
锐龙AI Max+395如何打破迷你主机性能极限! 极摩客EVO-X2桌面Mini AI工作站评测
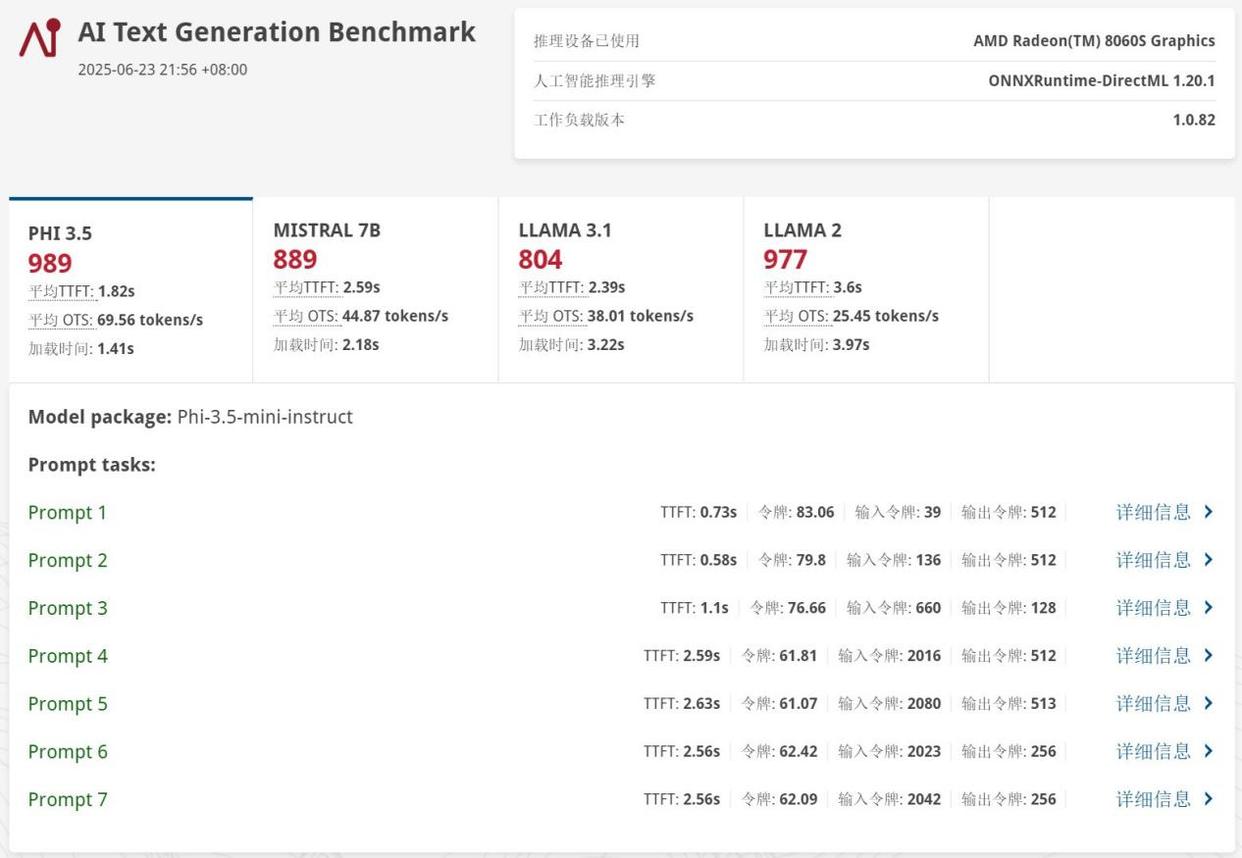
首先通过UL Procyon测试了Phi-3.5 4B、Mistral 7B、Llama 3.1 8B以及Llama 2 13B四款经典大语言模型,生成速度分别达到了69.56 tokens/s、44.87 tokens/s、38.01 tokens/s以及25.45 tokens/s,速度非常快。另外值得一提的是,即便是RTX 5060笔记本电脑GPU,因为其作为独立显卡也只有可怜的8GB显存,所以也无法正常运行参数量较大的Llama 2大模型,而Radeon 8060S不仅成功运行,且生成速度能够达到25.45 tokens/s,日常应用完全没有问题。此时,锐龙AI Max+ 395平台的独特优势就彻底显现出来了。
接下来我们通过LM Studio进行了15B及以下小参数量大语言模型和22B及以上大参数量大语言模型的测试。
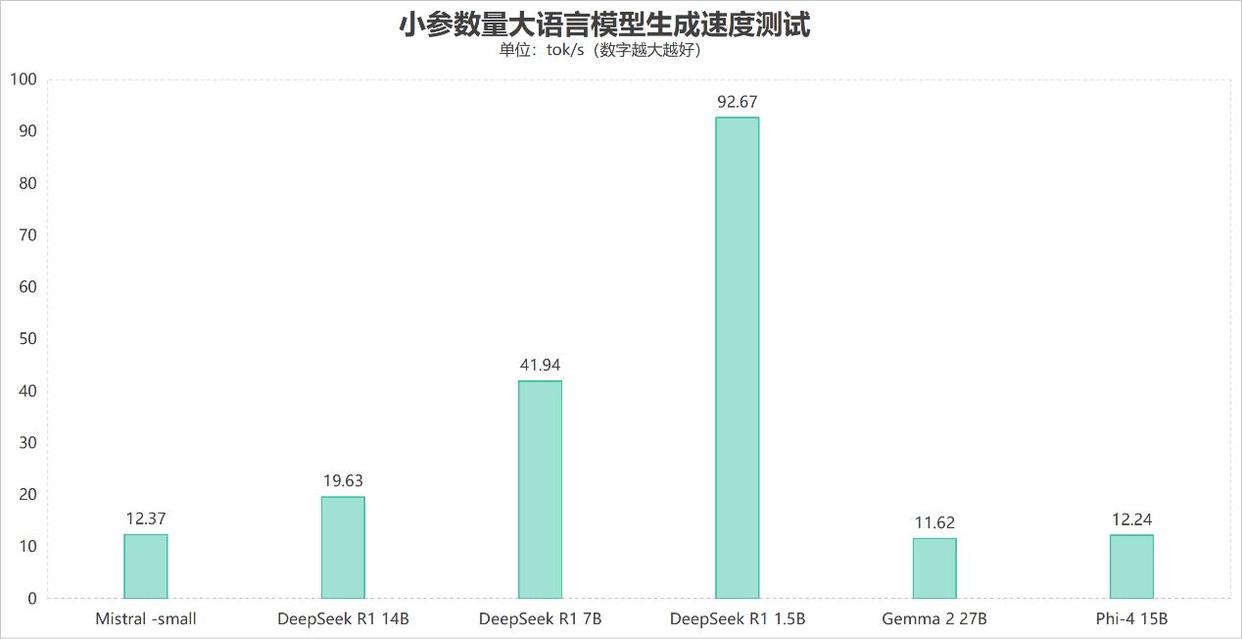
