
在PyTorch中实现可解释的神经网络模型的方法详解
目的
深度学习系统缺乏可解释性对建立人类信任构成了重大挑战。这些模型的复杂性使人类几乎不可能理解其决策背后的根本原因。
深度学习系统缺乏可解释性阻碍了人类的信任。
为了解决这个问题,研究人员一直在积极研究新的解决方案,从而产生了重大创新,例如基于概念的模型。这些模型不仅提高了模型的透明度,而且通过在训练过程中结合高级人类可解释的概念(如“颜色”或“形状”),培养了对系统决策的新信任感。因此,这些模型可以根据学习到的概念为其预测提供简单直观的解释,从而使人们能够检查其决策背后的原因。这还不是全部!它们甚至允许人类与学习到的概念进行交互,让我们能够控制最终的决定。
基于概念的模型允许人类检查深度学习预测背后的推理,并让我们重新控制最终决策。
在本文中,我们将深入研究这些技术,并为您提供使用简单的 PyTorch 接口实现最先进的基于概念的模型的工具。通过实践经验,您将学习如何利用这些强大的模型来增强可解释性并最终校准人类对您的深度学习系统的信任。
概念瓶颈模型
在这个介绍中,我们将深入探讨概念瓶颈模型。这模型在 2020 年国际机器学习会议上发表的一篇论文中介绍,旨在首先学习和预测一组概念,例如“颜色”或“形状”,然后利用这些概念来解决下游分类任务:
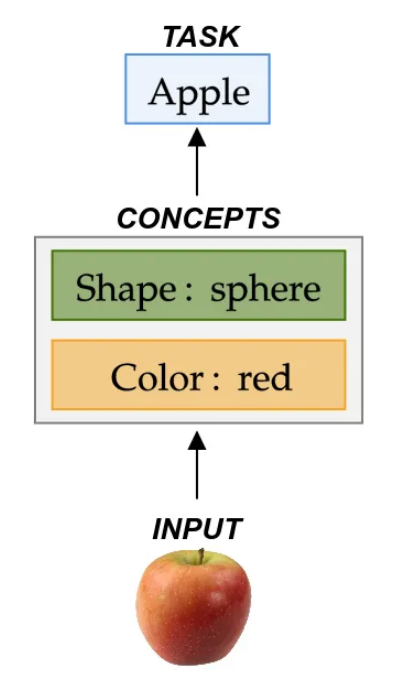
通过遵循这种方法,我们可以将预测追溯到提供解释的概念,例如“输入对象是一个{apple},因为它是{spherical}和{red}。”
概念瓶颈模型首先学习一组概念,例如“颜色”或“形状”,然后利用这些概念来解决下游分类任务。
实现
为了说明概念瓶颈模型,我们将重新审视著名的 XOR 问题,但有所不同。我们的输入将包含两个连续的特征。为了捕捉这些特征的本质,我们将使用概念编码器将它们映射为两个有意义的概念,表示为“A”和“B”。我们任务的目标是预测“A”和“B”的异或 (XOR)。通过这个例子,您将更好地理解概念瓶颈如何在实践中应用,并见证它们在解决具体问题方面的有效性。
我们可以从导入必要的库并加载这个简单的数据集开始:
import torch import torch_explain as te from torch_explain import datasets from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split x, c, y = datasets.xor(500) x_train, x_test, c_train, c_test, y_train, y_test = train_test_split(x, c, y, test_size=0.33, random_state=42)
接下来,我们实例化一个概念编码器以将输入特征映射到概念空间,并实例化一个任务预测器以将概念映射到任务预测:
concept_encoder = torch.nn.Sequential(
torch.nn.Linear(x.shape[1], 10),
torch.nn.LeakyReLU(),
torch.nn.Linear(10, 8),
torch.nn.LeakyReLU(),
torch.nn.Linear(8, c.shape[1]),
torch.nn.Sigmoid(),
)
task_predictor = torch.nn.Sequential(
torch.nn.Linear(c.shape[1], 8),
torch.nn.LeakyReLU(),
torch.nn.Linear(8, 1),
)
model = torch.nn.Sequential(concept_encoder, task_predictor)然后我们通过优化概念和任务的交叉熵损失来训练网络:
optimizer = torch.optim.AdamW(model.parameters(), lr=0.01)
loss_form_c = torch.nn.BCELoss()
loss_form_y = torch.nn.BCEWithLogitsLoss()
model.train()
for epoch in range(2001):
optimizer.zero_grad()
# generate concept and task predictions
c_pred = concept_encoder(x_train)
y_pred = task_predictor(c_pred)
# update loss
concept_loss = loss_form_c(c_pred, c_train)
task_loss = loss_form_y(y_pred, y_train)
loss = concept_loss + 0.2*task_loss
loss.backward()
optimizer.step()训练模型后,我们评估其在测试集上的性能:
c_pred = concept_encoder(x_test) y_pred = task_predictor(c_pred) concept_accuracy = accuracy_score(c_test, c_pred > 0.5) task_accuracy = accuracy_score(y_test, y_pred > 0)
现在,在几个 epoch 之后,我们可以观察到概念和任务在测试集上的准确性都非常好(~98% 的准确性)!
