
python读取eml文件并用正则表达式匹配邮箱的代码
今天接到一个需求有一个同事离职了,但是留下了非常多(2W多封)的邮件,我需要将他的邮件进行分类,只要邮件中以@xxx.com结尾的存放在文件夹中(下图名叫【是】的文件夹),否则放在另一个文件夹中(下图名叫【否】的文件夹)。 目录结构
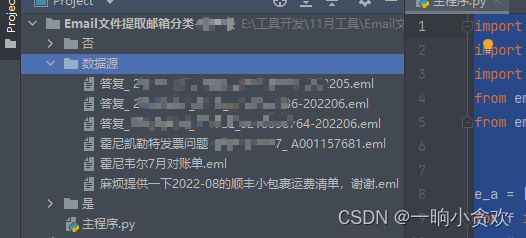
代码注意事项
import email(我发现是内置模块,不用安装) 下面是注意事项(就当是注释吧!!!!) 1、提取包含一下后缀的邮箱,我用了split(“@”),所以不用写 @e_a = [‘Honeywell.com’, ‘honeywell.com’, ‘garrettmotion.com’, ‘HONEYWELL.COM’, ‘resideo.com’]
2、提取,收件人、发件人、抄送人的邮箱(这个是可以不写的,但是我这个代码是借鉴的,没找到提取全部内容的函数,只找到提取内容的函数,所以加上了下面的代码)fjr = email.utils.parseaddr(msg.get(“from”))[1]
3、将eml文件内容与收件人、发件人、抄送人拼接,并且加 " " 间隔,不加会有些小问题
sjr = email.utils.parseaddr(msg.get(‘to’))[1]
csr = email.utils.parseaddr(msg.get(‘cc’))[1]
print(“发件人”, fjr)
print(“收件人”, sjr)
print(“抄送人”, csr)text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
4、正则匹配邮箱prog = re.compile(r’[a-zA-Z0-9_.±]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+')
5、移动文件 os.remove()
res = prog.findall(text)
完整代码
import email
import os
import re
from email import policy
from email.parser import BytesParser
e_a = ['Honeywell.com', 'honeywell.com', 'garrettmotion.com', 'HONEYWELL.COM', 'resideo.com']
for f in os.listdir("./数据源/"):
# print(f)
text = ""
with open("./数据源/" + f, 'rb') as fp:
msg = BytesParser(policy=policy.default).parse(fp)
fjr = email.utils.parseaddr(msg.get("from"))[1]
sjr = email.utils.parseaddr(msg.get('to'))[1]
csr = email.utils.parseaddr(msg.get('cc'))[1]
print("发件人", fjr)
print("收件人", sjr)
print("抄送人", csr)
if msg.get_body(preferencelist=('plain'))==None:
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
else:
text = msg.get_body(preferencelist=('plain')).get_content()
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
# print(text)
prog = re.compile(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
res = prog.findall(text)
for e in res:
res1 = e.split("@")[1]
if res1 in e_a:
print(f, "在")
ori = "./数据源/" + f
now = "./是/" + f
os.rename(ori, now)
break
else:
ori = "./数据源/" + f
now = "./否/" + f
os.rename(ori, now)
print(f, "不在")下面看看python正则表达式匹配邮箱
下面来看看python验证邮箱模式的例子。
(首先还是把环境列出来)
环境:python 2.7.10
1. 一次匹配多个邮箱的情况
下面的例子中:邮箱中可以出现 数字、大小写字母、下划线、和横线(-)
# -*- coding:utf-8 -*-
# 邮箱格式-正则表达式匹配
import re
# 一次匹配多个邮箱
str1 = 'aaf ssa@ss.net asdf asdb@163.com.cn asdf ss-a@ss.net asdf asdd.cba@163.com afdsaf'
reg_str1 = r'([\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+)'
mod = re.compile(reg_str1)
items = mod.findall(str1)
for item in items:
print item结果输出:

2. 一次匹配一个
这种情况,常见在登录界面用户名为邮箱时, 此时一个字符串只有一个 邮箱
# 只匹配一个
str2 = 'ssa_a-c@ss.net.cn'
reg_str2 = r'(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)'
mod = re.compile(reg_str2)
items = mod.findall(str2)
for item in items:
print item结果输出:
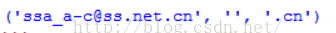
到此这篇关于python读取eml文件并用正则匹配邮箱的文章就介绍到这了,更多相关python读取eml文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了解决Django Haystack全文检索为空的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05
这篇文章主要介绍了解决Django Haystack全文检索为空的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05 在使用Python字典的过程中,如果没有key就会自动报错,这时就需要python中defaultdict函数发挥作用。defaultdict是Python内建dict类的一个子类,功能与dict相同,但可以产生一个带有默认值的dict,如果key不存在,就会返回默认值2022-10-10
在使用Python字典的过程中,如果没有key就会自动报错,这时就需要python中defaultdict函数发挥作用。defaultdict是Python内建dict类的一个子类,功能与dict相同,但可以产生一个带有默认值的dict,如果key不存在,就会返回默认值2022-10-10 这篇文章主要介绍了Python列表list的详细用法介绍,列表(list)作为Python中基本的数据结构,是存储数据的容器,相当于其它语言中所说的数组2022-07-07
这篇文章主要介绍了Python列表list的详细用法介绍,列表(list)作为Python中基本的数据结构,是存储数据的容器,相当于其它语言中所说的数组2022-07-07 Dash 是一个用于构建基于 Web 的应用程序的 Python 库,无需 JavaScript 。本文将利用Dash编写一个简单的Web汇率计算器,感兴趣的可以了解一下2022-08-08
Dash 是一个用于构建基于 Web 的应用程序的 Python 库,无需 JavaScript 。本文将利用Dash编写一个简单的Web汇率计算器,感兴趣的可以了解一下2022-08-08 这篇文章主要为大家详细介绍了20个被低估的Python性能优化技巧并附上了实测数据,文中的示例代码简洁易懂,有需要的小伙伴可以参考一下2025-03-03
这篇文章主要为大家详细介绍了20个被低估的Python性能优化技巧并附上了实测数据,文中的示例代码简洁易懂,有需要的小伙伴可以参考一下2025-03-03 路径规划中包括步行、公交、驾车、骑行等不同方式,今天借助高德地图web服务api,实现出行路线规划。感兴趣的可以了解下2021-06-06
路径规划中包括步行、公交、驾车、骑行等不同方式,今天借助高德地图web服务api,实现出行路线规划。感兴趣的可以了解下2021-06-06
Python-apply(lambda x: )的使用及说明
这篇文章主要介绍了Python-apply(lambda x: )的使用及说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要介绍了Python数据分析模块pandas用法,结合实例形式详细分析了Python数据分析模块pandas的功能、常见用法及相关操作注意事项,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了Python数据分析模块pandas用法,结合实例形式详细分析了Python数据分析模块pandas的功能、常见用法及相关操作注意事项,需要的朋友可以参考下2019-09-09 这篇文章主要介绍了pytorch 实现计算 kl散度 F.kl_div(),具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
这篇文章主要介绍了pytorch 实现计算 kl散度 F.kl_div(),具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05 本文主要介绍了Tkinter组件Entry的具体使用,Entry组件通常用于获取用户的输入文本,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-01-01
本文主要介绍了Tkinter组件Entry的具体使用,Entry组件通常用于获取用户的输入文本,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-01-01










最新评论