首先在各类小参数量稠密大模型测试中可以看到,锐龙AI Max+ 395表现非常出色,凭借内存分配带来的超大显存支持,即便是遇到BF16高精度的Mistral-small 24B以及Gemma 2 27B大模型,生成速度也分别达到了12.37 tokens/s和11.62 tokens/s,表现出色。而对于更高性能的DeepSeek R1 14B、Phi-4 15B,速度也能达到19.63 tokens/s和12.24 tokens/s;低精度的DeepSeek R1 7B生成速度更是达到了41.94 tokens/s,而DeepSeek R1 1.5B则达到了92.67 tokens/s,可见在面对小参数量大模型时,锐龙AI Max+ 395无论是面对高精度模型还是低精度模型,都能提供足够快的生成速度。
在面对大参数量大语言模型时,其实首要解决的问题不是能不能使用大模型,而是能不能正常加载大模型。就比如RTX 5060笔记本电脑GPU,虽然其性能比Radeon 8060S要强,但如果大模型参数量较大,前者大概率也过不了加载这一关,更别提进一步应用了。
从下图可以看到,我们在加载Qwen3-235B-A22B-IQ2_S的MoE混合大模型时,内存峰值占用高达63.6GB,如果没有128GB超大内存支持的话,加载这一关就过不了。
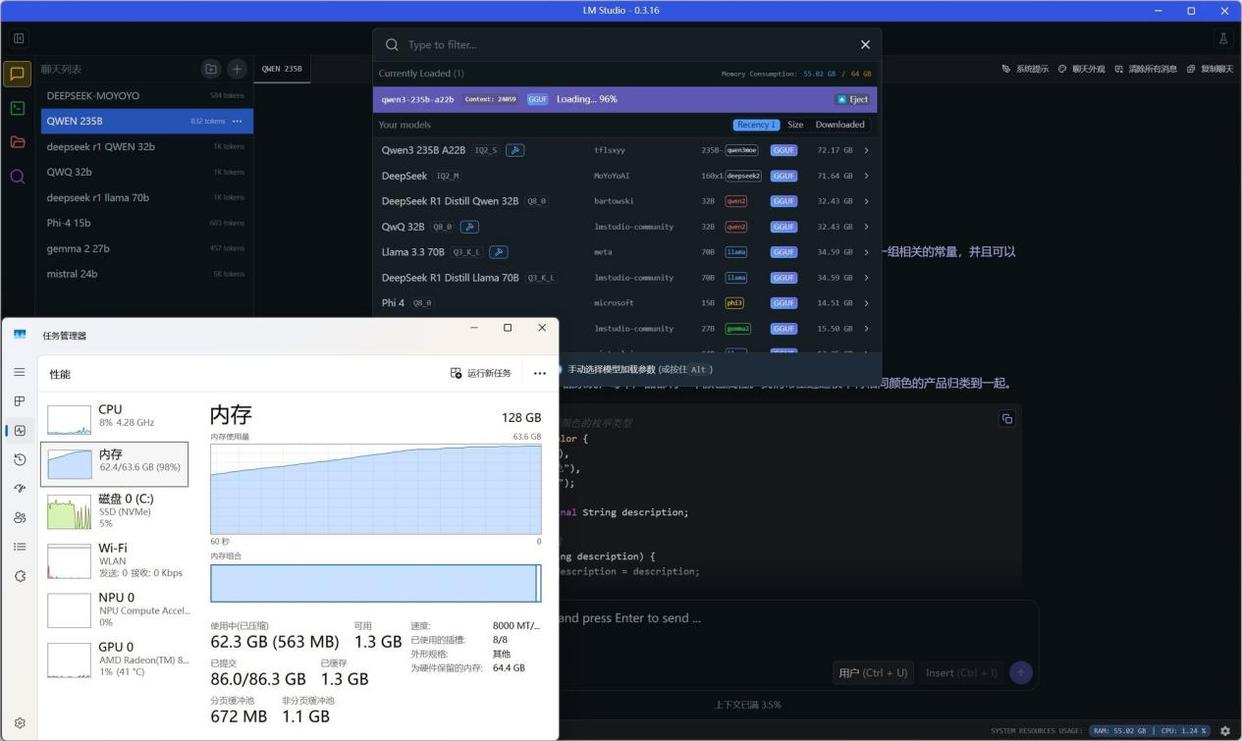
在各类大参数量大语言模型测试中,Qwen3-235B-A22B-IQ2_SMoE模型生成速度达到了14.72 tokens/s,表现出色;DeepSeek IQ2_M、DeepSeek R1 Distill Llama 70B大参数量稠密模型也能够正常运行,并且可以达到4.91 tokens/s和5.31 tokens/s的生成速度。而Q4量化版本的DeepSeek R1 Qwen 32B蒸馏模型以及QWQ 32B大模型生成速度分别可以达到9.71 tokens/s和9.79 tokens/s的生成速度。
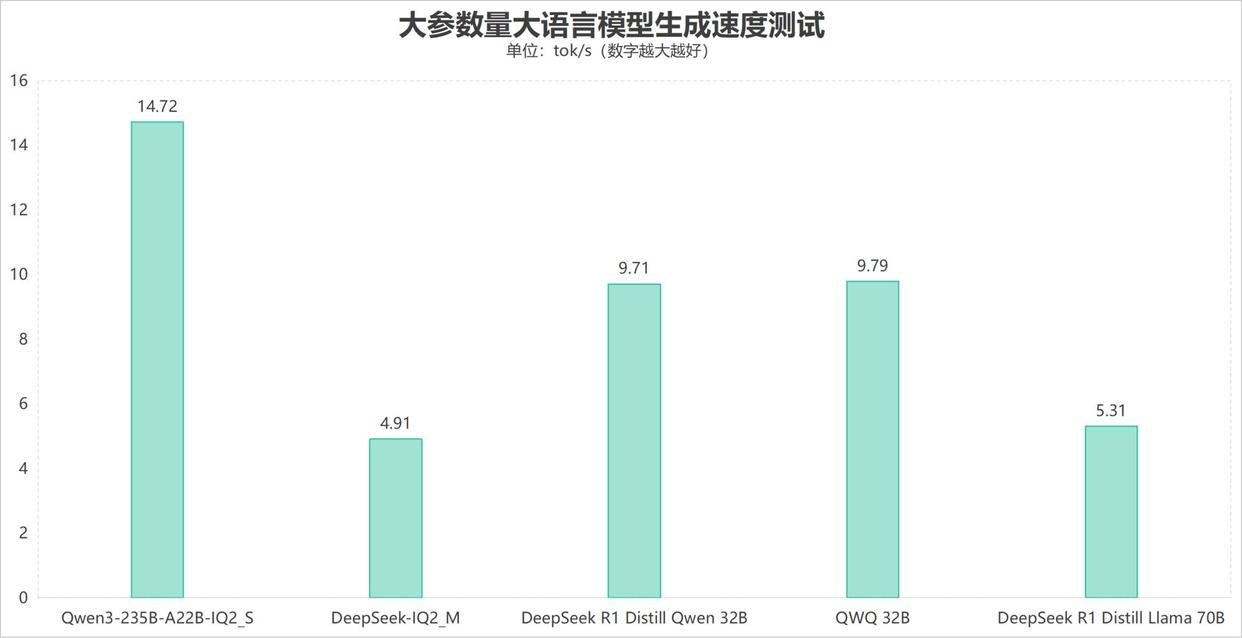
另外这里要说明的一点是,Qwen3-235B-A22B-IQ2_S这个模型虽然参数量达到了235B,但它并非是常见的稠密模型,而是MoE(Mixtureofexperts)混合专家模型。