
python memory_profiler库生成器和迭代器内存占用的时间分析
更新时间:2022年06月28日 14:41:48 作者:MAR-Sky
这篇文章主要介绍了python memory_profiler库生成器和迭代器内存占用的时间分析,文章围绕主题展开详细的内容介绍,感兴趣的小伙伴可以参考一下
不进行计算时,生成器和list空间占用
import time
from memory_profiler import profile
@profile(precision=4)
def list_fun():
start = time.time()
total = ([i for i in range(5000000)])
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = (i for i in range(5000000))
print('gent_spend_time:',time.time()-gent_start)
iter_fun()
gent_func()
显示结果的含义:第一列表示已分析代码的行号,第二列(Mem 使用情况)表示执行该行后 Python 解释器的内存使用情况。第三列(增量)表示当前行相对于最后一行的内存差异。最后一列(行内容)打印已分析的代码。
分析:在不进行计算的情况下,列表list和迭代器会占用空间,但对于生成器不会占用空间
当需要计算时,list和生成器的花费时间和占用内存
使用sum内置函数,list和生成器求和10000000个数据,list内存占用较大,生成器花费时间大概是list的两倍
import time
from memory_profiler import profile
@profile(precision=4)
def iter_fun():
start = time.time()
total = sum([i for i in range(10000000)])
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = sum(i for i in range(10000000))
print('gent_spend_time:',time.time()-gent_start)
iter_fun()
gent_func()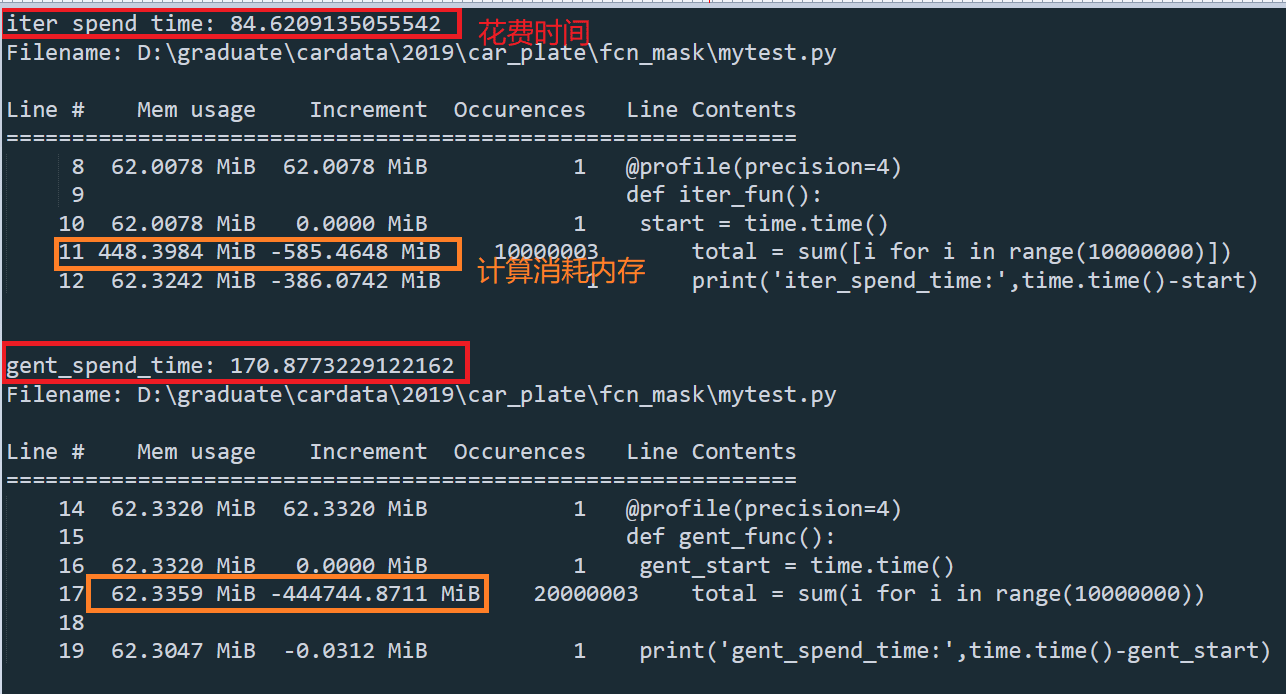
比较分析,如果需要对数据进行迭代使用时,生成器方法的耗时较长,但内存使用方面还是较少,因为使用生成器时,内存只存储每次迭代计算的数据。分析原因时个人认为,生成器的迭代计算过程中,在迭代数据和计算直接不断转换,相比与迭代器对象中先将数据全部保存在内存中(虽然占内存,但读取比再次迭代要快),因此,生成器比较费时间,但占用内存小。
记录数据循环求和500000个数据,迭代器和生成器循环得到时
总结:几乎同时完成,迭代器的占用内存较大
import time
from memory_profiler import profile
itery = iter([i for i in range(5000000)])
gent = (i for i in range(5000000))
@profile(precision=4)
def iter_fun():
start = time.time()
total= 0
for item in itery:
total+=item
print('iter:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = 0
for item in gent:
total+=item
print('gent:',time.time()-gent_start)
iter_fun()
gent_func()
list,迭代器和生成器共同使用sum计算5000000个数据时间比较
总结:list+sum和迭代器+sum计算时长差不多,但生成器+sum计算的时长几乎长一倍,
import time
from memory_profiler import profile
@profile(precision=4)
def list_fun():
start = time.time()
print('start!!!')
