
Python制作爬虫抓取美女图
今天我们就搞个爬虫把美图都给扒下来!我只是一个学习python的菜鸟,技术不可耻,技术是无罪的!!!
煎蛋:
先说说程序的流程:获取煎蛋妹子图URL,得到网页代码,提取妹子图片地址,访问图片地址并将图片保存到本地。Ready? 先让我们看看煎蛋妹子网页:
我们得到URL为:http://jandan.net/ooxx/page-1764#comments 1764就是页码, 首先我们要得到最新的页码,然后向前寻找,然后得到每页中图片的url。下面我们分析网站代码写出正则表达式!
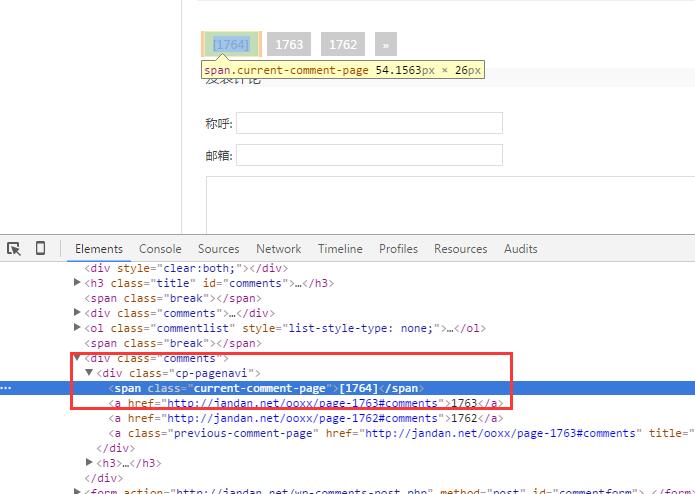
根据之前文章的方法我们写出如下函数getNewPage:
def __getNewPage(self):
pageCode = self.Get(self.__Url)
type = sys.getfilesystemencoding()
pattern = re.compile(r'<div .*?cp-pagenavi">.*?<span .*?current-comment-page">\[(.*?)\]</span>',re.S)
newPage = re.search(pattern,pageCode.decode("UTF-8").encode(type))
print pageCode.decode("UTF-8").encode(type)
if newPage != None:
return newPage.group(1)
return 1500不要问我为什么如果失败返回1500。。。 因为煎蛋把1500页之前的图片都给吃了。 你也可以返回0。接下来是图片的
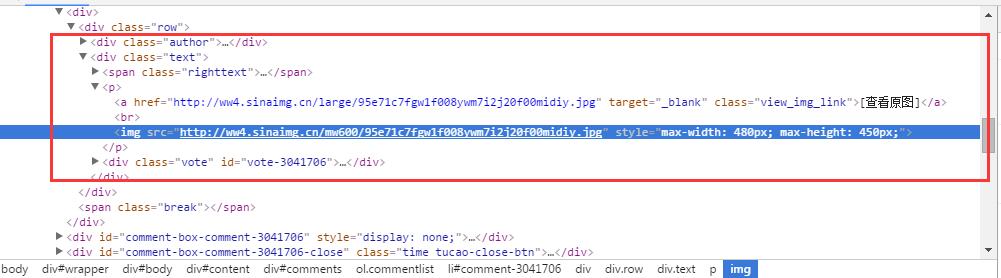
def __getAllPicUrl(self,pageIndex):
realurl = self.__Url + "page-" + str(pageIndex) + "#comments"
pageCode = self.Get(realurl)
type = sys.getfilesystemencoding()
pattern = re.compile('<p>.*?<a .*?view_img_link">.*?</a>.*?<img src="(.*?)".*?</p>',re.S)
items = re.findall(pattern,pageCode.decode("UTF-8").encode(type))
for item in items:
print item好了,得到了图片地址,接下来就是访问图片地址然后保存图片了:
def __savePics(self,img_addr,folder):
for item in img_addr:
filename = item.split('/')[-1]
print "正在保存图片:" + filename
with open(filename,'wb') as file:
img = self.Get(item)
file.write(img)当你觉得信心满满的时候,一定会有一盆冷水浇到你的头上,毕竟程序就是这样,考验你的耐性,打磨你的自信。你测试了一会儿,然后你发现你重启程序后再也无法获取最新页码,你觉得我什么也没动啊为什么会这样。别着急,我们将得到的网页代码打印出来看看:

看到了吧,是服务器感觉你不像浏览器访问的结果把你的ip给屏蔽了。 真是给跪了,辛辛苦苦码一年,屏蔽回到解放前!那么这个如何解决呢,答:换ip 找代理。接下来我们要改一下我们的HttpClient.py 将里面的opener设置下代理服务器。具体代理服务器请自行百度之,关键字:http代理 。 想找到一个合适的代理也不容易 自己ie Internet选项挨个试试,测试下网速。
# -*- coding: utf-8 -*-
import cookielib, urllib, urllib2, socket
import zlib,StringIO
class HttpClient:
__cookie = cookielib.CookieJar()
__proxy_handler = urllib2.ProxyHandler({"http" : '42.121.6.80:8080'})#设置代理服务器与端口
__req = urllib2.build_opener(urllib2.HTTPCookieProcessor(__cookie),__proxy_handler)#生成opener
__req.addheaders = [
('Accept', 'application/javascript, */*;q=0.8'),
('User-Agent', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)')
]
urllib2.install_opener(__req)
def Get(self, url, refer=None):
try:
req = urllib2.Request(url)
#req.add_header('Accept-encoding', 'gzip')
if not (refer is None):
req.add_header('Referer', refer)
response = urllib2.urlopen(req, timeout=120)
html = response.read()
#gzipped = response.headers.get('Content-Encoding')
#if gzipped:
# html = zlib.decompress(html, 16+zlib.MAX_WBITS)
return html
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''然后,就可以非常愉快的查看图片了。不过用了代理速度好慢。。。可以设置timeout稍微长一点儿,防止图片下载不下来!