简单来说,MoE模型虽然总参数量很大,但以Qwen3-235B-A22B-IQ2_S模型为例,它虽然拥有235B总参数量,但运行时实际只会调用22B(模型中A22B标识就表示运行时只会调用22B参数量)的参数进行计算,因此对于硬件的压力要小很多。
也正是因为有着这种大参数、低算力特性,MoE模型或许会成为未来大模型发展的主流趋势。
反之,稠密模型每一次计算都会调用所有参数,这也就是为什么235B的Qwen3-235B-A22B-IQ2_S生成速度反而比DeepSeek R1 32B、QWQ 32B大模型要快的原因。
AI测试的最后一部分,我们使用了针对AMD锐龙平台打造的Amuse这款Stable Diffusion工具,它支持文生图、图生图、文生视频等应用,使用起来非常方便。
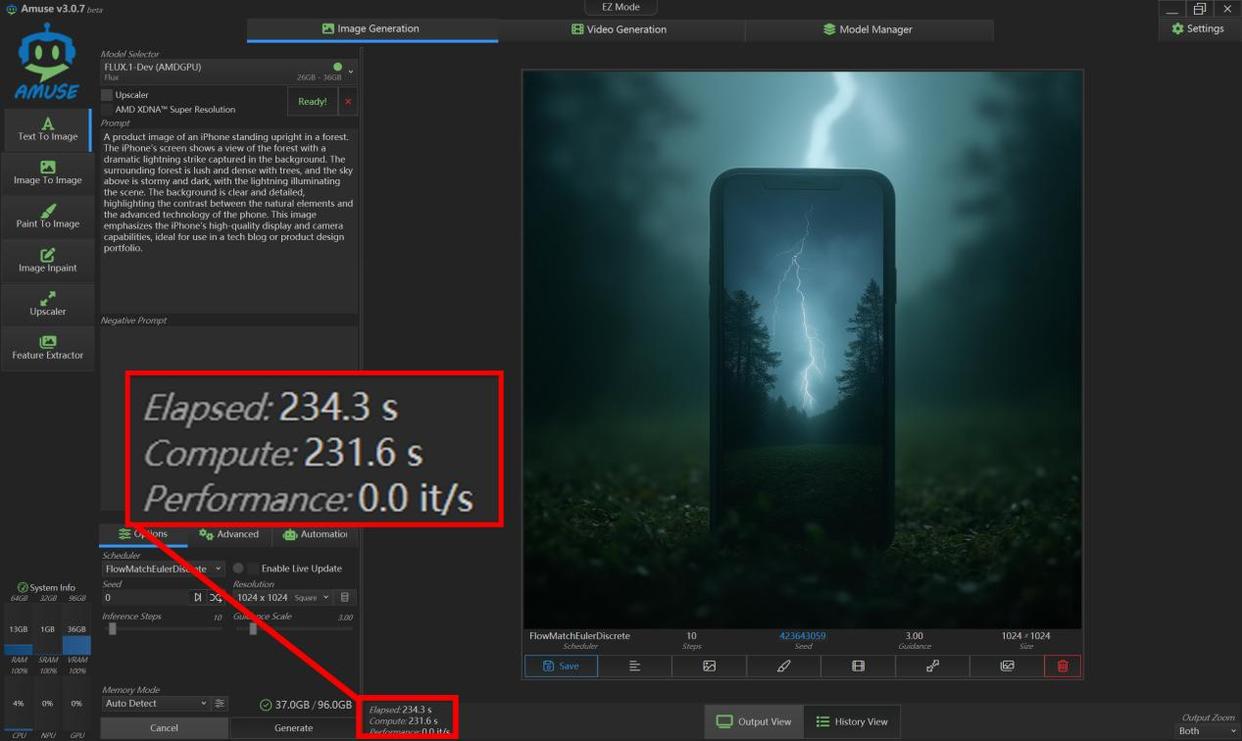
首先我们使用最近大半年非常火爆的FLUX.1-Dev模型进行了文生图测试,实测迭代10步,生成一张1024×1024超清图片用时234.3秒。这个表现虽然不如独显,但在集成显卡里,能顺利完成这一任务的此前没有,Radeon 8060S不仅顺利完成,而且效率也还不错,毕竟1024×1024规格的图片生成,在AI文生图应用中算是高负载任务了。