list_data = [i for i in range(5000000)]
total = sum(list_data)
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def iter_fun():
start = time.time()
total = 0
total = sum(iter([i for i in range(5000000)]))
print('total:',total)
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = sum(i for i in range(5000000))
print('total:',total)
print('gent_spend_time:',time.time()-gent_start)
list_fun()
iter_fun()
gent_func()
到此这篇关于python memory_profiler库生成器和迭代器内存占用的时间分析的文章就介绍到这了,更多相关python的memory_profiler 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python数据类型之Set集合,结合实例形式详细分析了Python数据类型中集合的概念、原理、创建、遍历、交集、并集等相关操作技巧,需要的朋友可以参考下2019-05-05
这篇文章主要介绍了Python数据类型之Set集合,结合实例形式详细分析了Python数据类型中集合的概念、原理、创建、遍历、交集、并集等相关操作技巧,需要的朋友可以参考下2019-05-05 这篇文章主要介绍了Python中的is和==比较两个对象的两种方法的相关资料,希望通过本文能帮助到大家,需要的朋友可以参考下2017-09-09
这篇文章主要介绍了Python中的is和==比较两个对象的两种方法的相关资料,希望通过本文能帮助到大家,需要的朋友可以参考下2017-09-09
详解PyQt5 GUI 接收UDP数据并动态绘图的过程(多线程间信号传递)
这篇文章主要介绍了PyQt5 GUI 接收UDP数据并动态绘图(多线程间信号传递),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09![python中shape[0]与shape[1]的说明](//img.jbzj.com/images/xgimg/bcimg3.png) 这篇文章主要介绍了python中shape[0]与shape[1]的说明,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
这篇文章主要介绍了python中shape[0]与shape[1]的说明,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 如果你使用Python和Pandas进行数据分析,循环是不可避免要使用的。这篇文章主要给大家介绍了关于Pandas加速代码之避免使用for循环的相关资料,需要的朋友可以参考下2021-05-05
如果你使用Python和Pandas进行数据分析,循环是不可避免要使用的。这篇文章主要给大家介绍了关于Pandas加速代码之避免使用for循环的相关资料,需要的朋友可以参考下2021-05-05 这篇文章主要为大家详细介绍了Python实现仓库管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05
这篇文章主要为大家详细介绍了Python实现仓库管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05 本篇文章主要介绍了Python 通过selenium实现毫秒级自动抢购的示例代码,通过扫码登录即可自动完成一系列操作,抢购时间精确至毫秒,可抢加购物车等待时间结算的,感兴趣的小伙伴们可以参考一下2019-09-09
本篇文章主要介绍了Python 通过selenium实现毫秒级自动抢购的示例代码,通过扫码登录即可自动完成一系列操作,抢购时间精确至毫秒,可抢加购物车等待时间结算的,感兴趣的小伙伴们可以参考一下2019-09-09 Shap 是一个开源的 python 库,用于解释模型。它可以创建多种类型的可视化,有助于了解模型和解释模型是如何工作的。在本文中,我们将会分享一些Shap创建的不同类型的机器学习模型可视化2021-11-11
Shap 是一个开源的 python 库,用于解释模型。它可以创建多种类型的可视化,有助于了解模型和解释模型是如何工作的。在本文中,我们将会分享一些Shap创建的不同类型的机器学习模型可视化2021-11-11 PyQt5是强大的GUI工具之一,通过其可以实现优秀的桌面应用程序。本文主要介绍了PyQt5实现用户登录GUI界面及登录后跳转,具有一定的参考价值,感兴趣的可以了解一下2021-11-11
PyQt5是强大的GUI工具之一,通过其可以实现优秀的桌面应用程序。本文主要介绍了PyQt5实现用户登录GUI界面及登录后跳转,具有一定的参考价值,感兴趣的可以了解一下2021-11-11 这篇文章主要介绍了Spark分布式集群环境搭建基于Python版,Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。100 倍本文而是使用三台电脑来搭建一个小型分布式集群环境安装,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了Spark分布式集群环境搭建基于Python版,Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。100 倍本文而是使用三台电脑来搭建一个小型分布式集群环境安装,需要的朋友可以参考下2019-07-07



![python中shape[0]与shape[1]的说明](http://img.jbzj.com/images/xgimg/bcimg3.png)






最新评论