
Node.js 实现简单爬虫的示例代码
更新时间:2025年02月24日 08:31:06 作者:忆宸_1
本文主要介绍了Node.js 实现简单爬虫,爬取美食网站的菜品标题和图片链接,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
介绍
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
本文将使用 Nodejs 编写一个简单的爬虫脚本,爬取一个美食网站,获取菜品的标题和图片链接,并以表格的形式输出。
准备工作
1、初始化项目
首先,确保已安装 Node,然后创建一个新的文件目录,运行以下命令初始化 Node.js 项目
npm init -y
2、安装依赖
使用 axios 库来进行 HTTP 请求
使用 cheerio 库来解析 HTML 内容
使用 node-xlsx 库来将数据写入 Excel 文件
npm install axios cheerio node-xlsx --save
代码实现
1、创建爬虫脚本
在项目根目录下创建一个 crawler.js 文件,并写入以下代码
import axios from "axios";
import cheerio from "cheerio";
// 目标网页的URL,这里使用 下厨房 这个美食网站作为测试
const targetUrl = "https://www.xiachufang.com/category/40076/";
// 请求目标网页,获取HTML内容
const getHtml = async () => {
const response = await axios.get(targetUrl);
if (response.status !== 200) {
throw new Error("请求失败");
}
return response.data;
};
// 解析HTML内容,获取菜品的标题和图片链接
const getData = async (html) => {
const $ = cheerio.load(html);
const list = [];
$(".normal-recipe-list li").each((i, elem) => {
const imgUrl = $(elem).find("img").attr("src");
const title = $(elem).find("p.name a").text();
list.push({
title: title.replace(/[\n\s]+/g, ""),
imgUrl,
});
});
return list;
};
2、以 Excel 表格形式保存数据
import xlsx from "node-xlsx";
import fs from "fs";
// 根据 表头数据 和 列表数据 转换成二维数组
const transData = (columns, tableList) => {
const data = columns.reduce(
(acc, cur) => {
acc.titles.push(cur.header);
acc.keys.push(cur.key);
return acc;
},
{ titles: [], keys: [] }
);
const tableBody = tableList.map((item) => {
return data.keys.map((key) => item[key]);
});
return [data.titles, ...tableBody];
};
const writeExcel = (list) => {
// 表头
const columns = [
{ header: "菜名", key: "title" },
{ header: "图片链接", key: "imgUrl" },
];
// 构建表格数据
const tableData = transData(columns, list);
const workbook = xlsx.build([
{
name: "菜谱",
data: tableData,
},
]);
// 写入文件
fs.writeFileSync("./菜谱.xlsx", workbook, "binary");
};
3、执行
(async () => {
const html = await getHtml();
const list = await getData(html);
await writeExcel(list);
console.log("执行完毕");