由于这种架构,我们可以通过根据输入概念查看任务预测器的响应来为模型预测提供解释,如下所示:
c_different = torch.FloatTensor([0, 1])
print(f"f({c_different}) = {int(task_predictor(c_different).item() > 0)}")
c_equal = torch.FloatTensor([1, 1])
print(f"f({c_different}) = {int(task_predictor(c_different).item() > 0)}")这会产生例如 f([0,1])=1 和 f([1,1])=0 ,如预期的那样。这使我们能够更多地了解模型的行为,并检查它对于任何相关概念集的行为是否符合预期,例如,对于互斥的输入概念 [0,1] 或 [1,0],它返回的预测y=1。
概念瓶颈模型通过将预测追溯到概念来提供直观的解释。
淹没在准确性与可解释性的权衡中
概念瓶颈模型的主要优势之一是它们能够通过揭示概念预测模式来为预测提供解释,从而使人们能够评估模型的推理是否符合他们的期望。
然而,标准概念瓶颈模型的主要问题是它们难以解决复杂问题!更一般地说,他们遇到了可解释人工智能中众所周知的一个众所周知的问题,称为准确性-可解释性权衡。实际上,我们希望模型不仅能实现高任务性能,还能提供高质量的解释。不幸的是,在许多情况下,当我们追求更高的准确性时,模型提供的解释往往会在质量和忠实度上下降,反之亦然。
在视觉上,这种权衡可以表示如下:
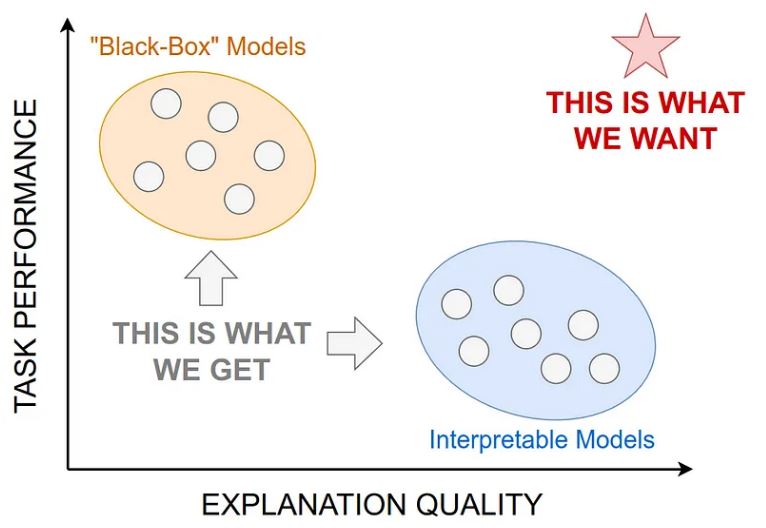
可解释模型擅长提供高质量的解释,但难以解决具有挑战性的任务,而黑盒模型以提供脆弱和糟糕的解释为代价来实现高任务准确性。
为了在具体设置中说明这种权衡,让我们考虑一个概念瓶颈模型,该模型应用于要求稍高的基准,即“三角学”数据集:
x, c, y = datasets.trigonometry(500) x_train, x_test, c_train, c_test, y_train, y_test = train_test_split(x, c, y, test_size=0.33, random_state=42)
在该数据集上训练相同的网络架构后,我们观察到任务准确性显着降低,仅达到 80% 左右。
概念瓶颈模型未能在任务准确性和解释质量之间取得平衡。
这就引出了一个问题:我们是永远被迫在准确性和解释质量之间做出选择,还是有办法取得更好的平衡?
