
怎样保存模型权重和checkpoint
概述
在pytorch中有两种方式可以保存推理模型,第一种是只保存模型的参数,比如parameters和buffers;另外一种是保存整个模型;
1.保存模型 - 权重参数
我们可以用torch.save()函数来保存model.state_dict();state_dict()里面包含模型的parameters&buffers;这种方法只保存模型中必要的训练参数。
你可以用pytorch中的pickle来保存模型;使用这种方法可以生成最直观的语法,并涉及最少的代码;这种方法的缺点是,序列化的数据被绑定到特定的类和保存模型时使用的确切的目录结构。
这样做的原因是pickle并不保存模型类本身。相反,它保存包含类的文件的路径,在加载期间使用;因此,当在其他项目中使用或重构后,您的代码可能以各种方式中断。
我们将探讨如何保存和加载模型进行推断的两种方法。
步骤:
(1)导入所有必要的库来加载我们的数据
(2)定义和初始化神经网络
(3)初始化优化器
(4)保存并通过state_dict加载模型
(5)保存并加载整个模型
1.1代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: Neural_Network_test
# @Create time: 2022/3/19 15:33
# 1.导入相关数据库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import functional as F
# 2.定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 3. 实例化神经网络
net = Net()
# 4. 实例化优化器
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 5. 保存模型参数
# Specify a path
PATH = "state_dict_model.pt"
# 6. 保存模型的参数字典:parameters and buffers
torch.save(net.state_dict(), PATH)
# 7. 实例化新的模型
model = Net()
# 8. 给新的实例加载之前的模型参数
model.load_state_dict(torch.load(PATH))
# 9. 设置模型为评估模式
model.eval()
注意(1):
pytorch中常用的惯例是将model.state_dict()保存为"state_dict_model.pt",即文件的格式一般是.pt或者.pth格式文件;注意load_state_dict加载的是一个字典,而不是路径。
注意(2):
模型参数在推理阶段一定要设置model.eval();这样可以让dropout和batchnorm失效,如果没设置推理模式,会得到不一样的结果。
2.保存模型 - 整个模型
将模型所有的内容都保存下来。
# Specify a path PATH = "entire_model.pt" # Save torch.save(net, PATH) # Load model = torch.load(PATH) model.eval()
3.保存模型 - checkpoints
我们按照checkpoints模式来保存模型,本质上就是按照字典的模式进行分门别类的保存,我们可以通过键值进行加载。
epoch:训练周期model_state_dict:模型可训练参数optimizer_state_dict:模型优化器参数loss:模型的损失函数
# Additional information
EPOCH = 5
PATH = "model.pt"
LOSS = 0.4
torch.save({
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
}, PATH)
保存和加载通用的检查点模型以进行推断或恢复训练,这有助于您从上一个地方继续进行。
当保存一个常规检查点时,您必须保存模型的state_dict之外的更多信息。
保存优化器的state_dict也很重要,因为它包含缓冲区和参数,随着模型的运行而更新。
您可能希望保存的其他项目是您离开的时期,最新记录的训练损失,外部torch.nn.嵌入层,以及更多,基于自己的算法
3.1代码
# 1.导入相关数据库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import functional as F
# 2. 定义神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 3. 实例化神经网络
net = Net()
# 4. 实例化优化器
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# Additional information
# 5. 定义超参数
EPOCH = 5
PATH = "model.pt"
LOSS = 0.4
# 6. 以checkpoints形式保存模型的相关数据
torch.save({
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
}, PATH)
# 7. 重新实例化一个模型
model = Net()
# 8. 实例化优化器
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 9. 加载以前的checkpoint
checkpoint = torch.load(PATH)
# 10. 通过键值来加载相关参数
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
# 11.设置推理模式
model.eval()
# - or -
model.train()
4.保存双模型
当保存有多个神经网络模型组成的神经网络时,比如GAN对抗模型,sequence-to-sequence序列到序列模型,或者一个组合模型,你必须为每一个模型保存状态字典state_dict()和其对应的优化器参数optimizer.state_dict();您还可以保存任何其他项目,可能会帮助您恢复训练,只需将它们添加到字典;为了加载模型,第一步是初始化神经网络模型和优化器,然后用torch.load()去加载checkpoint对应的数据,因为checkpoints是字典,所以我们可以通过键值进行查询导入;
4.1相关步骤
(1)导入所有相关的数据库
(2)定义和实例化神经网络模型
(3)初始化优化器
(4)保存多重模型
(5)加载多重模型
# 1.导入相关数据库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import functional as F
# 2. 定义神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 3. 实例化神经网络A,B
netA = Net()
netB = Net()
# 4. 实例化优化器A,B
optimizerA = optim.SGD(netA.parameters(), lr=0.001, momentum=0.9)
optimizerB = optim.SGD(netB.parameters(), lr=0.001, momentum=0.9)
# 5. 保存模型
# Specify a path to save to
PATH = "model.pt"
torch.save({
'modelA_state_dict': netA.state_dict(),
'modelB_state_dict': netB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
}, PATH)
# 6.重新实例化新的网络模型A,B
modelA = Net()
modelB = Net()
# 7. 重新实例化新的网络模型A,B
optimModelA = optim.SGD(modelA.parameters(), lr=0.001, momentum=0.9)
optimModelB = optim.SGD(modelB.parameters(), lr=0.001, momentum=0.9)
# 8. 将以前模型的参数重新加载到新的模型A,B中
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
# 9. 开启预测模式
modelA.eval()
modelB.eval()
# - or -
# 10.开启训练模式
modelA.train()
modelB.train()
5.机器学习流程图
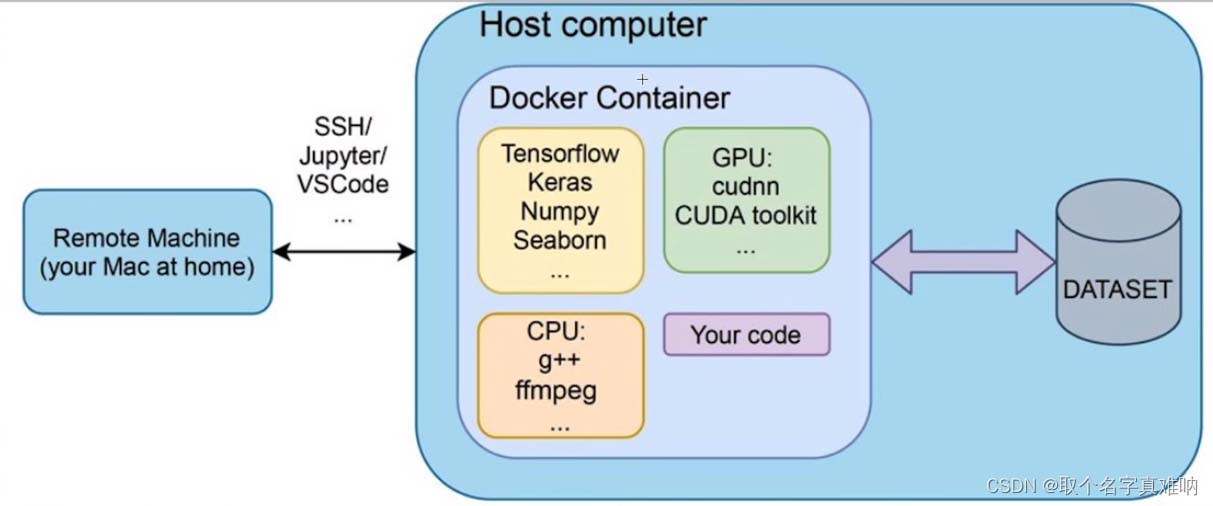
6.机器学习常用库

