
BatchNorm2d原理、作用及pytorch中BatchNorm2d函数的参数使用
BN原理、作用



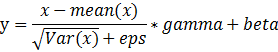
函数参数讲解
BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- 1.
num_features:一般输入参数的shape为batch_size*num_features*height*width,即为其中特征的数量,即为输入BN层的通道数; - 2.
eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5,避免分母为0; - 3.
momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数); - 4.
affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
一般来说pytorch中的模型都是继承nn.Module类的,都有一个属性trainning指定是否是训练状态,训练状态与否将会影响到某些层的参数是否是固定的,比如BN层或者Dropout层。
通常用model.train()指定当前模型model为训练状态,model.eval()指定当前模型为测试状态。
同时,BN的API中有几个参数需要比较关心的,一个是affine指定是否需要仿射,还有个是track_running_stats指定是否跟踪当前batch的统计特性。
容易出现问题也正好是这三个参数:trainning,affine,track_running_stats。
其中的affine指定是否需要仿射,也就是是否需要上面算式的第四个,如果affine=False则γ=1,β=0,并且不能学习被更新。一般都会设置成affine=True。
trainning和track_running_stats,track_running_stats=True表示跟踪整个训练过程中的batch的统计特性,得到方差和均值,而不只是仅仅依赖与当前输入的batch的统计特性。
相反的,如果track_running_stats=False那么就只是计算当前输入的batch的统计特性中的均值和方差了。
当在推理阶段的时候,如果track_running_stats=False,此时如果batch_size比较小,那么其统计特性就会和全局统计特性有着较大偏差,可能导致糟糕的效果。
如果BatchNorm2d的参数track_running_stats设置False,那么加载预训练后每次模型测试测试集的结果时都不一样;track_running_stats设置为True时,每次得到的结果都一样。
running_mean和running_var参数是根据输入的batch的统计特性计算的,严格来说不算是“学习”到的参数,不过对于整个计算是很重要的。
BN层中的running_mean和running_var的更新是在forward操作中进行的,而不是在optimizer.step()中进行的,因此如果处于训练中泰,就算不进行手动step(),BN的统计特性也会变化。
model.train() #处于训练状态
for data , label in self.dataloader:
pred =model(data) #在这里会更新model中的BN统计特性参数,running_mean,running_var
loss=self.loss(pred,label)
#就算不进行下列三行,BN的统计特性参数也会变化
opt.zero_grad()
loss.backward()
opt.step()这个时候,要用model.eval()转到测试阶段,才能固定住running_mean和running_var,有时候如果是先预训练模型然后加载模型,重新跑测试数据的时候,结果不同,有一点性能上的损失,这个时候基本上是training和track_running_stats设置的不对。
如果使用两个模型进行联合训练,为了收敛更容易控制,先预训练好模型model_A,并且model_A内还有若干BN层,后续需要将model_A作为一个inference推理模型和model_B联合训练,此时希望model_A中的BN的统计特性量running_mean和running_var不会乱变化,因此就需要将model_A.eval()设置到测试模型,否则在trainning模式下,就算是不去更新模型的参数,其BN都会变化,这将导致和预期不同的结果。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 本文将学习字符串数据类型相关知识,将讨论如何声明字符串数据类型,字符串数据类型与 ASCII 表的关系,字符串数据类型的属性,以及一些重要的字符串方法和操作,超级干货,不容错过2022-05-05
本文将学习字符串数据类型相关知识,将讨论如何声明字符串数据类型,字符串数据类型与 ASCII 表的关系,字符串数据类型的属性,以及一些重要的字符串方法和操作,超级干货,不容错过2022-05-05 这篇文章主要介绍了Python内置函数reversed()用法,结合实例形式分析了reversed()函数的功能及针对序列元素相关操作技巧与使用注意事项,需要的朋友可以参考下2018-03-03
这篇文章主要介绍了Python内置函数reversed()用法,结合实例形式分析了reversed()函数的功能及针对序列元素相关操作技巧与使用注意事项,需要的朋友可以参考下2018-03-03 今天小编就为大家分享一篇python实现图片二值化及灰度处理方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12
今天小编就为大家分享一篇python实现图片二值化及灰度处理方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12 本文主要介绍了python3中SQLMap安装教程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03
本文主要介绍了python3中SQLMap安装教程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03 这篇文章主要为大家详细介绍了使用python接入微信聊天机器人,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-06-06
这篇文章主要为大家详细介绍了使用python接入微信聊天机器人,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-06-06 这篇文章主要介绍了python列表的构造方法list(),python中没有数组这个概念,与之相应的是列表,本篇文章就来说说列表这个语法,下面文章详细内容,需要的小伙伴可以参考一下2022-03-03
这篇文章主要介绍了python列表的构造方法list(),python中没有数组这个概念,与之相应的是列表,本篇文章就来说说列表这个语法,下面文章详细内容,需要的小伙伴可以参考一下2022-03-03 这篇文章主要介绍了keras实现图像预处理并生成一个generator的案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06
这篇文章主要介绍了keras实现图像预处理并生成一个generator的案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 今天小编就为大家分享一篇利用python提取wav文件的mfcc方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇利用python提取wav文件的mfcc方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 这篇博客中,我们将详细分析如何使用 wxPython 构建一个简单的桌面应用程序,用于逐行加载并显示 HTML 文件的内容,并在加载完成后通过浏览器组件呈现最终页面,通过该应用,我们可以体验到逐行加载 HTML 内容的视觉效果,类似于模拟代码输入,需要的朋友可以参考下2024-11-11
这篇博客中,我们将详细分析如何使用 wxPython 构建一个简单的桌面应用程序,用于逐行加载并显示 HTML 文件的内容,并在加载完成后通过浏览器组件呈现最终页面,通过该应用,我们可以体验到逐行加载 HTML 内容的视觉效果,类似于模拟代码输入,需要的朋友可以参考下2024-11-11 这篇文章主要介绍了pandas按行按列遍历Dataframe的几种方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10
这篇文章主要介绍了pandas按行按列遍历Dataframe的几种方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10










最新评论