歌曲的id

找到真正的目标网址https://music.163.com/discover/toplist
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
第二步
通过代码去实现当前这一个步骤
- 通过代码去访问当这个页面 – 拿到网页源代码
- 提取我们真正想要的 音乐的名称 id
- 下载音乐: id获取是为了下载音乐分析里面音乐数据的 加密规则 去下载歌曲
开始代码
先导入所需模块
import requests import re import execjs
请求数据
# 通过代码去访问当这个页面 -- 拿到网页源代码
url = 'https://music.163.com/discover/toplist'
# 伪装
headers = {
'cookie': '_ntes_nuid=063717de540d3ec18d9b4a0bdf51e931; WM_TID=sxztjH%2FJbYZBEREFBQZvAgttUnJPrvYf; ntes_kaola_ad=1; NMTID=00OSBNvfChgV2TD7k5IhSzky6R8lXgAAAF0zoWmoA; _ntes_nnid=063717de540d3ec18d9b4a0bdf51e931,1607344992641; _iuqxldmzr_=32; OUTFOX_SEARCH_USER_ID_NCOO=2145381542.3273497; WEVNSM=1.0.0; WNMCID=sazafu.1624080681192.01.0; UM_distinctid=17b784cb58a17-097be09ee87fb9-c343365-1aeaa0-17b784cb58b8bc; __root_domain_v=.163.com; _qddaz=QD.159230735652240; vinfo_n_f_l_n3=11aae7905aa2179b.1.11.1575470964063.1625470009945.1632894007779; usertrack=ezq0J2FlcQWNYypxAx88Ag==; JSESSIONID-WYYY=Yvm62%5Cnd8XNkT2ryCNOJx9urqXsxCDMF6srNnGRegtmuNdB5MrrS9ou%2FWw3JbVf960uHnGW3Bb%2Fbhv2xZm3Vn%2B%2BonZSX38sqKiUMuRd6TDKD39HRzGmrZ%5Cp9IUaNs%5C5nYt9xltJBt5qRgWsl0PZsxDhSu26ugGAozPffXXAjemm0o%2Fv%5C%3A1634111694844; WM_NI=au9XpuutN3GwymEoZsAgWl6%2BH4cTcHgYKos%2BWibR3hSntTQhrpX%2FLoCAycOKLnZteLb1LlluoIk9jlKxaaUThS4tfZr9jWB3LVjXKQUH4%2BMpukbEPcnHaN80J8%2FhoqeeYms%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee8de74b85b18eb3b27bae8e8ab2d44e969f9aafae3388af8f98d06da59b968ecf2af0fea7c3b92aa3abf7b9f37fb7ac82d4c67dbbb38b90d97983b9998db5218cecadb5e244a5878590f22195b7aeb3b26491b2bcb5d464b2b098d0cf65819fb784ce4190b29695e848a2ef848def7fad97a5dae96889a8af82d860ac8dfc95e552b2e7a6b8c139908aa6b9ca5b9798fcccd07cb7b5aea6d369ae98afafbb3c8ae8e189ee7ba7bb978ef237e2a3; playerid=29374327',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# url: 分析出来的真正数据链接
# headers: 伪装请求头
response = requests.get(url, headers).text
# <Response [200]>: 告诉你访问成功了
提取我们真正想要的 音乐的名称 id
zip_data = re.findall('<li><a href="/song\?id=(.*?)" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>', response)
for music_id, title in zip_data:
# url_1 = 'http://music.163.com/song/media/outer/url?id=' + music_id
url_1 = 'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token='
result = ctx.call('start', music_id)
data = {
'params': result['encText'],
'encSecKey': result['encSecKey']
}
# 发送请求
# 当前的音乐数据
music_url = requests.post(url_1, data=data, headers=headers).json()['data'][0]['url']
music_data = requests.get(music_url, headers).content
title = re.sub(r'[/\\:*?"<>|]', '_', title)
导入js文件
# js文件导入
js = open('music163.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(js)
保存文件
with open('music/' + title + '.mp3', mode='wb') as f:
f.write(music_data)
print(title)

