
Python批量实现Word/EXCEL/PPT转PDF
一、绪论背景
在日常办公和文档处理中,有时我们需要将多个Word文档、Excel表格或PPT演示文稿转换为PDF文件。将文档转换为PDF格式的好处是它可以保留文档的布局和格式,并且可以在不同平台上进行方便的查看和共享。
本篇博文将介绍如何使用Python编程语言批量实现将多个Word、Excel和PPT文件转换为PDF文件。我们将通过使用Python第三方库来读取、编辑和保存这些文档,并使用合适的转换工具将它们转换为PDF格式。
具体实现方面,我们将首先安装所需的Python库和相关软件,主要使用三个库函数:os, win32com.client, gc。
1)os : os 是Python内置的一个与操作系统交互的库。它提供了许多用于处理文件和目录的函数,例如创建、删除、重命名文件或目录,获取文件属性,遍历目录等。通过使用 os 库,我们可以在Python程序中执行各种与操作系统相关的任务。
2)win32com.client : win32com.client 是一个用于与Windows平台上的COM组件进行交互的Python库。COM(Component Object Model)是一种面向对象的组件技术,允许不同的应用程序之间进行通信和交互。 win32com.client 库提供了一种方便的方式来调用和操作COM组件,如Microsoft Office应用程序(Word、Excel、PowerPoint等)。通过这个库,我们可以自动化执行一些Office任务,如读写文档、操作Excel表格、创建PPT演示文稿等。
3)gc : gc 是Python内置的垃圾回收模块。垃圾回收是指在程序执行过程中,自动检测和回收不再使用的内存空间,以提高内存利用率和程序性能。 gc 模块为我们提供了一些功能,如手动触发垃圾回收、获取和设置垃圾回收的阈值等。尽管Python有自动的垃圾回收机制,但在某些情况下,我们可能需要手动控制垃圾回收的行为。
然后,我们将编写Python代码来遍历指定文件夹中的所有文档,并对每个文档进行逐个转换。
最后,我们将保存转换后的PDF文件到指定的目录中。
通过阅读本篇博文,你将学习到如何使用Python编程语言批量实现将多个Word、Excel和PPT文件转换为PDF文件的方法。这将为你提供一种自动化的方式来处理文档转换任务,节省时间和精力,并提高工作效率。
无论你是一位办公人员、学生还是有大量文档需要处理的个人用户,本篇教程都将帮助你掌握如何使用Python批量实现Word、Excel和PPT转换为PDF文件。让我们一起开始这个方便实用的文档处理之旅吧!
二、代码实践
大家运行本代码,只需要更改为自己的路径即可。如代码中我的地址:D:\Pycharmproject2023\code_test_project\shan_test\data,改为你本地地址即可。
import os, win32com.client, gc
# Word
def word2Pdf(filePath, words):
# 如果没有文件则提示后直接退出
if (len(words) < 1):
print("\n【无 Word 文件】\n")
return
# 开始转换
print("\n【开始 Word -> PDF 转换】")
try:
print("打开 Word 进程...")
word = win32com.client.Dispatch("Word.Application")
word.Visible = 0
word.DisplayAlerts = False
doc = None
for i in range(len(words)):
print(i)
fileName = words[i] # 文件名称
fromFile = os.path.join(filePath, fileName) # 文件地址
toFileName = changeSufix2Pdf(fileName) # 生成的文件名称
toFile = toFileJoin(filePath, toFileName) # 生成的文件地址
print("转换:" + fileName + "文件中...")
# 某文件出错不影响其他文件打印
try:
doc = word.Documents.Open(fromFile)
doc.SaveAs(toFile, 17) # 生成的所有 PDF 都会在 PDF 文件夹中
print("转换到:" + toFileName + "完成")
except Exception as e:
print(e)
# 关闭 Word 进程
print("所有 Word 文件已打印完毕")
print("结束 Word 进程...\n")
doc.Close()
doc = None
word.Quit()
word = None
except Exception as e:
print(e)
finally:
gc.collect()
# Excel
def excel2Pdf(filePath, excels):
# 如果没有文件则提示后直接退出
if (len(excels) < 1):
print("\n【无 Excel 文件】\n")
return
# 开始转换
print("\n【开始 Excel -> PDF 转换】")
try:
print("打开 Excel 进程中...")
excel = win32com.client.Dispatch("Excel.Application")
excel.Visible = 0
excel.DisplayAlerts = False
wb = None
ws = None
for i in range(len(excels)):
print(i)
fileName = excels[i] # 文件名称
fromFile = os.path.join(filePath, fileName) # 文件地址
print("转换:" + fileName + "文件中...")
