
Acrobat2018怎么使用OCR识别扫描版PDF中的文字?
Acrobat 2017/2018中不像之前的版本在编辑中能找到写有OCR功能的选项,那是因为ocr识别改名为“编辑文本和图像”了,下面我们就来看看详细的教程。

1、打开要识别的PDF,如果该PDF没有加密,那么点击“编辑-编辑文本和图像”或者在任意页面鼠标右击,选择“编辑图像”,就可以进行OCR识别了。
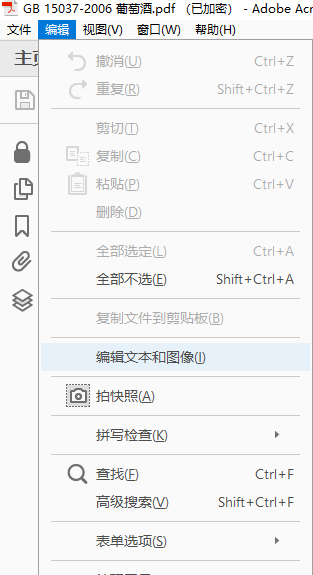

2、进行第一步之后,默认执行的单页的识别,但是如果你要识别整个PDF文件,怎么办?
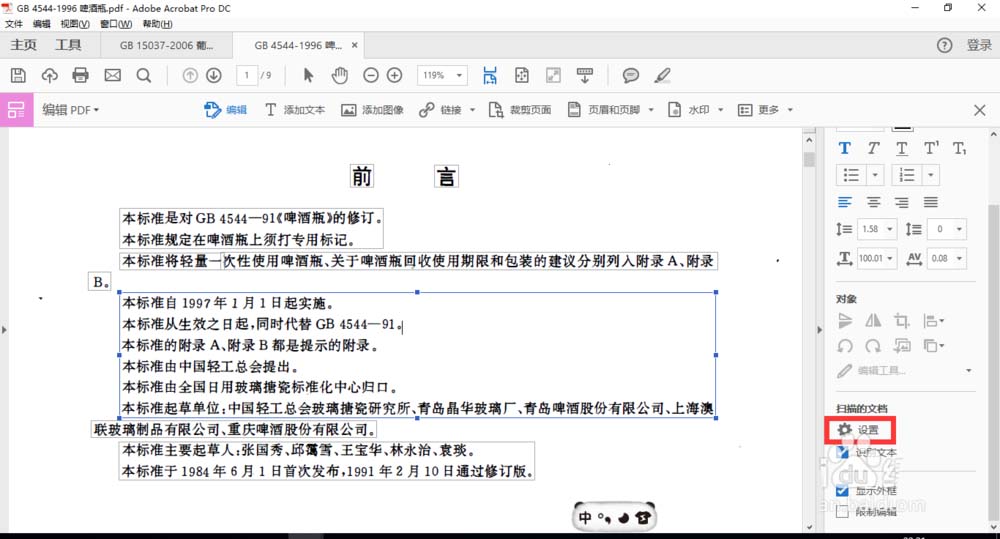
3、点击图中右下角扫描文档下的“设置”,在弹出的窗口中勾选“所有页面均可编辑”,点击确定,再点击编辑图像时,就可以全篇识别了。

