
一文搞懂正则表达式基础语法以及如何应用
一、正则表达式
1、基本介绍
▶ 概述
- 一个正则表达式,就是用某种模式去匹配字符串的一个公式。很多人因为它们看上去比较古怪而且复杂所以不敢去使用,不过,经过练习后就觉得这些复杂的表达式写起来还是相当简单的, 而且, 一旦你弄懂它们,你就能把数小时辛苦而且易错的文本处理工作缩短在几分钟(甚至几秒钟)内完成。
- 正则表达式不是只有java才有,实际上很多编程语言都支持正则表达式进行字符串操作!
▶ 快速入门
public class RegTheory {
public static void main(String[] args) {
//目标:匹配所有四个数字
String content = "2002fsd ke ire i2222 ";
//1. \\d 表示一个任意的数字
String regStr = "(\\d\\d)(\\d\\d)";
//2. 创建模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(regStr);
//3. 创建匹配器
//说明:创建匹配器 matcher, 按照 正则表达式的规则 去匹配 content 字符串
Matcher matcher = pattern.matcher(content);
//4. 开始匹配
while (matcher.find()) {
System.out.println("找到: " + matcher.group(0));
System.out.println("第 1 组()匹配到的值=" + matcher.group(1));
System.out.println("第 2 组()匹配到的值=" + matcher.group(2));
}
}
}▶ 底层源码
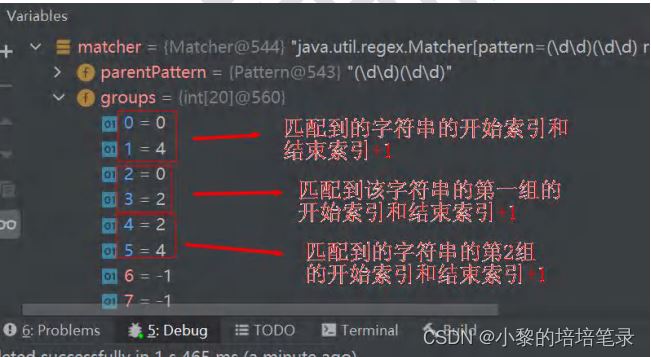
matcher.find() 完成的任务 (考虑分组),{什么是分组,比如 (\d\d)(\d\d) ,正则表达式中有() 表示分组,第 1 个()表示第 1 组,第 2 个()表示第 2 组...}
1. 根据指定的规则 , 定位满足规则的子字符串 ( 比如 (20)(02))
2. 找到后,将 子字符串的开始的索引记录到 matcher 对象的属性 int[ ] groups;
▷ groups[0] = 0 , 把该子字符串的结束的索引+1 的值记录到 groups[1] = 4
▷ 记录 1 组 () 匹配到的字符串 groups[2] = 0 groups[3] = 2
▷ 记录 2 组 () 匹配到的字符串 groups[4] = 2 groups[5] = 4
▷ 如果有更多的分组.....
3. 同时记录 oldLast 的值为 子字符串的结束的 索引 +1 的值即 16, 即下次执行 find 时,就从 16 开始匹配。
▶ matcher.group(0) 分析
public String group(int group) {
if (first < 0){
throw new IllegalStateException("No match found");
}
if (group < 0 || group > groupCount()){
throw new IndexOutOfBoundsException("No group " + group);
}
if ((groups[group*2] == -1) || (groups[group*2+1] == -1)){
return null;
}
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}根据 groups[0]=16 和 groups[1]=20 的记录的位置,从 content 开始截取子字符串返回
就是 [16,20) 包含 16 但是不包含索引为 20 的位置 如果再次指向 find 方法 . 仍然安上面分析来执行。
▶ 小结
1. 如果正则表达式有() 即分组
2. 取出匹配的字符串规则如下
3. group(0) 表示匹配到的子字符串
4. group(1) 表示匹配到的子字符串的第一组字串
5. group(2) 表示匹配到的子字符串的第 2 组字串
6. ... 但是分组的数不能越界.
2、正则表达式语法
▶ 基本介绍
如果要想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
①限定符,②选择匹配符,③分组组合和反向引用符,④特殊字符,⑤字符匹配符,⑥定位符
▶ 元字符(Metacharacter)-转义号
符号说明: 在我们使用正则表达式去检索某些特殊字符的时候,需要用到转义符号。则检索不到结果,甚至会报错的。 案例:用$ 去匹配 “abc$(" 会怎样?
在Java的正则表达式中,两个\\ 代表其他语言中的一个\
需要用到转义符号的字符有以下 : " . * + () $ / \ ? [ ] ^ { } "
二、正则语法
1、字符匹配符、选择匹配符
▶ 基本介绍


