
保姆级官方yolov7训练自己的数据集及项目部署详解
前言
首先,先说明我只是初步接触yolov7,写这篇文章的主要目的是可以让大家快速应用自己的数据集进行训练。没有接触过yolov5也没有关系,该篇文章会逐步进行演示如何训练。
第一步 数据集准备
首先确保你有labelimg标图软件,若无,需要自行去下一个并看一下标图教程。
当你已经标注完成,获得了img以及相对应的xml之后(如图)

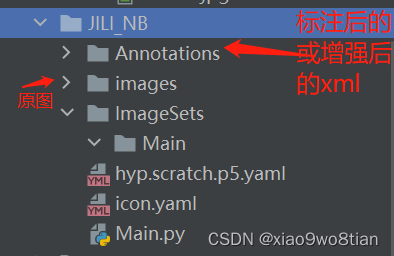
接下来就是可选择项:是否需要图像增强来获取更多样本,如需要点击这里下载 ,直接用enhance_img.py去增强。之后我的习惯是每有一个项目需要训练,则会新建一个文件夹,项目存放的文件如图:
下面ImageSets\Main用于存放后续脚本文件划分训练集测试集的相对应的train.txt,test.txt。hyp.scratch.p5.yaml为yolov7的超参设置,可以直接从yolov7\data下面去拷过来放到你项目里。icon.yaml为你要所要训练的类别和相应的类,同时也会写上实际训练时训练数据和测试数据。该文件如下图。

Main.py就是划分你的数据为训练集和测试集.txt的脚本。整体新建的项目目录就是这样。下面说一下操作流程:1 首先确保是该项目目录方式 2 运行main.py脚本文件得到了ImageSets\Main下面的train.txt,test.txt。3 在yolov7的根目录下运行xml2txt脚本文件。main.py xml2txt.py文件点击这里下载 注意要将该文件的类和项目名改成自己的。如图:


