
使用Python抓取模板之家的CSS模板
更新时间:2015年03月16日 14:32:57 投稿:hebedich
本文给大家介绍的是使用Python抓取模板之家的CSS模板并打包成zip文件的代码,使用的是单线程,非常简单实用,这里分享给大家,有相同需求的小伙伴参考下吧。
Python版本是2.7.9,在win8上测试成功,就是抓取有点慢,本来想用多线程的,有事就罢了。模板之家的网站上的url参数与页数不匹配,懒得去做分析了,就自己改代码中的url吧。大神勿喷!
复制代码 代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# by ustcwq
# 2015-03-15
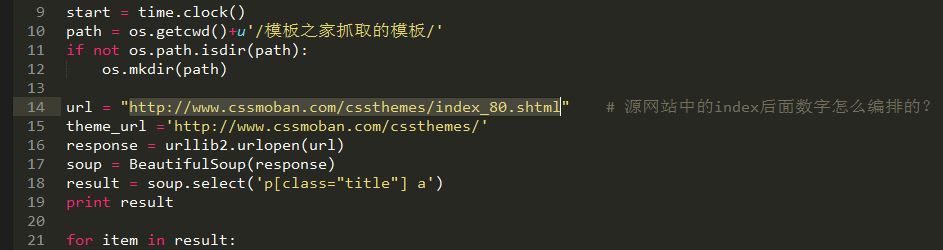
import urllib,urllib2,os,time
from bs4 import BeautifulSoup
start = time.clock()
path = os.getcwd()+u'/模板之家抓取的模板/'
if not os.path.isdir(path):
os.mkdir(path)
url = "http://www.cssmoban.com/cssthemes/index_80.shtml" # 源网站中的index后面数字怎么编排的?
theme_url ='http://www.cssmoban.com/cssthemes/'
response = urllib2.urlopen(url)
soup = BeautifulSoup(response)
result = soup.select('p[class="title"] a')
print result
for item in result:
link = item['href']
# down_name = item.text # 文件名称
new_url = theme_url+link.split('/')[-1]
response = urllib2.urlopen(new_url)
soup = BeautifulSoup(response)
result = soup.select('.btn a')
down_url = result[1]['href'] # 文件链接
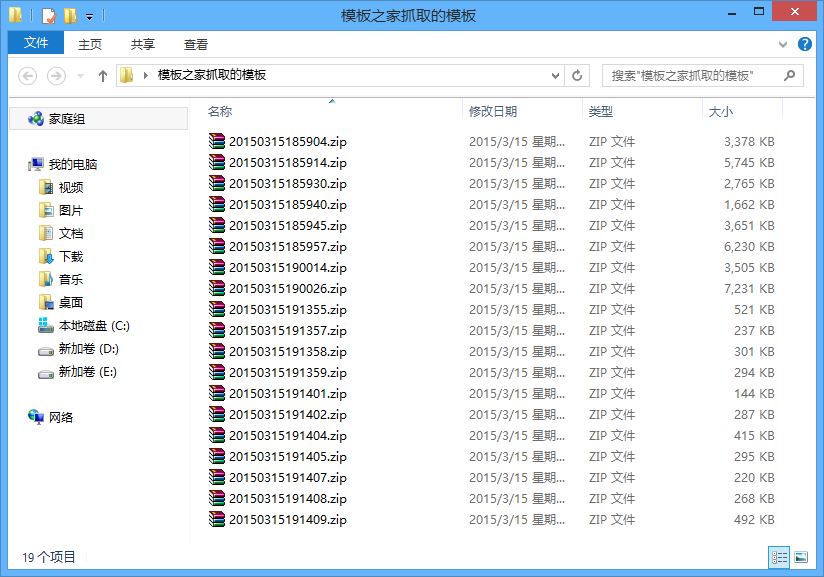
local = path+time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))+'.zip'
urllib.urlretrieve(down_url, local) # 远程保存函数
end = time.clock()
print u'模板抓取完成!'
print u'一共用时:',end-start,u'秒'
以上所述就是本文的全部内容了,希望大家能够喜欢。
相关文章
 这篇文章主要为大家介绍了Python Traceback异常代码排错利器使用指南,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01
这篇文章主要为大家介绍了Python Traceback异常代码排错利器使用指南,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01 今天小编就为大家分享一篇pytorch使用指定GPU训练的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08
今天小编就为大家分享一篇pytorch使用指定GPU训练的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08 本文主要介绍了python正则表达式re.group()用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-08-08
本文主要介绍了python正则表达式re.group()用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-08-08 这篇文章主要介绍了Python不同目录间进行模块调用的实现方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-01-01
这篇文章主要介绍了Python不同目录间进行模块调用的实现方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-01-01 这篇文章主要介绍了python查询sqlite数据表的方法,涉及Python操作SQLite数据库的基本技巧,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了python查询sqlite数据表的方法,涉及Python操作SQLite数据库的基本技巧,需要的朋友可以参考下2015-05-05 这篇文章主要介绍了Python编程生成随机用户名及密码的方法,结合实例形式分析了Python随机字符串的相关操作技巧,需要的朋友可以参考下2017-05-05
这篇文章主要介绍了Python编程生成随机用户名及密码的方法,结合实例形式分析了Python随机字符串的相关操作技巧,需要的朋友可以参考下2017-05-05 本篇文章主要介绍了Python控制多进程与多线程并发数,详细讲诉了进程和线程的区别,并介绍了处理方法,有需要的朋友可以了解一下。2016-10-10
本篇文章主要介绍了Python控制多进程与多线程并发数,详细讲诉了进程和线程的区别,并介绍了处理方法,有需要的朋友可以了解一下。2016-10-10 这篇文章主要介绍了Python八大排序算法速度实例对比,具有一定参考价值,需要的朋友可以参考下。2017-12-12
这篇文章主要介绍了Python八大排序算法速度实例对比,具有一定参考价值,需要的朋友可以参考下。2017-12-12 今天小编就为大家分享一篇python 搜索大文件的实例代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
今天小编就为大家分享一篇python 搜索大文件的实例代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
Centos 升级到python3后pip 无法使用的解决方法
今天小编就为大家分享一篇Centos 升级到python3后pip 无法使用的解决方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06










最新评论