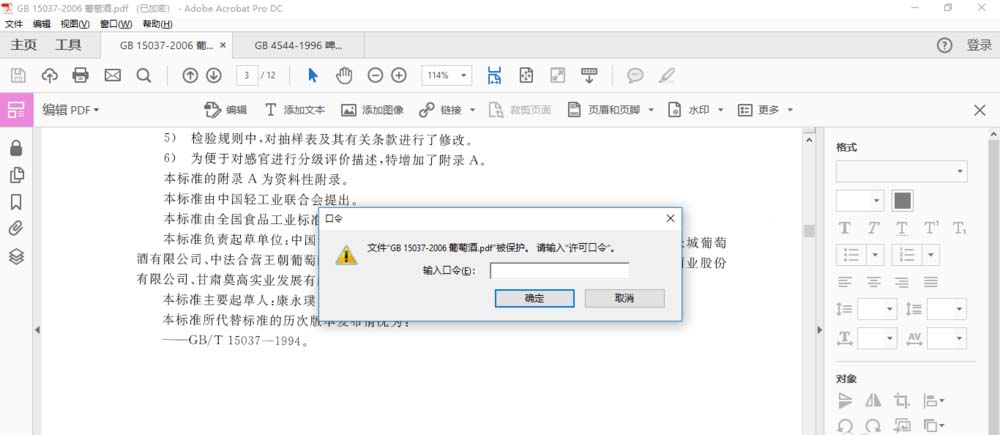
4、但是面对加密的文档,会提示需要“输入口令”,这个时候需要使用软件PDFPasswordRmover,移除PDF的密码,就可以按照上面的方法愉快的OCR识别了。有时也会出现,点了“编辑图像”,但是未能进行OCR识别,只是把当页识别成一整张图片,我也用PDFPasswordRmover处理了一下,然后再进行OCR识别,就没问题了。
以上就是Acrobat2018找不到OCR识别的原因,直接使用编辑文本和图像也是一样的功能,希望大家喜欢,请继续关注脚本之家。
相关推荐:
相关文章

pitstop2018怎么破解 Enfocus PitStop Pro 2018安装破解图文详细教程
pitstop2018怎么安装和破解?是很多新用户都比较关心的问题,今天小编就给大家带来非常详细的Enfocus PitStop Pro 2018安装破解图文教程,并附有pitstop2018破解版下载,需2018-07-13
Enfocus PitStop Pro 2017 v17.0中文安装及破解详细教程(附破解补丁下
PitStop Pro 2017中文版是一款Adobe Acrobat PDF增强插件,用于检查、编辑和批量修改PDF文件,本文下面整理了PitStop Pro 2017中文版的安装及破解方法,附有破解补丁下载2017-11-11
Adobe Acrobat Pro DC 2018破解版安装图文详细教程(附下载)
最近Adobe Acrobat Pro DC 2018版已经正式发布了,很多想要更新使用Acrobat Pro DC 2018的朋友问小编:Acrobat Pro DC 2018在哪下载?以及怎么安装破解?对此,本文就为大2017-11-15
acrobat pro dc怎么用?adobe acrobat pro dc 2017安装+使用教程
adobe acrobat pro dc 2017是Adobe公司开发的一款处理pdf文档的完备桌面解决方案,但很多网友朋友问小编acrobat pro dc怎么安装?acrobat pro dc怎么使用?本文带来adobe a2017-07-13Acrobat DC Pro怎么注册 Acrobat DC Pro注册详细图文教程
acrobat pro dc是目前Adobe公司最新发布的全新一代PDF制作软件,很多朋友不知道Acrobat DC Pro怎么注册,今天小编就为大家带来Acrobat DC Pro注册教程,一起看看吧2016-06-07Adobe Acrobat DC怎么使用?Adobe Acrobat DC下载安装图文教程
adobe acrobat DC是Adobe最新推出的一款专业的PDF制作工具,这款工具不仅可以帮助用户轻松制作pdf文件,还具有编辑、导出、注释等功能2016-05-27
新媒体管家Plus(Chrome浏览器插件)安装问题及使用教程
新媒体管家plus插件是一款简洁、易用的新媒体管理工具,基于Chromium内核的浏览器插件,持采集图文,导入动图,文本缩进,文章动图自动播放,一键生成永久链接等,下文整理2017-07-21- 大家都知道百度云盘(百度网盘)是非常方便好用的在线网盘,但要下载超过1G的文件则会提示“你下载的文件过大,怎么能不装百度云管家直接下载超过1GB的大文件?下面就一起2016-03-30

Enfocus PitStop Server 2019 64位中文版安装及激活详细教程(附补丁下
PitStop 2019是一款功能强大的adobe acrobat插件,主要功能就是用于检查、编辑和修改PDF文件,可以对pdf文档进行印前检查和编辑,这里提供最新PitStop Server2019激活版的2019-08-12






最新评论