
Python垃圾邮件的逻辑回归分类示例详解
更新时间:2021年11月29日 09:19:03 作者:K_C_of
这篇文章主要给大家介绍了关于Python垃圾邮件的逻辑回归分类的相关资料,作为初学者实践文本分类是一个不错的开始,文中通过实例代码介绍的非常详细,需要的朋友可以参考下
加载垃圾邮件数据集spambase.csv(数据集基本信息:样本数: 4601,特征数量: 57, 类别:
1 为垃圾邮件,0 为非垃圾邮件),阅读并理解数据。
按以下要求处理数据集
(1)分离出仅含特征列的部分作为 X 和仅含目标列的部分作为 Y。
(2)将数据集拆分成训练集和测试集(70%和 30%)。
建立逻辑回归模型
分别用 LogisticRegression 建模。
结果比对
(1)输出测试集前 5 个样本的预测结果。
(2)计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
(3)从测试集中找出模型不能正确预测的样本。
(4)对参数 penalty 分别取‘l1', ‘l2', ‘elasticnet', ‘none',对比它们在测试集上的预测性能(计算 score)。
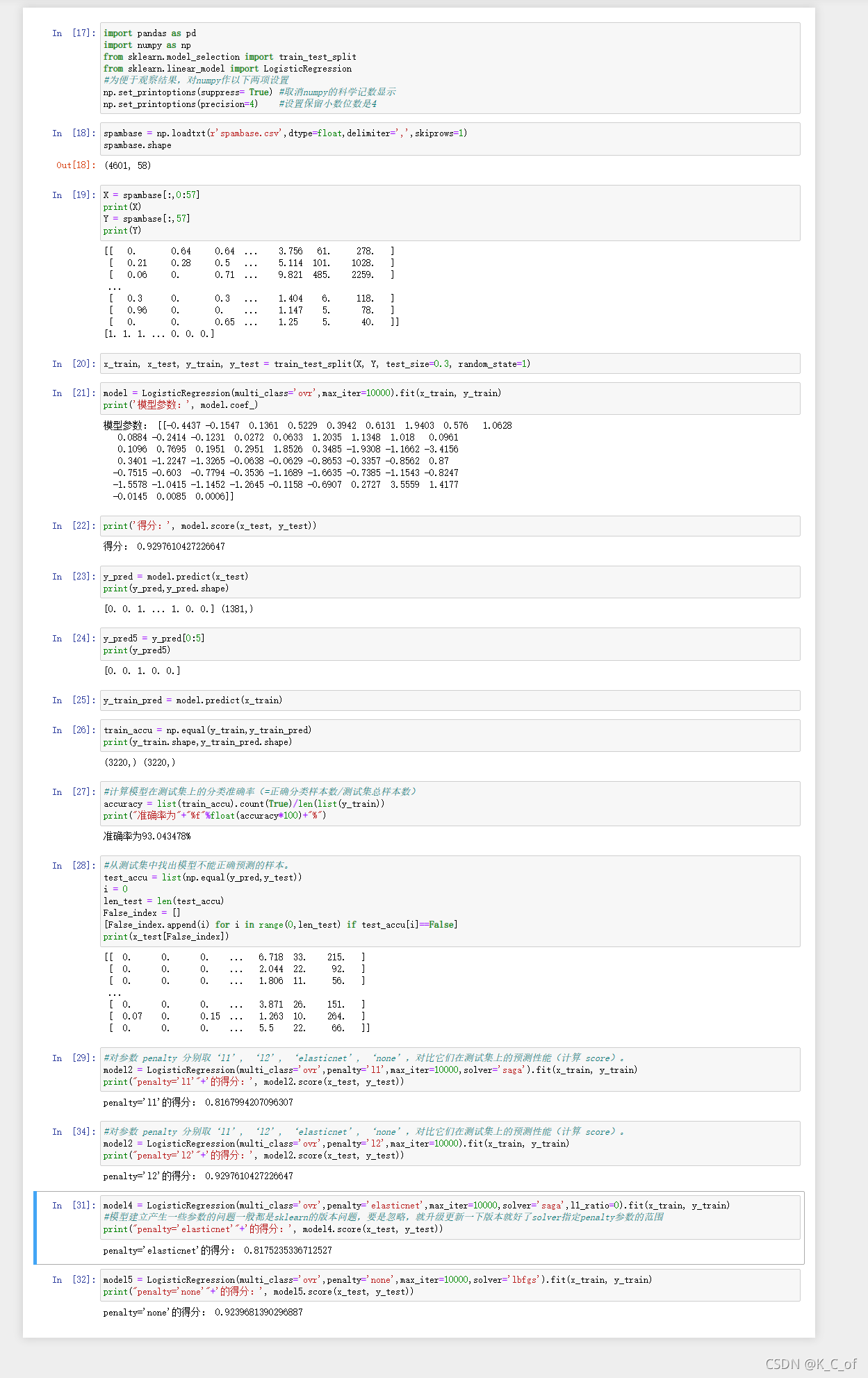
拆分特征值和目标数据前面已经可知,预测和模型得分结果也是直接使用模型的方法,下面主要是要测试准确率和找出不能正确预测的样本,以及不同的惩罚下的模型得分,主要运用到Numpy模块和列表list的函数,代码如下:
y_train_pred = model.predict(x_train)
# In[26]:
train_accu = np.equal(y_train,y_train_pred)
print(y_train.shape,y_train_pred.shape)
# In[27]:
#计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
accuracy = list(train_accu).count(True)/len(list(y_train))
print("准确率为"+"%f"%float(accuracy*100)+"%")
# In[28]:
#从测试集中找出模型不能正确预测的样本。
test_accu = list(np.equal(y_pred,y_test))
i = 0
len_test = len(test_accu)
False_index = []
[False_index.append(i) for i in range(0,len_test) if test_accu[i]==False]
print(x_test[False_index])
# In[29]:
#对参数 penalty 分别取‘l1', ‘l2', ‘elasticnet', ‘none',对比它们在测试集上的预测性能(计算 score)。
model2 = LogisticRegression(multi_class='ovr',penalty='l1',max_iter=10000,solver='saga').fit(x_train, y_train)
print("penalty='l1'"+'的得分:', model2.score(x_test, y_test))
# In[33]:
#对参数 penalty 分别取‘l1', ‘l2', ‘elasticnet', ‘none',对比它们在测试集上的预测性能(计算 score)。
model2 = LogisticRegression(multi_class='ovr',penalty='l2',max_iter=10000).fit(x_train, y_train)
print("penalty='l2'"+'的得分:', model2.score(x_test, y_test))
# In[31]:
model4 = LogisticRegression(multi_class='ovr',penalty='elasticnet',max_iter=10000,solver='saga',l1_ratio=0).fit(x_train, y_train)
#模型建立产生一些参数的问题一般都是sklearn的版本问题,要是忽略,就升级更新一下版本就好了solver指定penalty参数的范围
print("penalty='elasticnet'"+'的得分:', model4.score(x_test, y_test))
# In[32]:
model5 = LogisticRegression(multi_class='ovr',penalty='none',max_iter=10000,solver='lbfgs').fit(x_train, y_train)