▶ 代码实现
String content = "a11c8abc _ABCy @"; String regStr = "[a-z]"; //匹配 a-z 之间任意一个字符 String regStr = "[A-Z]"; //匹配 A-Z 之间任意一个字符 String regStr = "abc"; //匹配 abc 字符串[默认区分大小写] String regStr = "(?i)abc"; //匹配 abc 字符串[不区分大小写] String regStr = "[0-9]"; //匹配 0-9 之间任意一个字符 String regStr = "[^a-z]"; //匹配 不在 a-z 之间任意一个字符 String regStr = "[^0-9]"; //匹配 不在 0-9 之间任意一个字符 String regStr = "[abcd]"; //匹配 在 abcd 中任意一个字符 String regStr = "\\D"; //匹配 不在 0-9 的任意一个字符 String regStr = "\\w"; //匹配 大小写英文字母, 数字,下划线 String regStr = "\\W"; //匹配 等价于 [^a-zA-Z0-9_] // \\s 匹配任何空白字符(空格,制表符等) String regStr = "\\s"; // \\S 匹配任何非空白字符 ,和\\s 刚好相反 String regStr = "\\S"; //. 匹配出 \n 之外的所有字符,如果要匹配.本身则需要使用 \\. String regStr = ".";
//当创建 Pattern 对象时,指定 Pattern.CASE_INSENSITIVE, 表示匹配是不区分字母大小写. Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);
▶ 选择匹配符

String content = "study hard"; String regStr = "t|a|r";
2、限定符
▶ 基本介绍
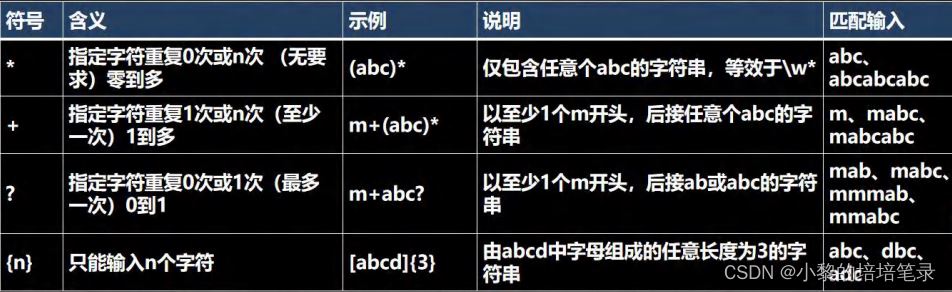

▶ 代码实现
String content = "a211111aaaaaahello";
String regStr = "a{3}"; // 表示匹配 aaa
String regStr = "1{4}"; // 表示匹配 1111
String regStr = "\\d{2}"; // 表示匹配 两位的任意数字字符
//细节:java 匹配默认贪婪匹配,即尽可能匹配多的
String regStr = "a{3,4}"; //表示匹配 aaa 或者 aaaa
String regStr = "1{4,5}"; //表示匹配 1111 或者 11111
String regStr = "\\d{2,5}"; //匹配 2 位数或者 3,4,5
//1+
String regStr = "1+"; //匹配一个 1 或者多个 1
String regStr = "\\d+"; //匹配一个数字或者多个数字
//1*
String regStr = "1*"; //匹配 0 个 1 或者多个 1
//遵守贪婪匹配
String regStr = "a1?"; //匹配 a 或者 a13、定位符
▶ 基本介绍