其次我们使用了Stable Diffusion XL Turbo模型,进行了2048x2048规格图片的生成。这款大模型整体精度要低一些,所以对硬件负载的压力不算太高。普通用户使用这类大模型进行文生图就足够了,没必要使用FLUX.1-Dev这种超高精度大模型。
可以看到,Stable Diffusion XL Turbo模型生成2048x2048规格图片耗时仅需12.8秒,每秒迭代次数也达到了2.6次。

总体来说,锐龙AI Max+ 395是非常不错的AI计算平台,配合大内存并通过AMD统一内存技术分配给显存之后,常规的AI应用基本没有太大压力,完全可以作为个人或者小型工作室、小型企业用户的AI终端设备。尤其相比动辄数万、数十万元的AI一体机来说,14999元的极摩客EVO-X2绝对是一个高性价比的解决方案。
同时,这类设备也非常适合AI初学者、初级AI开发者使用。首先,锐龙AI Max+ 395平台配合超大内存,完全可以在本地部署多样化的AI大模型,如70B、32B大语言模型,或者Flux、StableDiffusion等文生图、文生视频大模型。借助LMStudio、Comfy-UI等AI工具,轻松实现本地化的AI助手、个人知识库以及图片、视频创作平台的搭建。
其次,超大内存与显存带来了更加出色的AI应用体验,例如用户在实际应用中可以同时加载Stable Diffusion+Whisper+Llama这样的混合式AI模型方案,从而用AI解决AI应用的问题,如让AI直接生成提示词,再通过SD进行图片、视频创作。同时锐龙AI Max+395平台还支持ONNX、DirectML等多种框架,完美适配Windows平台的部署与运行。因此也非常适合多模态AI应用,如扩图、分割、语音识别、图像识别等,节约实验或验证成本,快速完成Demo或开源项目的开发。
其三,设备成本支出更低的同时,本地化部署带来的另一大好处就是使用成本几乎为零。用户无需额外支付Token费用,也不受网络质量影响。同时拥有更加可靠的用户隐私、数据安全,算法模型数据不容易外泄。
此外,锐龙AI Max+ 395的NPU也可以参与YOLO等适配模型的相关任务,分担负载,从而让多模态应用拥有最优的算力表现。
游戏性能评估
