
Python Pandas教程之使用 pandas.read_csv() 读取 csv
更新时间:2022年09月16日 09:46:43 作者:海拥
这篇文章主要介绍了Python Pandas教程之使用pandas.read_csv()读取csv,文章通过围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下
前言:
Python 是一种用于进行数据分析的出色语言,主要是因为以数据为中心的 Python 包的奇妙生态系统。Pandas 就是其中之一,它使导入和分析数据变得更加容易。
大多数用于分析的数据以表格格式的形式提供,例如 Excel 和逗号分隔文件 (CSV)。要访问 csv 文件中的数据,我们需要一个函数 read_csv() 以数据框的形式检索数据。在使用这个功能之前,我们必须导入 pandas 库。
导入 Pandas 库:
import pandas as pd
read_csv() 函数用于从 csv 文件中检索数据。read_csv() 方法的语法是:
pd.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None,
usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True,
dtype=None, engine=None, converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer',
thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None,
encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0,
doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None) 代码 #1 从 csv 文件中检索数据
# Import pandas
import pandas as pd
# 读取csv文件
pd.read_csv("filename.csv")这是带有默认值的参数列表。并非所有这些都很重要,但记住这些实际上可以节省自己执行某些功能的时间。通过在 jupyter notebook 中按 shift + tab 可以查看任何函数的参数。
下面给出了有用的和它们的用法:
- filepath_or_buffer:这是要使用此函数检索的文件的位置。它接受文件的任何字符串路径或 URL。
- sep:表示分隔符,默认为 ', ',如 csv(逗号分隔值)。
- header:它接受 int、int 列表、行号用作列名和数据的开头。如果没有传递名称,即header=None,那么它将显示第一列为0,第二列显示为1,以此类推。
- usecols:用于仅从 csv 文件中检索选定的列。
- nrows:表示要从数据集中显示的行数。
- index_col:如果没有,则没有索引号与记录一起显示。
- 挤压:如果为真且仅传递一列,则返回熊猫系列。
- skiprows:跳过新数据框中传递的行。
- 名称:它允许检索具有新名称的列。
| 范围 | Use |
|---|---|
| filepath_or_buffer | 文件的 URL 或目录位置 |
| sep | 代表分隔符,默认为 ', ' 如 csv(逗号分隔值) |
| index_col | 将传递的列作为索引而不是 0、1、2、3…r 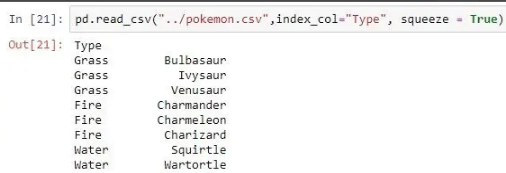 |
| header | 将传递的 row/s[int/int list] 作为标题 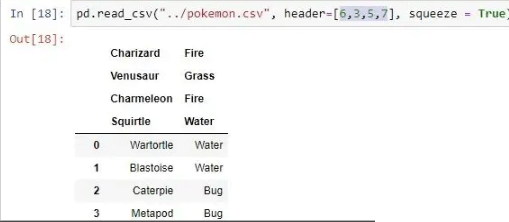 |
| use_cols | 仅使用传递的 col[string list] 来制作数据框 |
| squeeze | 如果为 true 且仅传递一列,则返回 pandas 系列 |
| skiprows | 跳过新数据框中传递的行 |
Code #2 :
# 导入 Pandas 库
import pandas as pd
pd.read_csv(filepath_or_buffer = "pokemon.csv")
# 使传递的行标题
pd.read_csv("pokemon.csv", header =[1, 2])
# 将传递的列作为索引而不是 0、1、2、3....
pd.read_csv("pokemon.csv", index_col ='Type')
# 仅将传递的 cols 用于数据框
pd.read_csv("pokemon.csv", usecols =["Type"])
# 如果只有一列,则返回熊猫系列
pd.read_csv("pokemon.csv", usecols =["Type"], squeeze = True)
# 跳过新系列中传递的行
pd.read_csv("pokemon.csv", skiprows = [1, 2, 3, 4])到此这篇关于Python Pandas教程之使用 pandas.read_csv() 读取 csv的文章就介绍到这了,更多相关Python pandas.read_csv() 读取 csv内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 在开发过程中,配置文件是少不了的,而且配置文件是有专门的格式的,比如:ini, yaml, toml 等等。而对于 Python 而言,也都有相应的库来解析相应格式的文件,下面我们来看看 ini 文件要如何解析2022-09-09
在开发过程中,配置文件是少不了的,而且配置文件是有专门的格式的,比如:ini, yaml, toml 等等。而对于 Python 而言,也都有相应的库来解析相应格式的文件,下面我们来看看 ini 文件要如何解析2022-09-09
一文带你精通Python中*args和**kwargs的应用技巧
如果能在Python中创建适应不同场景的函数,而无需每次都重写它们,会使得操作简洁方便,这就是*args和**kwargs的魔力所在,下面我们就来看看它们的具体一些应用技巧吧2024-03-03 这篇文章主要给大家介绍了关于Python学习笔记之视频人脸检测识别的相关资料,文中通过示例代码以及图文介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-03-03
这篇文章主要给大家介绍了关于Python学习笔记之视频人脸检测识别的相关资料,文中通过示例代码以及图文介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-03-03 今天小编就为大家分享一篇python执行CMD指令,并获取返回的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇python执行CMD指令,并获取返回的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 本篇文章给大家分享了通过Python对Windows服务进行监控的实例代码,对此有兴趣的朋友可以学习参考下。2018-02-02
本篇文章给大家分享了通过Python对Windows服务进行监控的实例代码,对此有兴趣的朋友可以学习参考下。2018-02-02 在数据处理和分析中,将文本文件中的数据转换为三维矩阵是一个常见的任务,本文将详细介绍如何使用Python实现这一任务,感兴趣的小伙伴可以了解下2024-01-01
在数据处理和分析中,将文本文件中的数据转换为三维矩阵是一个常见的任务,本文将详细介绍如何使用Python实现这一任务,感兴趣的小伙伴可以了解下2024-01-01
详解windows python3.7安装numpy问题的解决方法
这篇文章主要介绍了windows python3.7安装numpy问题的解决方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-08-08 这篇文章主要为大家详细介绍了python3利用Axes3D库画3D模型图,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-03-03
这篇文章主要为大家详细介绍了python3利用Axes3D库画3D模型图,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-03-03 这篇文章主要介绍了20行Python代码实现视频字符化功能,本文通过实例代码截图的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-04-04
这篇文章主要介绍了20行Python代码实现视频字符化功能,本文通过实例代码截图的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-04-04
Python读取txt文件数据的方法(用于接口自动化参数化数据)
这篇文章主要介绍了Python读取txt文件数据的方法(用于接口自动化参数化数据),需要的朋友可以参考下2018-06-06










最新评论