
利用Python提取PDF文本的简单方法实例
你好,一般情况下,Ctrl+C 是最简单的方法,当无法 Ctrl+C 时,我们借助于 Python,以下是具体步骤:
第一步,安装工具库
1、tika — 用于从各种文件格式中进行文档类型检测和内容提取
2、wand — 基于 ctypes 的简单 ImageMagick 绑定
3、pytesseract — OCR 识别工具
创建一个虚拟环境,安装这些工具
python -m venv venv source venv/bin/activate pip install tika wand pytesseract
第二步,编写代码
假如 pdf 文件里面既有文字,又有图片,以下代码可以直接识别文字:
import io
import pytesseract
import sys
from PIL import Image
from tika import parser
from wand.image import Image as wi
text_raw = parser.from_file("example.pdf")
print(text_raw['content'].strip())这还不够,我们还需要能失败图片的部分:
def extract_text_image(from_file, lang='deu', image_type='jpeg', resolution=300):
print("-- Parsing image", from_file, "--")
print("---------------------------------")
pdf_file = wi(filename=from_file, resolution=resolution)
image = pdf_file.convert(image_type)
image_blobs = []
for img in image.sequence:
img_page = wi(image=img)
image_blobs.append(img_page.make_blob(image_type))
extract = []
for img_blob in image_blobs:
image = Image.open(io.BytesIO(img_blob))
text = pytesseract.image_to_string(image, lang=lang)
extract.append(text)
for item in extract:
for line in item.split("\n"):
print(line)合并一下,完整代码如下:
import io
import sys
from PIL import Image
import pytesseract
from wand.image import Image as wi
from tika import parser
def extract_text_image(from_file, lang='deu', image_type='jpeg', resolution=300):
print("-- Parsing image", from_file, "--")
print("---------------------------------")
pdf_file = wi(filename=from_file, resolution=resolution)
image = pdf_file.convert(image_type)
for img in image.sequence:
img_page = wi(image=img)
image = Image.open(io.BytesIO(img_page.make_blob(image_type)))
text = pytesseract.image_to_string(image, lang=lang)
for part in text.split("\n"):
print("{}".format(part))
def parse_text(from_file):
print("-- Parsing text", from_file, "--")
text_raw = parser.from_file(from_file)
print("---------------------------------")
print(text_raw['content'].strip())
print("---------------------------------")
if __name__ == '__main__':
parse_text(sys.argv[1])
extract_text_image(sys.argv[1], sys.argv[2])第三步,执行
假如 example.pdf 是这样的:

在命令行这样执行:
python run.py example.pdf deu | xargs -0 echo > extract.txt
最终 extract.txt 的结果如下:
-- Parsing text example.pdf --
---------------------------------
Title pure text
Content pure text
Slide 1
Slide 2
---------------------------------
-- Parsing image example.pdf --
---------------------------------
Title pure text
Content pure text
Title in image
Text in image
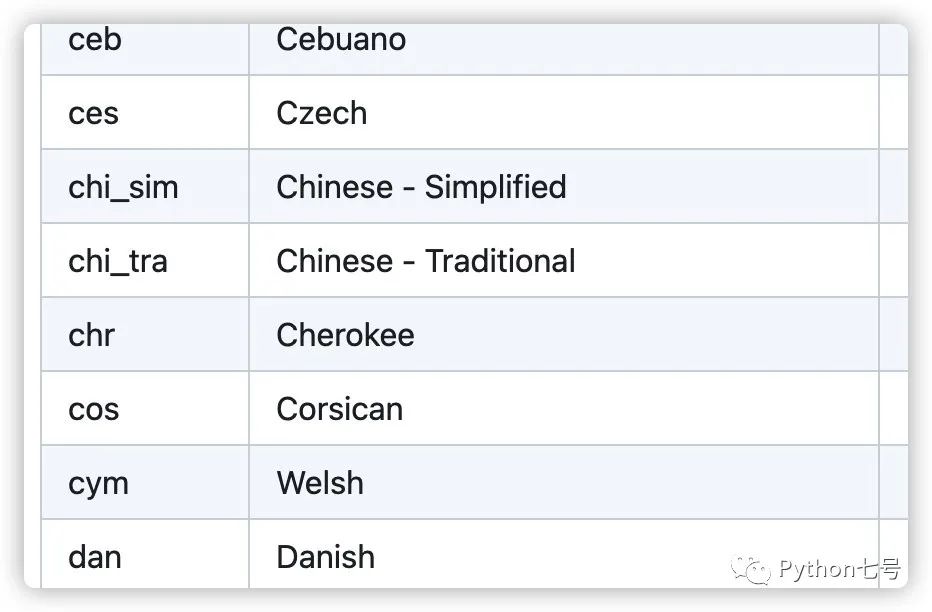
你可能会问,如果是简体中文,那个 lang 参数传递什么,传 'chi_sim',其实是有官方说明的,链接如下:
https://github.com/tesseract-ocr/tessdoc/blob/main/Data-Files-in-different-versions.md
最后的话
从 PDF 中提取文本的脚本实现并不复杂,许多库简化了工作并取得了很好的效果
到此这篇关于利用Python提取PDF文本的简单方法的文章就介绍到这了,更多相关Python提取PDF文本内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

利用Python自带PIL库扩展图片大小给图片加文字描述的方法示例
最近的一个工程项目是讲文字添加到图像上,所以下面这篇文章主要给大家介绍了关于利用Python自带PIL库扩展图片大小给图片加文字描述的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧。2017-08-08 这篇文章主要介绍了python方法之绑定方法与非绑定方法的相关资料,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-08-08
这篇文章主要介绍了python方法之绑定方法与非绑定方法的相关资料,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-08-08
http通过StreamingHttpResponse完成连续的数据传输长链接方式
这篇文章主要介绍了http通过StreamingHttpResponse完成连续的数据传输长链接方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-02-02 这篇文章主要为大家详细介绍了Tensorflow训练MNIST手写数字识别模型,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-02-02
这篇文章主要为大家详细介绍了Tensorflow训练MNIST手写数字识别模型,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-02-02 这篇文章主要介绍了从np.random.normal()到正态分布的拟合操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了从np.random.normal()到正态分布的拟合操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06 这篇文章主要介绍了python爬取Ajax动态加载网页过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了python爬取Ajax动态加载网页过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09 这篇文章主要介绍了python调用win32接口进行截图的示例,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-11-11
这篇文章主要介绍了python调用win32接口进行截图的示例,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-11-11 这篇文章主要为大家详细介绍了Python之给我一面国旗的实现代码,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09
这篇文章主要为大家详细介绍了Python之给我一面国旗的实现代码,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09 很多浏览器都贴心地提供了保存用户密码功能,用户一旦开启,就不需要每次都输入用户名、密码,非常方便,作为python脚本,能否拿到用户提前保存在浏览器中的用户名密码,用以自动登录呢,下面我们就来看看吧2023-08-08
很多浏览器都贴心地提供了保存用户密码功能,用户一旦开启,就不需要每次都输入用户名、密码,非常方便,作为python脚本,能否拿到用户提前保存在浏览器中的用户名密码,用以自动登录呢,下面我们就来看看吧2023-08-08 在科学技术和机器学习等其他算法相关任务中,我们经常需要用到随机数,本文就详细的介绍一下Python随机数种子,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-07-07
在科学技术和机器学习等其他算法相关任务中,我们经常需要用到随机数,本文就详细的介绍一下Python随机数种子,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-07-07










最新评论