print("penalty='none'"+'的得分:', model5.score(x_test, y_test))
总结
到此这篇关于Python垃圾邮件的逻辑回归分类的文章就介绍到这了,更多相关Python垃圾邮件分类内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
相关文章
 在使用Python开发过程中,我们经常需要使用各种第三方库来扩展Python的功能,这篇文章主要给大家介绍了关于Python离线安装第三方库的相关资料,需要的朋友可以参考下2023-11-11
在使用Python开发过程中,我们经常需要使用各种第三方库来扩展Python的功能,这篇文章主要给大家介绍了关于Python离线安装第三方库的相关资料,需要的朋友可以参考下2023-11-11 这篇文章主要介绍了python如何将两个数据表中的对应数据相加问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
这篇文章主要介绍了python如何将两个数据表中的对应数据相加问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 这篇文章主要介绍了python statsmodel使用的相关资料,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12
这篇文章主要介绍了python statsmodel使用的相关资料,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12 在本篇文章当中主要给大家深入介绍在 cpython 当中非常重要的一个数据结构 code object! 我们简单介绍了一下在 code object 当中有哪些字段以及这些字段的简单含义,在本篇文章当中将会举一些例子以便更加深入理解这些字段2023-04-04
在本篇文章当中主要给大家深入介绍在 cpython 当中非常重要的一个数据结构 code object! 我们简单介绍了一下在 code object 当中有哪些字段以及这些字段的简单含义,在本篇文章当中将会举一些例子以便更加深入理解这些字段2023-04-04 今天小编就为大家分享一篇python调用c++传递数组的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-02-02
今天小编就为大家分享一篇python调用c++传递数组的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-02-02
Python Pandas list列表数据列拆分成多行的方法实现
这篇文章主要介绍了Python Pandas list(列表)数据列拆分成多行的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12 本文主要介绍了Python 字符替换的四方法,主要包括replace、translate、maketrans 和正则这是四种方法,具有一定的参考价值,感兴趣的可以了解一下2024-01-01
本文主要介绍了Python 字符替换的四方法,主要包括replace、translate、maketrans 和正则这是四种方法,具有一定的参考价值,感兴趣的可以了解一下2024-01-01 这篇文章主要介绍了python 绘制正态曲线的示例,帮助大家更好的利用python绘制图像,感兴趣的朋友可以了解下2020-09-09
这篇文章主要介绍了python 绘制正态曲线的示例,帮助大家更好的利用python绘制图像,感兴趣的朋友可以了解下2020-09-09
python自动化测试中装饰器@ddt与@data源码深入解析
最近工作中接触了python自动化测试,所以下面这篇文章主要给大家介绍了关于python自动化测试中装饰器@ddt与@data源码解析的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-12-12 这篇文章主要介绍了python实现判断数组是否包含指定元素的方法,涉及Python中in的使用技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了python实现判断数组是否包含指定元素的方法,涉及Python中in的使用技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-07-07










最新评论