
深入理解python中的浅拷贝和深拷贝
在讲什么是深浅拷贝之前,我们先来看这样一个现象:
a = ['scolia', 123, [], ] b = a[:] b[2].append(666) print a print b

为什么我只对b进行修改,却影响到了a呢?看过我在之前的文章中就说过:序列中保存的都是内存的引用。
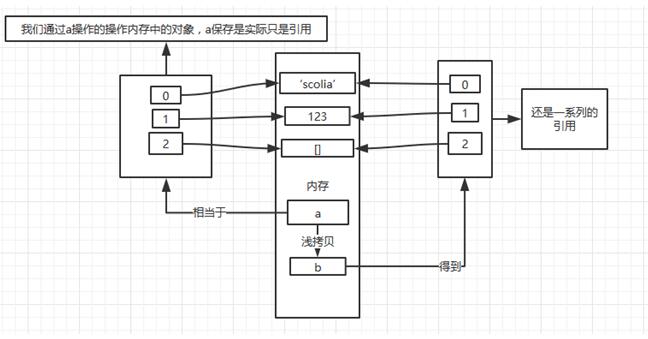
所以,当我们通过b去修改里面的空列表的时候,其实就是修改内存中的同一个对象,所以会影响到a。
a = ['scolia', 123, [], ] b = a[:] print id(a), id(a[0]), id(a[1]), id(a[2]) print id(b), id(b[0]), id(b[1]), id(b[2])

代码验证无误,所以虽然a和b是两个不同的对象,但是里面的引用都是一样的。这就是所谓新的对象,旧的内容。
但是,浅拷贝还不仅如此,看下面:
a = ['scolia', 123, [], ] b = a[:] b[1] = 666 print a print b