})();
运行爬虫
在终端中运行以下命令来执行爬虫代码
node crawler.js
效果图
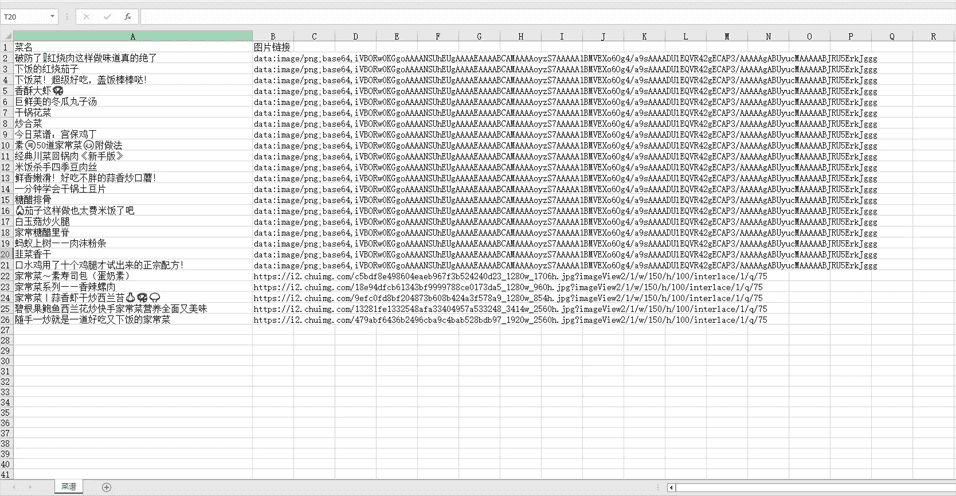
总结
通过学习这个简单的示例,您可以进一步探索更复杂的爬虫应用,处理更多类型的网页和数据,并加入更多功能来实现您自己的爬虫项目。
到此这篇关于Node.js 实现简单爬虫的示例代码的文章就介绍到这了,更多相关Node.js 爬虫内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 Node版本管理器--nvm,可以运行在多种操作系统上。nvm for windows 是使用go语言编写的软件。 我电脑使用的是Windows操作系统,所以我要记录下在此操作系统上nvm的安装和使用2021-06-06
Node版本管理器--nvm,可以运行在多种操作系统上。nvm for windows 是使用go语言编写的软件。 我电脑使用的是Windows操作系统,所以我要记录下在此操作系统上nvm的安装和使用2021-06-06 这篇文章主要为大家详细介绍了Node.js制作简单聊天室的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-01-01
这篇文章主要为大家详细介绍了Node.js制作简单聊天室的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-01-01 本篇文章主要介绍了Node.js 沙箱环境 ,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-05-05
本篇文章主要介绍了Node.js 沙箱环境 ,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-05-05
如何在 Node.js 中使用 axios 配置代理并实现图片并发下载
这篇文章主要介绍了如何在Node.js中使用axios配置代理并实现图片并发下载,本文通过实例代码给大家介绍的非常详细,感兴趣的朋友跟随小编一起看看吧2024-07-07 自从MySQL被Oracle收购以后,PostgreSQL逐渐成为开源关系型数据库的首选。这篇文章就给大家介绍了关于Node.js如何连接postgreSQL数据库,并进行数据操作的方法,有需要的朋友们可以参考借鉴,下面来一起看看吧。2016-12-12
自从MySQL被Oracle收购以后,PostgreSQL逐渐成为开源关系型数据库的首选。这篇文章就给大家介绍了关于Node.js如何连接postgreSQL数据库,并进行数据操作的方法,有需要的朋友们可以参考借鉴,下面来一起看看吧。2016-12-12
Windows系统下Node.js安装以及环境配置的完美教程
相信对于很多关注javascript发展的同学来说,nodejs已经不是一个陌生的词眼,下面这篇文章主要给大家介绍了关于Windows系统下Node.js安装以及环境配置的完美教程,需要的朋友可以参考下2022-06-06 这篇文章主要为大家详细介绍了Node.js模块机制,一篇关于Node.js模块机制的学习笔记,感兴趣的小伙伴们可以参考一下2016-10-10
这篇文章主要为大家详细介绍了Node.js模块机制,一篇关于Node.js模块机制的学习笔记,感兴趣的小伙伴们可以参考一下2016-10-10
解决Node.js使用MySQL出现connect ECONNREFUSED 127.0.0.1:3306的问题
这篇文章主要介绍了解决Node.js使用MySQL出现connect ECONNREFUSED 127.0.0.1:3306报错的相关资料,文中将问题描述的很清楚,解决的方法也介绍的很完整,需要的朋友可以参考借鉴,下面来一起看看吧。2017-03-03
NodeJS学习笔记之(Url,QueryString,Path)模块
今天我们来看一下在nodejs中路径的相关操作方法。在我们开发过程中路径主要有:URL路径,在浏览器中进行使用,当然这个也包含查询字符串QueryString的相关操作;而另一种是磁盘路径,主要用于文件等等进行操作,我们称为Path,所以我将它们放在一起进行总结学习。2015-01-01 这篇文章主要介绍了深入理解NodeJS 多进程和集群,详细的介绍了什么是进程和进程的实现等,非常具有实用价值,需要的朋友可以参考下2018-10-10
这篇文章主要介绍了深入理解NodeJS 多进程和集群,详细的介绍了什么是进程和进程的实现等,非常具有实用价值,需要的朋友可以参考下2018-10-10










最新评论