
联邦学习FedAvg中模型聚合过程的理解分析
问题
联邦学习原始论文中给出的FedAvg的算法框架为:

参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率。
首先是服务器执行以下步骤:

对每一个本地客户端来说,要做的就是更新本地参数,具体来讲:
- 把自己的数据集按照参数B分成若干个块,每一块大小都为B。
- 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w 。
- 更新完后 w w w将被传送到中央服务器,服务器整合所有客户端计算出的 w,得到最新的全局模型参数 wt+1
- 客户端收到服务器发送的最新全局参数模型参数,进行下一次更新。
我们仔细观察server的最后一步:
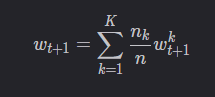

聚合
那么针对聚合,就有以下两种情况。
1. 聚合所有客户端
服务器端每次将新的全局模型发送给全部客户端,并且聚合全部客户端的模型参数。如果客户端未被选中,那么一轮通信结束后,该客户端的模型为一轮通信开始时从服务器获得的初始模型。
设当前全局模型为 wt,服务器选中了 m个客户端(集合V),m个客户端本地更新完毕后,服务器端的聚合公式为:
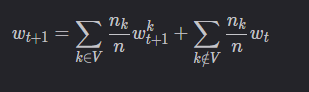
也就是说,每一次聚合时服务器端都将所有客户端的模型考虑在内。
2. 仅聚合被选中的客户端
服务器每次只是将当前新的参数传递给被选中的模型,并且只是聚合被选中客户端的模型参数。
设当前全局模型为 wt,服务器选中了 m 个客户端(集合V),然后将wt只发送给这 m个客户端。 m m m个客户端训练完毕后,服务器端的聚合公式为:
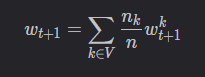
3. 选择
虽然原始论文中对所有K个客户端都进行了聚合,但在真正实现时,感觉用第二种会更好一点,因为如果客户端数量很庞大,每一次通信都会有不小的代价,用第二种会明显降低通信成本。
以上就是FedAvg中模型聚合过程的理解分析的详细内容,更多关于FedAvg模型聚合的资料请关注脚本之家其它相关文章!
相关文章
 找了一个和谐工具,运行和谐工具后,看IDM关于那里,已经是全功能版本,美中不足的是,IDM运行一段时间,就会弹出neg窗口,说文件被修改,最好是去官网下载原版的提示,就这个问题怎么处理呢?对IDM 6.40.11.2 弹窗的解决思路感兴趣的朋友跟随小编一起看看吧2023-01-01
找了一个和谐工具,运行和谐工具后,看IDM关于那里,已经是全功能版本,美中不足的是,IDM运行一段时间,就会弹出neg窗口,说文件被修改,最好是去官网下载原版的提示,就这个问题怎么处理呢?对IDM 6.40.11.2 弹窗的解决思路感兴趣的朋友跟随小编一起看看吧2023-01-01 这篇文章主要介绍了解读Base64编码中为什么会有等号(=)问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-03-03
这篇文章主要介绍了解读Base64编码中为什么会有等号(=)问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-03-03
网络编程基础(局域网、ip、子网掩码、网关、DNS)概念理解
这篇文章主要介绍了网络编程基础(局域网、ip、子网掩码、网关、DNS)概念理解,包括局域网的构成、IP地址的分类和作用、子网掩码的作用以及网络通信规则等2025-02-02 这篇文章主要介绍了git checkout 命令使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07
这篇文章主要介绍了git checkout 命令使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07
解决使用IDE Run运行出错package pack/test is not in GOROOT (/usr/loca
这篇文章主要介绍了解决使用IDE Run运行出错package pack/test is not in GOROOT (/usr/local/go/src/pack/test),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-11-11
使用 tke-autoscaling-placeholder 实现秒级弹性伸缩的方法
这篇文章主要介绍了使用 tke-autoscaling-placeholder 实现秒级弹性伸缩的方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01 JSON即JS对象简谱 , 是一种轻量级的数据交换格式,Java官方没有提供JSON解析相应的API,本文提供两个最常用的JSON解析方法,分别是Google的Gson,阿里的FastJson,使用JSON解析之前要先获取相应的jar包,感兴趣的朋友一起看看吧2023-08-08
JSON即JS对象简谱 , 是一种轻量级的数据交换格式,Java官方没有提供JSON解析相应的API,本文提供两个最常用的JSON解析方法,分别是Google的Gson,阿里的FastJson,使用JSON解析之前要先获取相应的jar包,感兴趣的朋友一起看看吧2023-08-08 HTTP协议是基于请求/响应范式的。一个客户机与服务器建立连接后,发送一个请求给服务器,请求方式的格式为,统一资源标识符、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。2011-02-02
HTTP协议是基于请求/响应范式的。一个客户机与服务器建立连接后,发送一个请求给服务器,请求方式的格式为,统一资源标识符、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。2011-02-02
unicode utf-8 gb18030 gb2312 gbk各种编码对比
在修改一个cms的过程当中遇到一个php截取字符串的函数(当然得兼容中英字符了),因为对各种编码的字符范围和字符表示不清楚,感觉一头迷雾,虽然可以直接来调用这个函数2009-05-05
DeepSeek R1本地化部署 Ollama + Chatbox 如
文章介绍了如何在本地部署DeepSeekR1模型并使用Chatbox进行交互,使用户能够拥有强大的AI工具,感兴趣的朋友跟随小编一起看看吧2025-02-02










最新评论