
pandas创建DataFrame对象失败的解决方法
更新时间:2023年01月17日 15:49:48 作者:无 羡ღ
本文主要介绍了pandas创建DataFrame对象失败的解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
报错代码
粉丝群一个小伙伴想pandas创建DataFrame对象,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错代码如下:
import pandas as pd
data = {'name': ['a', 'b'],
'Height': [140, 150, 160, 170],
'Weight': [40, 50, 60, 70]}
df = pd.DataFrame(data, index=list('abcd'))
print(df)
报错信息截图如下所示:
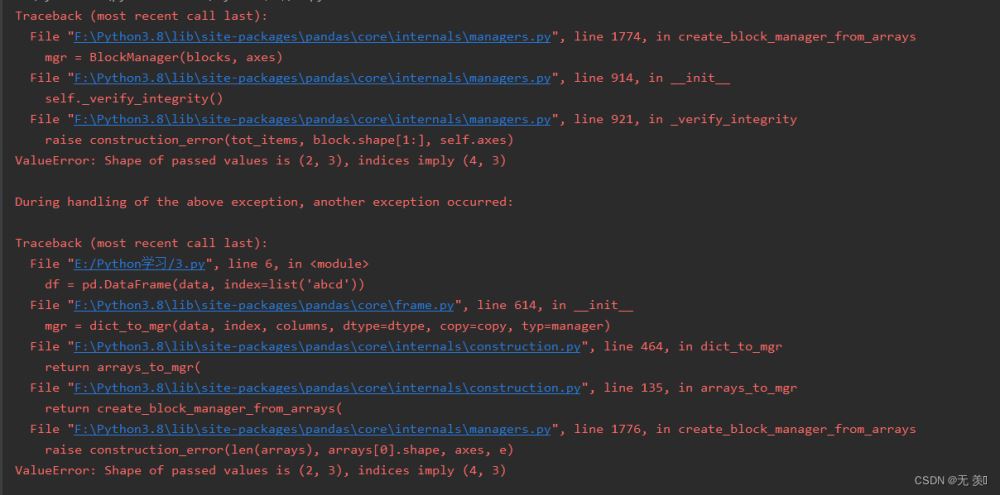
报错翻译
报错信息翻译如下:
值错误:传递值的形状为(2,3),索引表示(4,3)
报错原因
传递创建DataFrame的值和索引对不上,小伙伴们按下面正确的方法创建即可!!!
解决方法
每一个列表的长度都要相同
import pandas as pd
data = {'name': ['a', 'b','c','d'],
'Height': [155, 160, 175, 180],
'Weight': [50, 48, 52, 65]}
df = pd.DataFrame(data, index=list('abcd'))
print(df)
运行结果:

创建DataFrame对象的四种方法
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
1. list列表构建DataFrame
1)通过单列表创建
>>> import pandas as pd >>> >>> data = [0, 1, 2, 3, 4, 5] >>> df = pd.DataFrame(data) >>> print(df) 0 0 0 1 1 2 2 3 3 4 4 5 5 >>> print(type(df)) <class 'pandas.core.frame.DataFrame'>
2)通过嵌套列表创建
>>> import pandas as pd >>> >>> data = [['小明', 20], ['小红', 10]] >>> df = pd.DataFrame(data, columns=['name', 'age'], dtype=float) sys:1: FutureWarning: Could not cast to float64, falling back to object. This behavior is deprecated. In a future version, when a dtype is passed to 'DataFrame', either all columns will be cast to that dtype, or a TypeError will be raised >>> print(df) name age 0 小明 20.0 1 小红 10.0 >>> print(type(df)) <class 'pandas.core.frame.DataFrame'>
3)列表中嵌套字典(字典的键被用作列名,缺失则赋值为NaN):
>>> import pandas as pd
>>>
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> print(df)
A B C
0 1 2 NaN
1 3 4 5.0
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2. dict字典构建DataFrame
使用 dict 创建,dict中列表的长度必须相同, 如果传递了index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
1)普通创建:
>>> import pandas as pd
>>>
>>> data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
>>> df = pd.DataFrame(data)
>>> print(df)
name age
0 小红 10
1 小明 20
2 小白 30
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2)设置index创建:
>>> import pandas as pd
>>>
>>> data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
>>> df = pd.DataFrame(data, index=['老三', '老二', '老大'])
>>> print(df)
name age
老三 小红 10
老二 小明 20
老大 小白 30
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
3. ndarray创建DataFrame
1)普通方式创建:
>>> import pandas as pd
>>> import numpy as np
>>>
>>> data = np.random.randn(3, 3)
>>> print(data)
[[-1.9332579 0.70876382 -0.44291914]
[-0.26228642 -1.05200338 0.57390067]
[-0.49433001 0.70472595 -0.50749279]]
>>> print(type(data))
<class 'numpy.ndarray'>
>>> df = pd.DataFrame(data)
>>> print(df)
0 1 2
0 -1.933258 0.708764 -0.442919
1 -0.262286 -1.052003 0.573901
2 -0.494330 0.704726 -0.507493
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2)设置列名创建:
>>> import pandas as pd
>>> import numpy as np
>>>
>>> data = np.random.randn(3, 3)
>>> print(data)
[[-0.22028147 0.62374794 -0.66210282]
[-0.71785439 -1.21004547 1.15663811]
[ 1.47843923 0.4385811 0.31931312]]
>>> print(type(data))
<class 'numpy.ndarray'>
>>> df = pd.DataFrame(data, columns=list("ABC"))
>>> print(df)
A B C
0 -0.220281 0.623748 -0.662103
1 -0.717854 -1.210045 1.156638
2 1.478439 0.438581 0.319313
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
4. Series创建DataFrame
>>> import pandas as pd
>>>
>>> data = {'A': pd.Series(1, index=list(range(4)), dtype='float32'),
... 'B': pd.Series(2, index=list(range(4)), dtype='float32'),
... 'C': pd.Series(3, index=list(range(4)), dtype='float32')
... }
>>> df = pd.DataFrame(data)
>>> print(df)
A B C
0 1.0 2.0 3.0
1 1.0 2.0 3.0
2 1.0 2.0 3.0
3 1.0 2.0 3.0
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
帮忙解决
到此这篇关于pandas创建DataFrame对象失败的解决方法的文章就介绍到这了,更多相关pandas创建DataFrame对象失败内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了关于Numpy之repeat、tile的用法总结,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了关于Numpy之repeat、tile的用法总结,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06 这篇文章主要为大家详细介绍了Python如何实现多个圆检测和圆中圆的检测,文中的实现方法讲解详细,具有一定的借鉴价值,需要的可以参考一下2022-11-11
这篇文章主要为大家详细介绍了Python如何实现多个圆检测和圆中圆的检测,文中的实现方法讲解详细,具有一定的借鉴价值,需要的可以参考一下2022-11-11
Python如何将两个三维模型(obj)合成一个三维模型(obj)
这篇文章主要介绍了Python如何将两个三维模型(obj)合成一个三维模型(obj)问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-06-06 这篇文章主要为大家详细介绍了python实现邮箱发送信息,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-08-08
这篇文章主要为大家详细介绍了python实现邮箱发送信息,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-08-08 这篇文章主要为大家介绍了Python的异常处理机制,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12
这篇文章主要为大家介绍了Python的异常处理机制,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12 这篇文章主要介绍了python常规方法实现数组的全排列,实例分析了全排列的概念及Python常规实现技巧,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了python常规方法实现数组的全排列,实例分析了全排列的概念及Python常规实现技巧,需要的朋友可以参考下2015-03-03 计算机在开发过程中,代码越写越多,也就越难以维护,所以为了编写可维护的代码,我们会把函数进行分组,放在不同的文件里。在python里,一个.py文件就是一个模块2019-10-10
计算机在开发过程中,代码越写越多,也就越难以维护,所以为了编写可维护的代码,我们会把函数进行分组,放在不同的文件里。在python里,一个.py文件就是一个模块2019-10-10 这篇文章主要介绍了Python如何给你的程序做性能测试,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07
这篇文章主要介绍了Python如何给你的程序做性能测试,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07 XPath 使用路径表达式来选取HTML/ XML 文档中的节点或节点集,节点是通过沿着路径 (path) 或者步 (steps) 来选取的,本文将给大家介绍Python使用xpath对解析内容进行数据提取的方法,需要的朋友可以参考下2024-05-05
XPath 使用路径表达式来选取HTML/ XML 文档中的节点或节点集,节点是通过沿着路径 (path) 或者步 (steps) 来选取的,本文将给大家介绍Python使用xpath对解析内容进行数据提取的方法,需要的朋友可以参考下2024-05-05 这篇文章主要介绍了Python通过文本和图片生成词云图,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-05-05
这篇文章主要介绍了Python通过文本和图片生成词云图,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-05-05










最新评论