锐龙AI Max+ 395集成的Radeon 8060S本身拥有相当不错的图形性能,因此对于游戏玩家来说也是不错的选择。所以性能测试的最后一部分,我们进行了四款热门游戏的测试。
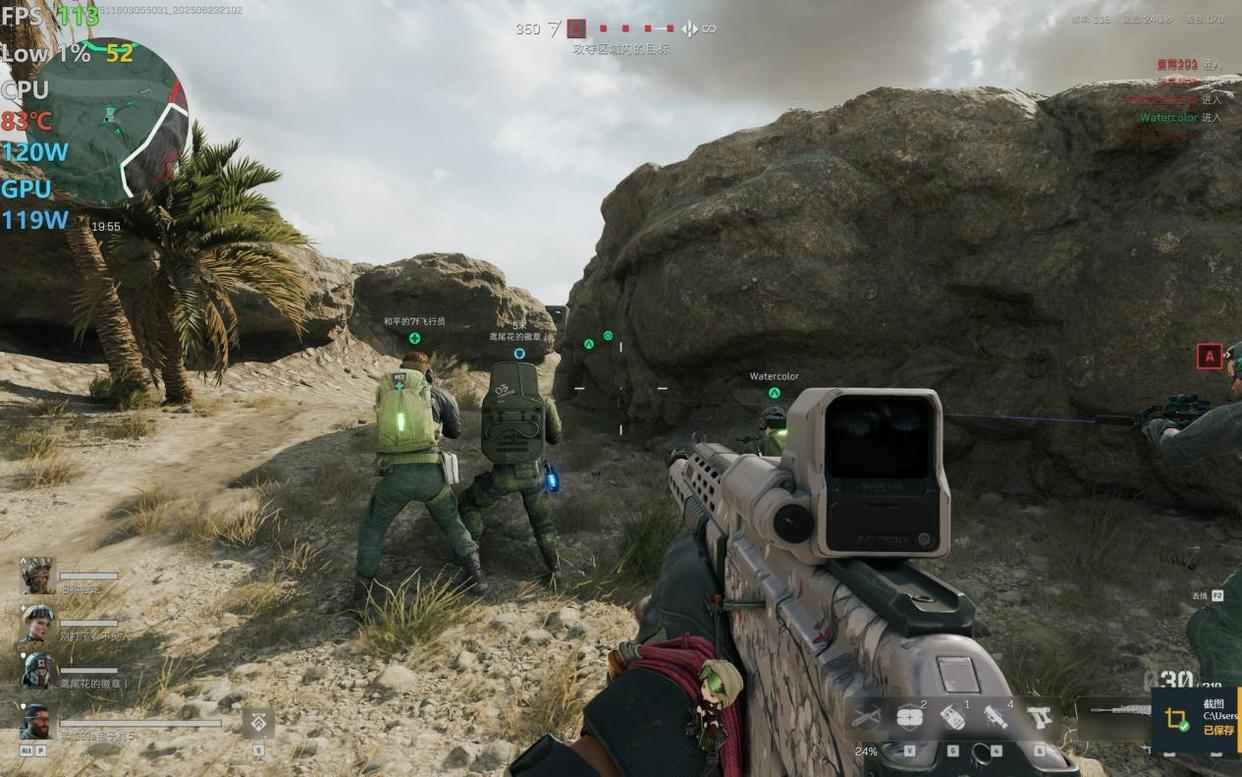
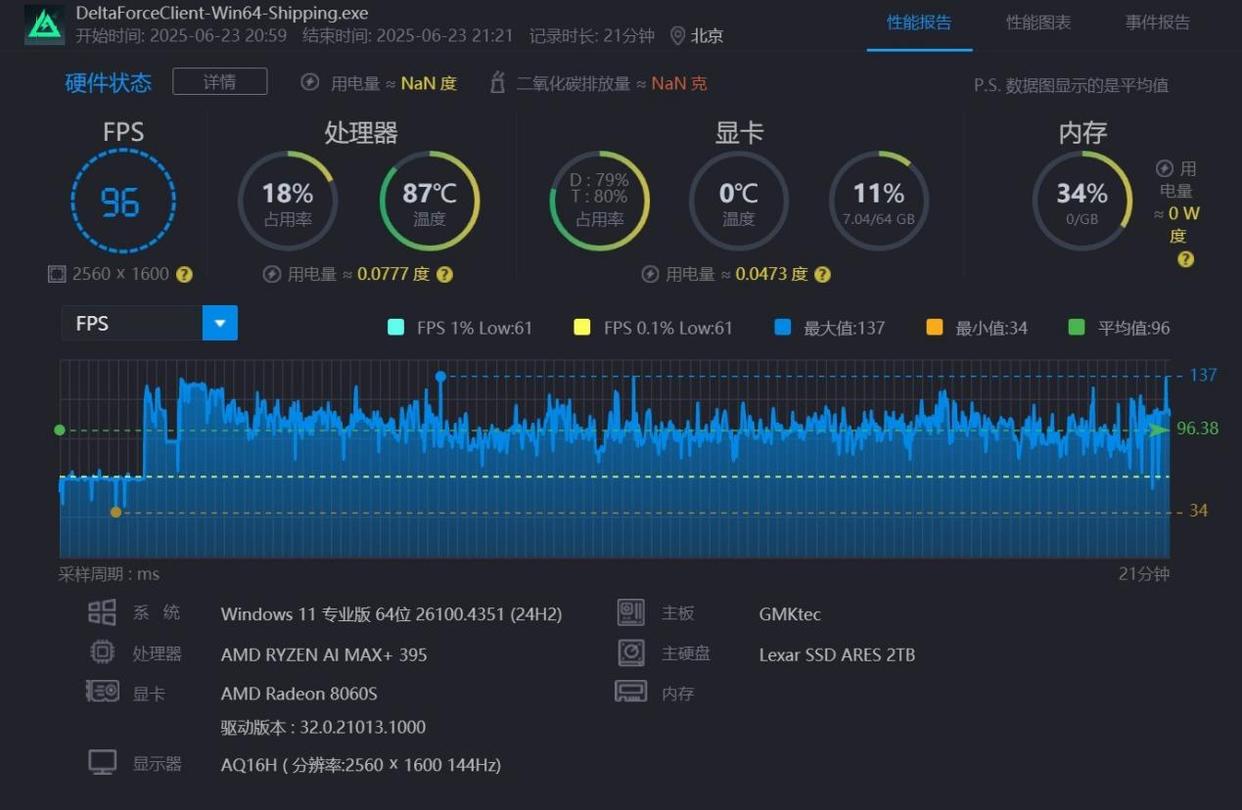
- 《三角洲行动》,极高画质(次高画质),2560x1600分辨率,平均帧率可以达到96fps,流畅运行无压力。
- 《荒野大镖客2》,中等画质,2560x1600分辨率,开启FSR,平均帧率可以达到89fps,运行非常流畅。
- 《赛博朋克2077》,超级画质,未开启光追,2560x1600分辨率,平均帧率可以达到59.23fps,接近60fps的表现已经远超当前其它集成显卡了。
- 《黑神话:悟空》,超高画质(非影视级画质),2560x1600分辨率,平均帧率达到了62fps,可以流畅游玩。
可见极摩客EVO-X2不仅拥有出色的AI性能,同时还有着不错的游戏性能,再加上出色的生产力性能,这款产品可以说是相当能打的一款综合性迷你主机了。而且确实不负“桌面AI超算中心”之名!