好了,rosi的下篇文章再放!现在是时候上一波代码了:
# -*- coding: utf-8 -*-
import cookielib, urllib, urllib2, socket
import zlib,StringIO
class HttpClient:
__cookie = cookielib.CookieJar()
__proxy_handler = urllib2.ProxyHandler({"http" : '42.121.6.80:8080'})
__req = urllib2.build_opener(urllib2.HTTPCookieProcessor(__cookie),__proxy_handler)
__req.addheaders = [
('Accept', 'application/javascript, */*;q=0.8'),
('User-Agent', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)')
]
urllib2.install_opener(__req)
def Get(self, url, refer=None):
try:
req = urllib2.Request(url)
req.add_header('Accept-encoding', 'gzip')
if not (refer is None):
req.add_header('Referer', refer)
response = urllib2.urlopen(req, timeout=120)
html = response.read()
gzipped = response.headers.get('Content-Encoding')
if gzipped:
html = zlib.decompress(html, 16+zlib.MAX_WBITS)
return html
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''
def Post(self, url, data, refer=None):
try:
#req = urllib2.Request(url, urllib.urlencode(data))
req = urllib2.Request(url,data)
if not (refer is None):
req.add_header('Referer', refer)
return urllib2.urlopen(req, timeout=120).read()
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''
def Download(self, url, file):
output = open(file, 'wb')
output.write(urllib2.urlopen(url).read())
output.close()
# def urlencode(self, data):
# return urllib.quote(data)
def getCookie(self, key):
for c in self.__cookie:
if c.name == key:
return c.value
return ''
def setCookie(self, key, val, domain):
ck = cookielib.Cookie(version=0, name=key, value=val, port=None, port_specified=False, domain=domain, domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False)
self.__cookie.set_cookie(ck)
#self.__cookie.clear() clean cookie
# vim : tabstop=2 shiftwidth=2 softtabstop=2 expandtab
HttpClient
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from HttpClient import HttpClient
import sys,re,os
class JianDan(HttpClient):
def __init__(self):
self.__pageIndex = 1500 #之前的图片被煎蛋吞了
self.__Url = "http://jandan.net/ooxx/"
self.__floder = "jiandan"
def __getAllPicUrl(self,pageIndex):
realurl = self.__Url + "page-" + str(pageIndex) + "#comments"
pageCode = self.Get(realurl)
type = sys.getfilesystemencoding()
pattern = re.compile('<p>.*?<a .*?view_img_link">.*?</a>.*?<img src="(.*?)".*?</p>',re.S)
items = re.findall(pattern,pageCode.decode("UTF-8").encode(type))
for item in items:
print item
self.__savePics(items,self.__floder)
def __savePics(self,img_addr,folder):
for item in img_addr:
filename = item.split('/')[-1]