这又是怎么回事呢?
看过我在python变量赋值说明的同学会知道:对于字符串、数字等不可变的数据类型,修改就相当于重新赋值。在这里就相当于刷新引用。
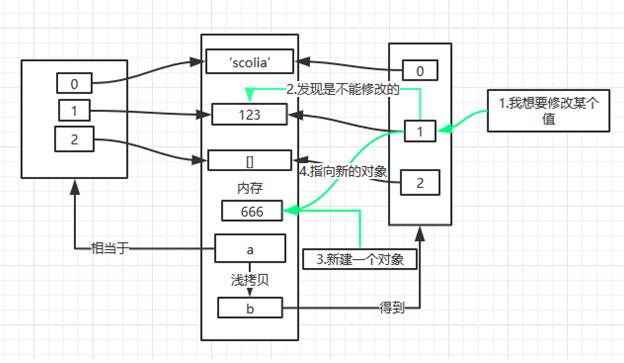
代码验证一下:
a = ['scolia', 123, [], ] b = a[:] b[1] = 666 print id(a), id(a[0]), id(a[1]), id(a[2]) print id(b), id(b[0]), id(b[1]), id(b[2])
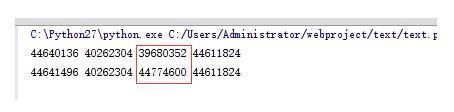
看来是正确的。
上面讲的这些就是浅拷贝,总结起来,浅拷贝只是拷贝了一系列引用,当我们在拷贝出来的对象对可修改的数据类型进行修改的时候,并没有改变引用,所以会影响原对象。而对不可修改的对象进行修改的是,则是新建了对象,刷新了引用,所以和原对象的引用不同,结果也就不同。
创建浅拷贝的方法:
1.切片操作
2.使用list()工厂函数新建对象。( b = list(a) )
那么深拷贝不就是将里面引用的对象重新创建了一遍并生成了一个新的一系列引用。
基本上是这样的,但是对于字符串、数字等不可修改的对象来说,重新创建一份似乎有点浪费内存,反正你到时要修改的时候都是新建对象,刷新引用的。所以还用原来的引用也无所谓,还能达到节省内存的目的。
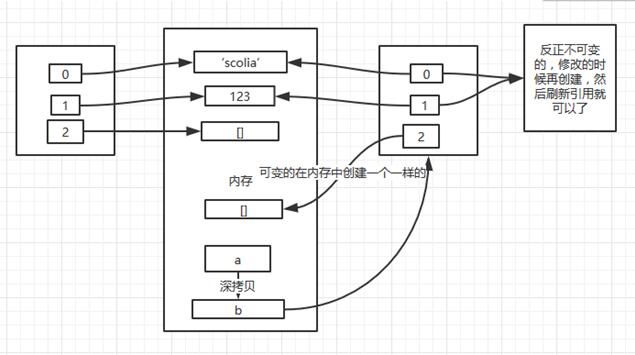
看下代码验证:
from copy import deepcopy a = ['scolia', 123, [], ] b = deepcopy(a) b[1] = 666 print id(a), id(a[0]), id(a[1]), id(a[2]) print id(b), id(b[0]), id(b[1]), id(b[2])
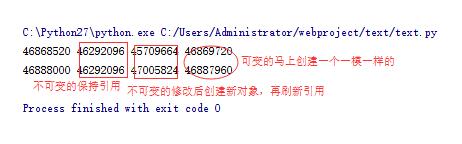
验证正确。
深拷贝的创建:
1.正如代码示例用一样,只能通过内置的copy模块的deepcopy()方法创建。
好了,关于深浅拷贝的问题就先说到这里,有什么错误或需要补充的以后会继续。
以上这篇深入理解python中的浅拷贝和深拷贝就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了Python之lxml安装失败的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了Python之lxml安装失败的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
python3使用urllib示例取googletranslate(谷歌翻译)
这篇文章主要介绍了使用urllib取googletranslate(谷歌翻译)的示例,通过这个谷歌翻译示例学习python3中urllib的使用方法,2014-01-01
python 使用第三方库requests-toolbelt 上传文件流的示例
这篇文章主要介绍了python 使用第三方库requests-toolbelt 上传文件流,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09 在软件开发中,循环依赖是一个常见的问题,尤其是在使用 Python 这样的动态语言时,循环依赖指的是两个或多个模块或组件相互依赖,形成一个闭环,本文将探讨 Python 中循环依赖的问题,并提供一些解决方案,需要的朋友可以参考下2024-06-06
在软件开发中,循环依赖是一个常见的问题,尤其是在使用 Python 这样的动态语言时,循环依赖指的是两个或多个模块或组件相互依赖,形成一个闭环,本文将探讨 Python 中循环依赖的问题,并提供一些解决方案,需要的朋友可以参考下2024-06-06 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。正则表达式是用于处理字符串的强大工具,它并不是Python的一部分。其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。2014-11-11
正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。正则表达式是用于处理字符串的强大工具,它并不是Python的一部分。其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。2014-11-11 在文件管理和数据处理中,批量修改文件名是一项常见且重要的任务,Python作为一种功能强大的编程语言,提供了丰富的库和工具来简化这一过程,本文将结合实际案例,详细介绍如何通过Python批量修改文件名,需要的朋友可以参考下2024-08-08
在文件管理和数据处理中,批量修改文件名是一项常见且重要的任务,Python作为一种功能强大的编程语言,提供了丰富的库和工具来简化这一过程,本文将结合实际案例,详细介绍如何通过Python批量修改文件名,需要的朋友可以参考下2024-08-08 今天小编就为大家分享一篇对Python中数组的几种使用方法总结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06
今天小编就为大家分享一篇对Python中数组的几种使用方法总结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06 这篇文章主要介绍了Python报错:对象不存在此属性的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了Python报错:对象不存在此属性的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05 这篇文章主要介绍了python机器学习理论与实战第六篇,支持向量机的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-01-01
这篇文章主要介绍了python机器学习理论与实战第六篇,支持向量机的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-01-01 Scala是一种多范式的编程语言,具有函数式编程和面向对象编程的特点,同时也能够与Java语言完美兼容,它拥有强大的类型推断、高阶函数、模式匹配等特性,使得代码更加简洁、灵活和易于维护,这篇文章主要介绍了Scala中使用Jsoup库处理HTML文档的案例分析,需要的朋友可以参考下2024-04-04
Scala是一种多范式的编程语言,具有函数式编程和面向对象编程的特点,同时也能够与Java语言完美兼容,它拥有强大的类型推断、高阶函数、模式匹配等特性,使得代码更加简洁、灵活和易于维护,这篇文章主要介绍了Scala中使用Jsoup库处理HTML文档的案例分析,需要的朋友可以参考下2024-04-04










最新评论