相关文章

8核办公神器告别传统主机累赘! 机械师MINI GTR迷你主机评测
机械师Mini GTR系列迷你主机,是一款集高性能、便携性、低功耗与丰富功能于一身的优质产品,它凭借卓越的设计理念和硬件配置,成为了办公党提升工作效率、家庭用户享受数字2025-06-20
能安装6块硬盘! 零刻ME mini迷你主机NAS二合一测评
能安装6块硬盘,具备双2.5G网口,内置电源设计,这就是来自零刻推出的零刻ME mini迷你电脑主机,这款迷你主机怎么样?详细请看下文介绍2025-06-18
搭载AI Max+395的超能AI工作站! 磐镭YO1迷你主机全面测评
在2025年的科技浪潮中,锐龙AI Max+ 395处理器凭借其颠覆性的性能表现,成为迷你主机领域的顶级芯片,今天我们就来看看磐镭YO1迷你主机评测2025-06-16
武装锐龙7 7735U 又稳又安静的办公神器! 零刻EQR7小主机测评
零刻EQR7准系统售价1495元(7535U版)和1695元(7735U版),那么,它与前辈相比有啥变化,是否值得咱们期待?详细请看下文测评2025-06-11
入门级迷你电脑也弄铝合金机身设计? MAXHUB MI20迷你主机评测
MAXHUB MI20迷你主机似乎铝合金外壳,N100处理器,丰富接口,下面就让我带各位具体来看下MAXHUB MI20的整机设计如何吧2025-05-12
3000元级性能强劲的办公利器! 华硕破晓6X商务台式主机测评
华硕最近新推出一款全新的破晓6X商务台式机,这款产品在保障安全、稳定和专业的基础上,还为市场带来了新的体验2025-04-08
本地化部署DeepSeek有手就行! 零刻SER9 Pro小主机游戏与AI测评
自开年以来以DeepSeek为代表的AI工具火出了天际,工作中的许多琐碎事儿都可以交给AI来完成,今天,我为大家带来的是搭载了AMD AI9 365的迷你主机——零刻SER9 Pro的游戏与A2025-03-28
搭载i5-1250P的铭凡UN1250值得买吗? 铭凡 UN1250迷你主机开售
铭凡现已在京东上架一款型号为 UN1250 的迷你主机,该机搭载 i5-1250P 处理器,这款小主机有啥优缺点?值不值得购买?详细请看下文介绍2024-12-30
新款MacMini小主机怎么扩容? 一文学会扩容存储空间的技巧
苹果推出了新款Mac mini小主机,其采用最新的M4和M4Pro芯片,尺寸仅为手掌大小,尽管厚度略有增加,但通过紧凑的设计让整体占用空间更小了,该怎么扩容呢?下面我们就来看2024-12-24
升级R7 8745H准! 铭凡UM870 Slim 迷你主机全面测评
铭凡 UM870 Slim 迷你主机现已在京东开售,这款迷你主机采用 R7-8745H 处理器,可选准系统版,下面我们就来看看这款全能小主机详细测评2024-12-20










最新评论