
Python实现有趣的亲戚关系计算器
每年的春节,都会有一些自己几乎没印象但父母就是很熟的亲戚,关系凌乱到你自己都说不清。
今年趁着春节在家没事情干,正好之前知道有中国亲戚关系计算器,想着自己实现一下,特此记录。
介绍
由于本人能力有限,只完成了基本功能....
需求
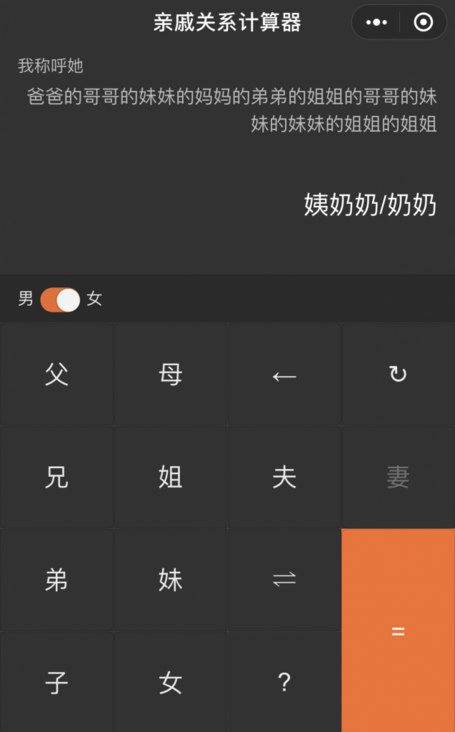
计算亲戚关系链得出我应该怎么称呼的结果
数据定义
1.定义关系字符和修饰符
【关系】f:父,m:母,h:夫,w:妻,s:子,d:女,xb:兄弟,ob:兄,lb:弟,xs:姐妹,os:姐,ls:妹
【修饰符】 &o:年长,&l:年幼,#:隔断,[a|b]:并列
2.关系对应数据集合、关系过滤数据集合(data.json 和 filter.json)
原来参考的作者的关系过滤数据集合json有点问题,改了一下
filter 数据集的用途:比如 m,h 是我的妈妈 的丈夫就是爸爸,也就是 f。 filter 的作用是去重和简化,需要把 exp 用 str 进行替换
算法实现
需要解决的情况基本有以下三种:
- 我的爸爸 = 爸爸,
- 我的哥哥的弟弟 = 自己/弟弟/哥哥,
- 我的哥哥的老公 = ?
分析
三种结果:1.单结果 2.多结果 3.错误提示 ,那么我们的算法要兼容以上三种情况,下面我们来一步步实现。
算法主要函数一:transformTitleToKey
该函数主要负责将文字转换成关系符号
# 将文字转换成关系符号
def transformTitleToKey(text):
result = text.replace("的", ",").replace("我", "").replace("爸爸", "f").replace("父亲", "f").replace("妈妈","m").replace("母亲", "m").replace("爷爷","f,f").replace("奶奶", "f,m").replace("外公", "m,f").replace("姥爷", "m,f").replace("外婆", "m,m").replace("姥姥", "m,m").replace("老公","h").replace("丈夫", "h").replace("老婆", "w").replace("妻子", "h").replace("儿子", "s").replace("女儿", "d").replace("兄弟", "xd").replace("哥哥", "ob").replace("弟弟","lb").replace("姐妹","xs").replace("姐姐", "os").replace("妹妹", "ls").strip(",")
return result这里简化了原参考作者的写法,更 简单(不是) 符合计算器设定
算法主要函数二:FilteHelper
该函数主要负责去重和简化
# 去重和简化
def FilteHelper(text):
result = text
filterName = '/filter.json' # filter.json文件路径
if not os.path.isfile(filterName):
return "filterName文件不存在"
with open(filterName, "r") as f:
obj = list(ijson.items(f, 'filter'))
for i in range(len(obj[0])):
users = obj[0][i]['exp']
if users == result:
return obj[0][i]['str']
elif re.match(obj[0][i]['exp'], result): # 符合正则
result1 = re.findall(obj[0][i]['exp'], result) # 返回string中所有与pattern匹配的全部字符串,返回形式为数组
print(result1)
a = 0
result2 = ""
if len(result1)>1:
try:
for i in len(result1):
result = result.replace("$" + str(a + 1), result1[a])
a = a + 1
if result.find("#") != -1:
result_l = result
resultList = list(set(result_l.split("#"))) # # 是隔断符,所以分割文本
for key in resultList:
result = FilteHelper(key.strip(","))
if (result.find("#") == -1): # 当关系符号不含#时加入最终结果中
result2 = result2 + result
return result2
else:
return text
except Exception as e:
return text
else:
return str(result1).replace("[\'", "").replace("\']", "")
elif re.match(obj[0][i]['exp'], strInsert(result, 0, ',')): # 符合正则
result1 = re.findall(obj[0][i]['exp'], strInsert(result, 0, ',')) # 返回string中所有与pattern匹配的全部字符串,返回形式为数组
a = 0
result2 = ""
if len(result1)>1:
try:
for i in len(result1):
result = result.replace("$" + str(a + 1), result1[a])
a = a + 1
if result.find("#") != -1:
result_l = result
resultList = list(set(result_l.split("#"))) # # 是隔断符,所以分割文本
for key in resultList:
result = FilteHelper(key.strip(","))
if (result.find("#") == -1): # 当关系符号不含#时加入最终结果中
result2 = result2 + result
return result2
else:
return text
except Exception as e:
return text
else:
return str(result1).replace("[\'", "").replace("\']", "")
return text这里原参考作者解释的有点乱,我就以我个人见解参考着写了出来...能跑....有错欢迎指出
个人测试单结果,多结果都能实现,建议多结果实现参考输出和代码详细理解