▶ 代码实现
String content = "123-abc sldkjfs s dfsjf"; String content = "123-abc"; //以至少 1 个数字开头,后接任意个小写字母的字符串 String regStr = "^[0-9]+[a-z]*"; //以至少 1 个数字开头, 必须以至少一个小写字母结束 String regStr = "^[0-9]+\\-[a-z]+$"; //表示匹配边界的 han[这里的边界是指:被匹配的字符串最后,也可以是空格的子字符串的后面] String regStr = "han\\b"; //和\\b 的含义刚刚相反 String regStr = "han\\B";
4、分组
▶ 基本介绍


▶ 代码实现
String content = "hello world s7789 nn1189han";
//命名分组: 即可以给分组取名
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";//匹配 4 个数字的字符串
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到=" + matcher.group(0));
System.out.println("第 1 个分组内容=" + matcher.group(1));
System.out.println("第 1 个分组内容[通过组名]=" + matcher.group("g1"));
System.out.println("第 2 个分组内容=" + matcher.group(2));
System.out.println("第 2 个分组内容[通过组名]=" + matcher.group("g2"));
}三、常用类
1、基本介绍
▶ 概述
▷ java.util.regex 包主要包括以下三个类Pattern 类、Matcher 类和 PatternSyntaxException ▷ Pattern 类
pattern 对象是一个正则表达式对象。Pattern 类没有公共构造方法。要创建一个Pattern 对象 调用其公共静态方法,它返回一个Pattern 对象。该方法接受一个正则表达式作为它的第一个参数,比如: Pattern r=Pattern.compile(pattern);
▷ Matcher类
Matcher对象是对输入字符串进行解释和匹配的引擎。 与Pattern 类一样, Matcher 也没有公共构造方法。 你需要调用 Pattern 对象的 matcher方法来获得一个 Matcher对象
▷ PatternSyntaxException
PatternSyntaxException 是一个非强制异常类, 它表示一个正则表达式模式中的语法错误。
▶ 代码实例
public class PatternMethod {
public static void main(String[] args) {
String content = "hello abc hello, 努力学习";
//String regStr = "hello";
String regStr = "hello.*";
boolean matches = Pattern.matches(regStr, content);
System.out.println("整体匹配= " + matches);
}
}▶ Matcher 常用类
public class MatcherMethod {
public static void main(String[] args) {
String content = "hello edu jack edutom hello smith hello edu edu";
String regStr = "hello";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println(matcher.start());
System.out.println(matcher.end());
System.out.println("找到: " + content.substring(matcher.start(), matcher.end()));
}
//整体匹配方法,常用于,去校验某个字符串是否满足某个规则
System.out.println("整体匹配=" + matcher.matches());
//完成如果 content 有 edu 替换成 努力学习
regStr = "edu";
pattern = Pattern.compile(regStr);
matcher = pattern.matcher(content);
//注意:返回的字符串才是替换后的字符串 原来的 content 不变化
String newContent = matcher.replaceAll("努力学习");
System.out.println("newContent=" + newContent);
System.out.println("content=" + content);
}
}2、分组、捕获、反向引用
▶ 基本介绍
1、分组
我们可以用圆括号组成一个比较复杂的匹配模式,那么一个圆括号的部分我们可以看作是一个子表达式(一个分组)。
2、捕获
把正则表达式中子表达式(分组匹配)的内容,保存到内存中以数字编号或显式命名的组里, 方便后面引用, 从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以以此类推,组0代表的是整个正则式。
3、反向引用
圆括号的内容被捕获后,可以在这个括号后被使用, 从而写出一个比较实用的匹配式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用\\分组号,外部反向引用$分组号。
▶ 经典案例
public class RegExp13 {
public static void main(String[] args) {
String content = "我....我要....学学学学....编程 java!";
//1. 去掉所有的.
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
content = matcher.replaceAll("");
//2. 去掉重复的字 我我要学学学学编程 java!
//(1) 使用 (.)\\1+
//(2) 使用 反向引用$1 来替换匹配到的内容
// 注意:因为正则表达式变化,所以需要重置 matcher
pattern = Pattern.compile("(.)\\1+");//分组的捕获内容记录到$1
matcher = pattern.matcher(content);
//使用 反向引用$1 来替换匹配到的内容
content = matcher.replaceAll("$1");
System.out.println("content=" + content);
}
}3、String 类中使用正则表达式
▶ 替换功能
String 类: public String replaceAll(String regex,String replacement)
▶ 判断功能
String 类: public boolean matches(String regex){} // 使用 Pattern 和 Matcher 类
▶ 分割功能
String 类: public String[] split(String regex)
▶ 代码实例
String content = "2000 年 5 月,JDK1.3、JDK1.4 和 J2SE1.3 相继发布。";
//使用正则表达式方式,将 JDK1.3 和 JDK1.4 替换成 JDK
content = content.replaceAll("JDK1\\.3|JDK1\\.4", "JDK");
System.out.println(content);//要求 验证一个 手机号, 要求必须是以 138 139 开头的
content = "13888889999";
if (content.matches("1(38|39)\\d{8}")) {
System.out.println("验证成功");
} else {
System.out.println("验证失败");
}//要求按照 # 或者 - 或者 ~ 或者 数字 来分割
content = "hello#abc-jack12smith~北京";
String[] split = content.split("#|-|~|\\d+");
for (String s : split) {
System.out.println(s);
}总结
到此这篇关于正则表达式基础语法以及如何应用的文章就介绍到这了,更多相关正则表达式基础语法及应用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