总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章

Python Diagrams创建高质量图表和流程图实例探究
Python Diagrams是一个强大的Python库,使创建这些图表变得简单且灵活,本文将深入介绍Python Diagrams,包括其基本概念、安装方法、示例代码以及一些高级用法,以帮助大家充分利用这一工具来创建令人印象深刻的图表2024-01-01 这篇文章主要介绍了Python实现多并发访问网站功能,结合具体实例形式分析了Python线程结合URL模块并发访问网站的相关操作技巧,需要的朋友可以参考下2017-06-06
这篇文章主要介绍了Python实现多并发访问网站功能,结合具体实例形式分析了Python线程结合URL模块并发访问网站的相关操作技巧,需要的朋友可以参考下2017-06-06
解决import tensorflow导致jupyter内核死亡的问题
这篇文章主要介绍了解决import tensorflow导致jupyter内核死亡的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-02-02
Win10 GPU运算环境搭建(CUDA10.0+Cudnn 7.6.5+pytroch1.2+tensorflow1.
熟悉深度学习的人都知道,深度学习是需要训练的,本文主要介绍了Win10 GPU运算环境搭建,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-09-09 甘特图已经发展成项目规划和跟踪的必备工具,本文主要介绍了Python使用Matplotlib绘制甘特图的实践,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-12-12
甘特图已经发展成项目规划和跟踪的必备工具,本文主要介绍了Python使用Matplotlib绘制甘特图的实践,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-12-12 如果需要在程序中周期性地进行某项操作,比如检测某种设备的状态,就会用到定时器,本文主要介绍了PyQt5中QTimer定时器的实例代码,感兴趣的可以了解一下2021-06-06
如果需要在程序中周期性地进行某项操作,比如检测某种设备的状态,就会用到定时器,本文主要介绍了PyQt5中QTimer定时器的实例代码,感兴趣的可以了解一下2021-06-06
基于K.image_data_format() == ''channels_first'' 的理解
这篇文章主要介绍了基于K.image_data_format() == 'channels_first' 的理解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 本文介绍了使用Python和QT5打包EXE文件,并在其中使用线程,打包时需要修改spec文件以加载资源文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-01-01
本文介绍了使用Python和QT5打包EXE文件,并在其中使用线程,打包时需要修改spec文件以加载资源文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-01-01
python sitk.show()与imageJ结合使用常见的问题
这篇文章主要介绍了python sitk.show()与imageJ结合使用常见的问题,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04
Python asyncore socket客户端开发基本使用教程
asyncore库是python的一个标准库,提供了以异步的方式写入套接字服务的客户端和服务器的基础结构,这篇文章主要介绍了Python asyncore socket客户端开发基本使用,需要的朋友可以参考下2022-12-12










最新评论