print "正在保存图片:" + filename
with open(filename,'wb') as file:
img = self.Get(item)
file.write(img)
def __getNewPage(self):
pageCode = self.Get(self.__Url)
type = sys.getfilesystemencoding()
pattern = re.compile(r'<div .*?cp-pagenavi">.*?<span .*?current-comment-page">\[(.*?)\]</span>',re.S)
newPage = re.search(pattern,pageCode.decode("UTF-8").encode(type))
print pageCode.decode("UTF-8").encode(type)
if newPage != None:
return newPage.group(1)
return 1500
def start(self):
isExists=os.path.exists(self.__floder)#检测是否存在目录
print isExists
if not isExists:
os.mkdir(self.__floder)
os.chdir(self.__floder)
page = int(self.__getNewPage())
for i in range(self.__pageIndex,page):
self.__getAllPicUrl(i)
if __name__ == '__main__':
jd = JianDan()
jd.start()
JianDan相关文章
 这篇文章主要为大家详细介绍了Matplotlib绘制子图的常用方式和技巧,文中的示例代码讲解详细,具有一定的学习价值,感兴趣的可以了解一下2023-07-07
这篇文章主要为大家详细介绍了Matplotlib绘制子图的常用方式和技巧,文中的示例代码讲解详细,具有一定的学习价值,感兴趣的可以了解一下2023-07-07 这篇文章主要介绍了python使用any判断一个对象是否为空的方法,并给出了改进的方法供大家对比参考,具有一定的借鉴价值,需要的朋友可以参考下2014-11-11
这篇文章主要介绍了python使用any判断一个对象是否为空的方法,并给出了改进的方法供大家对比参考,具有一定的借鉴价值,需要的朋友可以参考下2014-11-11 在pylons的文档中,有专门讲过如何添加自己的Middleware, 通过这些Middleware, 我们可以改变输入和输出。这也是WSGI(Web Server Gateway Interface)的优势和精髓所在,那么在pyramid中,我们如何添加Middleware呢2013-11-11
在pylons的文档中,有专门讲过如何添加自己的Middleware, 通过这些Middleware, 我们可以改变输入和输出。这也是WSGI(Web Server Gateway Interface)的优势和精髓所在,那么在pyramid中,我们如何添加Middleware呢2013-11-11 psutil是Python系统和进程工具库,它提供了一种跨平台的方式来获取系统信息、管理系统进程、监控系统性能、操作系统资源等,下面就跟随小编一起来学习psutil库的具体应用吧2024-01-01
psutil是Python系统和进程工具库,它提供了一种跨平台的方式来获取系统信息、管理系统进程、监控系统性能、操作系统资源等,下面就跟随小编一起来学习psutil库的具体应用吧2024-01-01
pytorch tensor按广播赋值scatter_函数的用法
这篇文章主要介绍了pytorch tensor按广播赋值scatter_函数的用法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06 字符串是 Python 中最常用的数据类型。我们可以使用引号来创建字符串,通过本篇文章给大家分享python字符串关键点相关资料,感兴趣的朋友一起学习吧2015-12-12
字符串是 Python 中最常用的数据类型。我们可以使用引号来创建字符串,通过本篇文章给大家分享python字符串关键点相关资料,感兴趣的朋友一起学习吧2015-12-12 这篇文章主要为大家介绍了Python高阶函数与函数式编程概念及使用实例探究,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12
这篇文章主要为大家介绍了Python高阶函数与函数式编程概念及使用实例探究,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12 这篇文章主要介绍了python开发简单的命令行工具实例的相关资料,需要的朋友可以参考下2023-02-02
这篇文章主要介绍了python开发简单的命令行工具实例的相关资料,需要的朋友可以参考下2023-02-02 这篇文章主要介绍了Python的Tornado框架异步编程入门实例,异步编程的思维与普通编程比起来有些不同,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python的Tornado框架异步编程入门实例,异步编程的思维与普通编程比起来有些不同,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了Python编程实现及时获取新邮件的方法,涉及Python实时查询邮箱及邮件获取相关操作技巧,需要的朋友可以参考下2017-08-08
这篇文章主要介绍了Python编程实现及时获取新邮件的方法,涉及Python实时查询邮箱及邮件获取相关操作技巧,需要的朋友可以参考下2017-08-08










最新评论