此时,我们的数据准备阶段已经完成,项目目录如图:
第二步 train.py载入自己的数据集并训练
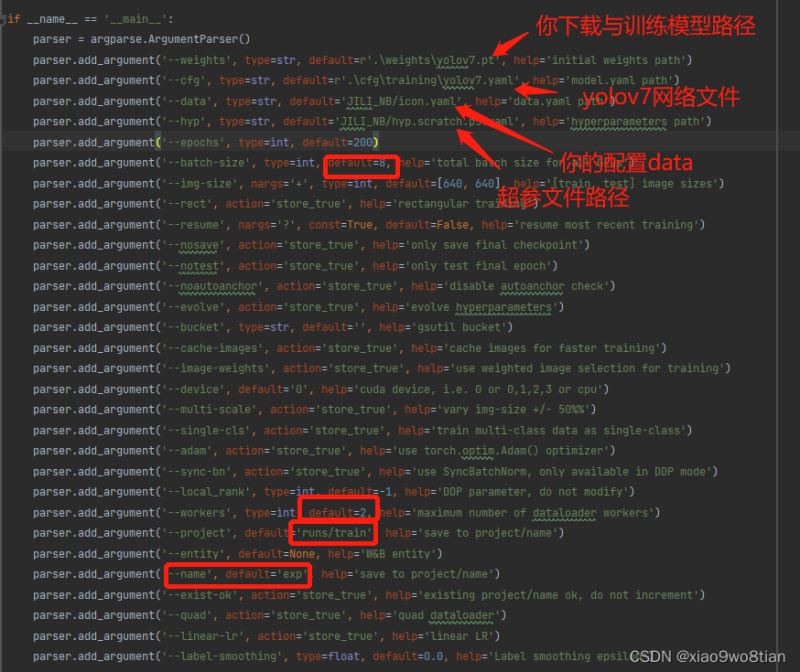
红色箭头和红框就是常见改动的地方,改动后就可以训练了。
第三步 将训练好的pt文件做成接口调用
在等待训练完成之后,就会在runs/train下面获得训练的best.pt,你可以拿着这个pt去做接口使用了。首先,在自己的项目里使用必须要确保yolov7根目录下的models和utils文件夹放到了你的项目根目录。然后下载model_import.py 点击这里下载 嵌入你的任何项目路径下调用predict函数就可以输出检出结果了。
总结
到此这篇关于保姆级官方yolov7训练自己的数据集及项目部署的文章就介绍到这了,更多相关yolov7训练自己的数据集内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 大家好,本篇文章主要讲的是python3基础之集合set详解,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下,方便下次浏览2021-12-12
大家好,本篇文章主要讲的是python3基础之集合set详解,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下,方便下次浏览2021-12-12 这篇文章主要介绍了详解Python最长公共子串和最长公共子序列的实现。小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-07-07
这篇文章主要介绍了详解Python最长公共子串和最长公共子序列的实现。小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-07-07 这篇文章主要为大家详细介绍了python制作简单五子棋游戏,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-06-06
这篇文章主要为大家详细介绍了python制作简单五子棋游戏,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-06-06 这篇文章主要介绍了Python numpy中的ndarray,numpy 模块通常被称为 matplotlib 模块伴侣,numpy可以方便快捷地对大量数据进行科学计算,为matplotlib 绘制图表提供数据,下面来看看文章内容的详细介绍吧2022-01-01
这篇文章主要介绍了Python numpy中的ndarray,numpy 模块通常被称为 matplotlib 模块伴侣,numpy可以方便快捷地对大量数据进行科学计算,为matplotlib 绘制图表提供数据,下面来看看文章内容的详细介绍吧2022-01-01 哆啦A梦系列是陪伴我,乃至陪伴了几代人成长的故事.50年来,藤子·F·不二雄先生创造了竹蜻蜓,任意门,时光机器等等无数的新奇道具,让大雄和他的小伙伴们经历了各种冒险,也经历了许多充满戏剧性的啼笑皆非的日常.特意写了这篇文章,教大家怎么绘制词云图,需要的朋友可以参考下2021-06-06
哆啦A梦系列是陪伴我,乃至陪伴了几代人成长的故事.50年来,藤子·F·不二雄先生创造了竹蜻蜓,任意门,时光机器等等无数的新奇道具,让大雄和他的小伙伴们经历了各种冒险,也经历了许多充满戏剧性的啼笑皆非的日常.特意写了这篇文章,教大家怎么绘制词云图,需要的朋友可以参考下2021-06-06 这篇文章主要为大家介绍了python不支持 i++运算原理实例解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-02-02
这篇文章主要为大家介绍了python不支持 i++运算原理实例解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-02-02 这篇文章主要介绍了Numpy维度知识总结,因为在numpy里一维既可以做行向量也可以做列向量,那对于任意一个给定的一维向量,我们就无法确定他到底是行向量还是列向量,为了防止这种尴尬的境地,习惯上用二维矩阵而不是一维矩阵来表示行向量和列向量,需要的朋友可以参考下2023-09-09
这篇文章主要介绍了Numpy维度知识总结,因为在numpy里一维既可以做行向量也可以做列向量,那对于任意一个给定的一维向量,我们就无法确定他到底是行向量还是列向量,为了防止这种尴尬的境地,习惯上用二维矩阵而不是一维矩阵来表示行向量和列向量,需要的朋友可以参考下2023-09-09 这篇文章主要介绍了pytorch HWC转CHW的实现方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
这篇文章主要介绍了pytorch HWC转CHW的实现方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05 这篇文章主要教大家如何简单实现python进度条,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-12-12
这篇文章主要教大家如何简单实现python进度条,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-12-12 在本篇文章里小编给大家整理的是一篇关于python字符串的多行输出的实例详解内容,有兴趣的朋友们跟着学习下。2021-06-06
在本篇文章里小编给大家整理的是一篇关于python字符串的多行输出的实例详解内容,有兴趣的朋友们跟着学习下。2021-06-06










最新评论