算法主要函数三:dataValueByKeys
该函数主要负责从数据源中查找对应 key 的结果
# 从数据源中查找对应 key 的结果
def dataValueByKeys(data_text):
if(isChinese(data_text)): # 判断是否含有中文,含有的是特殊回复
return data_text
dataName = '/data.json' # data.json文件路径
if not os.path.isfile(dataName):
return "data文件不存在"
fo = open(dataName, 'r', encoding='utf-8')
ID_Data = demjson.decode(fo.read())
fo.close()
try:
if ID_Data[data_text]:
cityID = ID_Data[data_text]
text = ""
for key in cityID:
text = text + key + '\\'
return text.strip("\\")
else:
return "未找到"
except Exception as e:
result = ""
resultList = FilteHelper(strInsert(data_text, 0, ',')).split(",")
for key in resultList:
result = result + dataValueByKeys(key)
return result输出与效果




基本达到效果
一些细节与已知问题
首先,是性别:如果‘我’是女性,那么‘我的父亲的儿子’可以为[‘哥哥’,‘弟弟’],而不可以包含‘我’。(上述代码没实现)
另外,关于夫妻关系:在正常情况下,男性称谓只可以有‘妻子’,女性称谓只可以有‘丈夫’。(上述代码已实现)
第三,多种可能:‘我的父亲的儿子’ 可以是[‘我’,‘哥哥’,‘弟弟’],再若是再往后计算,如‘我的父亲的儿子的儿子’ ,需要同时考虑‘我的儿子’,‘哥哥的儿子’,‘弟弟的儿子’这三种可能。(上述代码已实现)
已知问题:某些涉及自己的多重可能还存在莫名BUG
以上就是Python实现有趣的亲戚关系计算器的详细内容,更多关于Python亲戚关系计算器的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了用python写一个抽奖程序,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-05-05
这篇文章主要介绍了用python写一个抽奖程序,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-05-05 这篇文章主要给大家分享Python Flask + Redis 程序的练习,准备一个Python文件,名字为 app.py 提供一个web服务,可以访问地址,返回一个Hello Container World!并且记录访问的次数,下面来看看有趣的练习过程吧2022-01-01
这篇文章主要给大家分享Python Flask + Redis 程序的练习,准备一个Python文件,名字为 app.py 提供一个web服务,可以访问地址,返回一个Hello Container World!并且记录访问的次数,下面来看看有趣的练习过程吧2022-01-01
使用python requests模块发送http请求及接收响应的方法
用 python 编写 http request 消息代码时,建议用requests库,因为requests比urllib内置库更为简捷,requests可以直接构造get,post请求并发送,本文给大家介绍了使用python requests模块发送http请求及接收响应的方法,需要的朋友可以参考下2024-03-03 这篇文章主要介绍了Python入门教程之pycharm安装/基本操作/快捷键,Python是一门非常强大好用的语言,也有着易上手的特性,本文为入门教程,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了Python入门教程之pycharm安装/基本操作/快捷键,Python是一门非常强大好用的语言,也有着易上手的特性,本文为入门教程,需要的朋友可以参考下2023-04-04 今天小编就为大家分享一篇使用Python画出小人发射爱心的代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-09-09
今天小编就为大家分享一篇使用Python画出小人发射爱心的代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-09-09
解决python访问报错:jinja2.exceptions.TemplateNotFound:index.html
这篇文章主要介绍了解决python访问报错:jinja2.exceptions.TemplateNotFound:index.html,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-12-12 这篇文章主要介绍了python类属性和实例属性,实例分析了Python中返回一个返回值与多个返回值的方法,需要的朋友可以参考下2021-10-10
这篇文章主要介绍了python类属性和实例属性,实例分析了Python中返回一个返回值与多个返回值的方法,需要的朋友可以参考下2021-10-10 这篇文章主要给大家介绍了关于利用Python验证的50个常见正则表达式的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要给大家介绍了关于利用Python验证的50个常见正则表达式的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
Python中matplotlib库安装失败的经验总结(附pycharm配置anaconda)
最近根据领导布置的学习任务,开始学习python中的matplotlib,朋友告诉我这个很简单,然而刚踏入安装的门槛,就遇到了安装不成功的问题,下面这篇文章主要给大家介绍了关于Python中matplotlib库安装失败的经验总结,需要的朋友可以参考下2022-08-08 这篇文章主要为大家详细介绍了pygame实现贪吃蛇游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-10-10
这篇文章主要为大家详细介绍了pygame实现贪吃蛇游戏,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-10-10










最新评论