完整代码
import requests
import re
import execjs
url = 'https://music.163.com/discover/toplist'
# 伪装
headers = {
'cookie': '_ntes_nuid=063717de540d3ec18d9b4a0bdf51e931; WM_TID=sxztjH%2FJbYZBEREFBQZvAgttUnJPrvYf; ntes_kaola_ad=1; NMTID=00OSBNvfChgV2TD7k5IhSzky6R8lXgAAAF0zoWmoA; _ntes_nnid=063717de540d3ec18d9b4a0bdf51e931,1607344992641; _iuqxldmzr_=32; OUTFOX_SEARCH_USER_ID_NCOO=2145381542.3273497; WEVNSM=1.0.0; WNMCID=sazafu.1624080681192.01.0; UM_distinctid=17b784cb58a17-097be09ee87fb9-c343365-1aeaa0-17b784cb58b8bc; __root_domain_v=.163.com; _qddaz=QD.159230735652240; vinfo_n_f_l_n3=11aae7905aa2179b.1.11.1575470964063.1625470009945.1632894007779; usertrack=ezq0J2FlcQWNYypxAx88Ag==; JSESSIONID-WYYY=Yvm62%5Cnd8XNkT2ryCNOJx9urqXsxCDMF6srNnGRegtmuNdB5MrrS9ou%2FWw3JbVf960uHnGW3Bb%2Fbhv2xZm3Vn%2B%2BonZSX38sqKiUMuRd6TDKD39HRzGmrZ%5Cp9IUaNs%5C5nYt9xltJBt5qRgWsl0PZsxDhSu26ugGAozPffXXAjemm0o%2Fv%5C%3A1634111694844; WM_NI=au9XpuutN3GwymEoZsAgWl6%2BH4cTcHgYKos%2BWibR3hSntTQhrpX%2FLoCAycOKLnZteLb1LlluoIk9jlKxaaUThS4tfZr9jWB3LVjXKQUH4%2BMpukbEPcnHaN80J8%2FhoqeeYms%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee8de74b85b18eb3b27bae8e8ab2d44e969f9aafae3388af8f98d06da59b968ecf2af0fea7c3b92aa3abf7b9f37fb7ac82d4c67dbbb38b90d97983b9998db5218cecadb5e244a5878590f22195b7aeb3b26491b2bcb5d464b2b098d0cf65819fb784ce4190b29695e848a2ef848def7fad97a5dae96889a8af82d860ac8dfc95e552b2e7a6b8c139908aa6b9ca5b9798fcccd07cb7b5aea6d369ae98afafbb3c8ae8e189ee7ba7bb978ef237e2a3; playerid=29374327',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url, headers).text
zip_data = re.findall('<li><a href="/song\?id=(.*?)" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>', response)
js = open('music163.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(js)
for music_id, title in zip_data:
url_1 = 'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token='
result = ctx.call('start', music_id)
data = {
'params': result['encText'],
'encSecKey': result['encSecKey']
}
music_url = requests.post(url_1, data=data, headers=headers).json()['data'][0]['url']
music_data = requests.get(music_url, headers).content
title = re.sub(r'[/\\:*?"<>|]', '_', title)
with open('music/' + title + '.mp3', mode='wb') as f:
f.write(music_data)
print(title)
到此这篇关于Python爬虫实战之网易云音乐加密解析附源码的文章就介绍到这了,更多相关Python 网易云音乐解析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇python 输入一个数n,求n个数求乘或求和的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-11-11
今天小编就为大家分享一篇python 输入一个数n,求n个数求乘或求和的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-11-11 urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。他以urlopen函数的形式提供了一个非常简单的接口,下面我们用实例讲解他的使用方法2013-12-12
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。他以urlopen函数的形式提供了一个非常简单的接口,下面我们用实例讲解他的使用方法2013-12-12 篇文章主要介绍了Python if 条件判断语句,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-10-10
篇文章主要介绍了Python if 条件判断语句,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-10-10 这篇文章主要为大家分享如何利用Python Tkinter库制作带图形界面的一个签名设计工具,文中的示例代码讲解详细,感兴趣的小伙伴可以了解一下2022-04-04
这篇文章主要为大家分享如何利用Python Tkinter库制作带图形界面的一个签名设计工具,文中的示例代码讲解详细,感兴趣的小伙伴可以了解一下2022-04-04 这篇文章主要介绍了Python模块、包(Package)概念与用法,结合实例形式分析了Python中模块、包(Package)概念、功能、相关使用技巧与注意事项,需要的朋友可以参考下2019-05-05
这篇文章主要介绍了Python模块、包(Package)概念与用法,结合实例形式分析了Python中模块、包(Package)概念、功能、相关使用技巧与注意事项,需要的朋友可以参考下2019-05-05 Pandas是一个功能强大且通用的Python库,用于数据操作和分析,它最有用的特性之一是数据透视表,它允许您重塑和汇总数据,但是,使用数据透视表通常会导致多级(分层)索引,在本文中,我们将探讨如何在Pandas中使用透视表后去掉多级索引,需要的朋友可以参考下2024-12-12
Pandas是一个功能强大且通用的Python库,用于数据操作和分析,它最有用的特性之一是数据透视表,它允许您重塑和汇总数据,但是,使用数据透视表通常会导致多级(分层)索引,在本文中,我们将探讨如何在Pandas中使用透视表后去掉多级索引,需要的朋友可以参考下2024-12-12 这篇文章主要介绍了如何用最简洁的Python代码实现图片压缩效果,还可以保证照片不失真,感兴趣的小伙伴可以跟随小编一起动手试试2022-01-01
这篇文章主要介绍了如何用最简洁的Python代码实现图片压缩效果,还可以保证照片不失真,感兴趣的小伙伴可以跟随小编一起动手试试2022-01-01 今天小编就为大家分享一篇解决seaborn在pycharm中绘图不出图的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
今天小编就为大家分享一篇解决seaborn在pycharm中绘图不出图的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 在今天的互联网时代,实时通信成为了许多应用和服务的核心特色,在本文中,我们将介绍如何使用 Flask 和 Websockets 通过 Flask-SocketIO 框架创建一个简单的在线聊天室,感兴趣的可以跟随小编一起了解下2023-09-09
在今天的互联网时代,实时通信成为了许多应用和服务的核心特色,在本文中,我们将介绍如何使用 Flask 和 Websockets 通过 Flask-SocketIO 框架创建一个简单的在线聊天室,感兴趣的可以跟随小编一起了解下2023-09-09 这篇文章主要介绍了Python基于百度AI实现OCR文字识别,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04
这篇文章主要介绍了Python基于百度AI实现OCR文字识别,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04










最新评论