以上就是在PyTorch中实现可解释的神经网络模型的方法详解的详细内容,更多关于PyTorch 神经网络模型的资料请关注脚本之家其它相关文章!
相关文章

Keras中 ImageDataGenerator函数的参数用法
这篇文章主要介绍了Keras中 ImageDataGenerator函数的参数用法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-07-07 命令行程序是平时写一些小工具时最常用的方式,随着命令行程序功能的丰富,也就是参数多了以后,解析和管理参数之间的关系会变得越来越繁重,而本次介绍的 Fire 库正好可以解决这个问题,下面我们就来看看具体实现方法吧2023-09-09
命令行程序是平时写一些小工具时最常用的方式,随着命令行程序功能的丰富,也就是参数多了以后,解析和管理参数之间的关系会变得越来越繁重,而本次介绍的 Fire 库正好可以解决这个问题,下面我们就来看看具体实现方法吧2023-09-09 在Python编程中,for循环是最常用的控制结构之一,而列表(list)是最基础的数据结构之一,但在使用for循环遍历列表并对列表进行增删改操作时,往往会遇到意想不到的错误,下面我们就来深入研究一下吧2025-06-06
在Python编程中,for循环是最常用的控制结构之一,而列表(list)是最基础的数据结构之一,但在使用for循环遍历列表并对列表进行增删改操作时,往往会遇到意想不到的错误,下面我们就来深入研究一下吧2025-06-06
Python 实现判断图片格式并转换,将转换的图像存到生成的文件夹中
今天小编就为大家分享一篇Python判断图片格式并转换,将转换的图像存到生成的文件夹中,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01 本篇文章主要介绍基于python的七种经典排序算法(推荐),具有一定的参考价值,这里整理了详细的代码,有需要的小伙伴可以参考下。2016-12-12
本篇文章主要介绍基于python的七种经典排序算法(推荐),具有一定的参考价值,这里整理了详细的代码,有需要的小伙伴可以参考下。2016-12-12 本文将详细介绍Python中执行和调用JavaScript的多种方法,包括内置的execjs库、外部库如PyExecJS、使用浏览器引擎和与Node.js的交互,感兴趣的可以了解一下2023-11-11
本文将详细介绍Python中执行和调用JavaScript的多种方法,包括内置的execjs库、外部库如PyExecJS、使用浏览器引擎和与Node.js的交互,感兴趣的可以了解一下2023-11-11 这篇文章主要介绍了Django框架使用内置方法实现登录功能,结合实例形式详细分析了Django框架内置方法实现登录功能的相关操作技巧与使用注意事项,需要的朋友可以参考下2019-06-06
这篇文章主要介绍了Django框架使用内置方法实现登录功能,结合实例形式详细分析了Django框架内置方法实现登录功能的相关操作技巧与使用注意事项,需要的朋友可以参考下2019-06-06 将Python代码打包成可执行文件是一种使你的应用程序更易于分享和分发的方法,本文一步一步地教你如何用 Pyinstaller 模块将Python程序打包成exe文件,这篇教程绝对是全网最全面、最详细的教程,包含四种打包的方法,需要的朋友可以参考下2025-07-07
将Python代码打包成可执行文件是一种使你的应用程序更易于分享和分发的方法,本文一步一步地教你如何用 Pyinstaller 模块将Python程序打包成exe文件,这篇教程绝对是全网最全面、最详细的教程,包含四种打包的方法,需要的朋友可以参考下2025-07-07 这篇文章主要给大家介绍了关于Python运算符使用的相关资料,文中总结了Python中的算术运算符、赋值运算符、比较运算符、逻辑运算符、位运算符和成员运算符的用法和特性,需要的朋友可以参考下2024-11-11
这篇文章主要给大家介绍了关于Python运算符使用的相关资料,文中总结了Python中的算术运算符、赋值运算符、比较运算符、逻辑运算符、位运算符和成员运算符的用法和特性,需要的朋友可以参考下2024-11-11 今天小编就为大家分享一篇pytorch masked_fill报错的解决,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
今天小编就为大家分享一篇pytorch masked_fill报错的解决,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02










最新评论