PHP preg_replace() 正则替换所有符合条件的字符串
PHP preg_replace() 正则替换,与Javascript 正则替换不同,PHP preg_replace() 默认就是替换所有符号匹配条件的元素2014-02-02 下面小编就为大家带来一篇关于正则表达式基本语法的应用详解(必看篇)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-08-08
下面小编就为大家带来一篇关于正则表达式基本语法的应用详解(必看篇)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-08-08 正则表达式也可以被当作是一门语言,入门时可能很吃力,不过一旦学会了就方便很多,在处理一些比较复杂的替换时,正则表达式就会发挥它的真正作用,本文整理了一些常用的正则,感兴趣的朋友可以了解下,或许对你有所帮助2013-01-01
正则表达式也可以被当作是一门语言,入门时可能很吃力,不过一旦学会了就方便很多,在处理一些比较复杂的替换时,正则表达式就会发挥它的真正作用,本文整理了一些常用的正则,感兴趣的朋友可以了解下,或许对你有所帮助2013-01-01 在javascript中,使用正则表达式匹配换行可能会遇到各种问题,下面就通过实例介绍一下如何实现此功能,对正则表达式匹配换行相关知识感兴趣的朋友一起学习吧2015-12-12
在javascript中,使用正则表达式匹配换行可能会遇到各种问题,下面就通过实例介绍一下如何实现此功能,对正则表达式匹配换行相关知识感兴趣的朋友一起学习吧2015-12-12 我们再开发项目时,总是要用到一些正则验证,就数手机号码规则比较难收集,这篇文章主要给大家介绍了关于最新最全的手机号验证正则表达式,需要的朋友可以参考下2022-02-02
我们再开发项目时,总是要用到一些正则验证,就数手机号码规则比较难收集,这篇文章主要给大家介绍了关于最新最全的手机号验证正则表达式,需要的朋友可以参考下2022-02-02 本文介绍了正则表达式的一些学习内容,以及在Javascript、PHP下如何使用正则表达式2014-08-08
本文介绍了正则表达式的一些学习内容,以及在Javascript、PHP下如何使用正则表达式2014-08-08 用正则取出html页面中script段落里的内容...2007-03-03
用正则取出html页面中script段落里的内容...2007-03-03 自动识别HTML的标记 替换连接...2006-07-07
自动识别HTML的标记 替换连接...2006-07-07 可以获取网页中所有的图片地址和链接地址的代码,好像一般用在获取网页中的资源地址时用的到2008-12-12
可以获取网页中所有的图片地址和链接地址的代码,好像一般用在获取网页中的资源地址时用的到2008-12-12 eregi_replace()中特殊字符的处理方法...2007-03-03
eregi_replace()中特殊字符的处理方法...2007-03-03










最新评论