# 某文件出错不影响其他文件打印
try:
wb = excel.Workbooks.Open(fromFile)
for j in range(wb.Worksheets.Count): # 工作表数量,一个工作簿可能有多张工作表
toFileName = addWorksheetsOrder(fileName, j + 1) # 生成的文件名称
toFile = toFileJoin(filePath, toFileName) # 生成的文件地址
ws = wb.Worksheets(j + 1) # 若为[0]则打包后会提示越界
ws.ExportAsFixedFormat(0, toFile) # 每一张都需要打印
print("转换至:" + toFileName + "文件完成")
except Exception as e:
print(e)
# 关闭 Excel 进程
print("所有 Excel 文件已打印完毕")
print("结束 Excel 进程中...\n")
ws = None
wb.Close()
wb = None
excel.Quit()
excel = None
except Exception as e:
print(e)
finally:
gc.collect()
# PPT
def ppt2Pdf(filePath, ppts):
# 如果没有文件则提示后直接退出
if (len(ppts) < 1):
print("\n【无 PPT 文件】\n")
return
# 开始转换
print("\n【开始 PPT -> PDF 转换】")
try:
print("打开 PowerPoint 进程中...")
powerpoint = win32com.client.Dispatch("PowerPoint.Application")
ppt = None
# 某文件出错不影响其他文件打印
for i in range(len(ppts)):
print(i)
fileName = ppts[i] # 文件名称
fromFile = os.path.join(filePath, fileName) # 文件地址
toFileName = changeSufix2Pdf(fileName) # 生成的文件名称
toFile = toFileJoin(filePath, toFileName) # 生成的文件地址
print("转换:" + fileName + "文件中...")
try:
ppt = powerpoint.Presentations.Open(fromFile, WithWindow=False)
if ppt.Slides.Count > 0:
ppt.SaveAs(toFile, 32) # 如果为空则会跳出提示框(暂时没有找到消除办法)
print("转换至:" + toFileName + "文件完成")
else:
print("(错误,发生意外:此文件为空,跳过此文件)")
except Exception as e:
print(e)
# 关闭 PPT 进程
print("所有 PPT 文件已打印完毕")
print("结束 PowerPoint 进程中...\n")
ppt.Close()
ppt = None
powerpoint.Quit()
powerpoint = None
except Exception as e:
print(e)
finally:
gc.collect()
# 修改后缀名
def changeSufix2Pdf(file):
return file[:file.rfind('.')] + ".pdf"
# 添加工作簿序号
def addWorksheetsOrder(file, i):
return file[:file.rfind('.')] + "_工作表" + str(i) + ".pdf"
# 转换地址
def toFileJoin(filePath, file):
return os.path.join(filePath, 'pdf', file[:file.rfind('.')] + ".pdf")
# 开始程序
print("====================程序开始====================")
print(
"【程序功能】将目标路径下内所有的 ppt、excel、word 均生成一份对应的 PDF 文件,存在新生成的 pdf 文件夹中(需已经安装office,不包括子文件夹)")
print(
"注意:若某 PPT 和 Excel 文件为空,则会出错跳过此文件。若转换 PPT 时间过长,请查看是否有报错窗口等待确认,暂时无法彻底解决 PPT 的窗口问题(为空错误已解决)。在关闭进程过程中,时间可能会较长,十秒左右,请耐心等待。")
# 需要转换的文件路径
# filePath = input("输入目标路径:(若为当前路径:" + os.getcwd() + ",请直接回车)\n")
filePath = "D:\Pycharmproject2023\code_test_project\shan_test\data"
# 目标路径,若没有输入路径则为当前路径
if (filePath == ""):
filePath = os.getcwd()
# 将目标文件夹所有文件归类,转换时只打开一个进程
words = []
ppts = []
excels = []
for fn in os.listdir(filePath):
if fn.endswith(('.doc', 'docx')):
words.append(fn)
if fn.endswith(('.ppt', 'pptx')):
ppts.append(fn)
if fn.endswith(('.xls', 'xlsx')):
excels.append(fn)
# 调用方法
print("====================开始转换====================")
# 保存路径:新建 pdf 文件夹,所有生成的 PDF 文件都放在里面
folder = filePath + '\\pdf\\'
if not os.path.exists(folder):
os.makedirs(folder)
word2Pdf(filePath, words)
excel2Pdf(filePath, excels)
ppt2Pdf(filePath, ppts)
print("====================转换结束====================")
print("\n====================程序结束====================")
# os.system("pause")三、实践效果
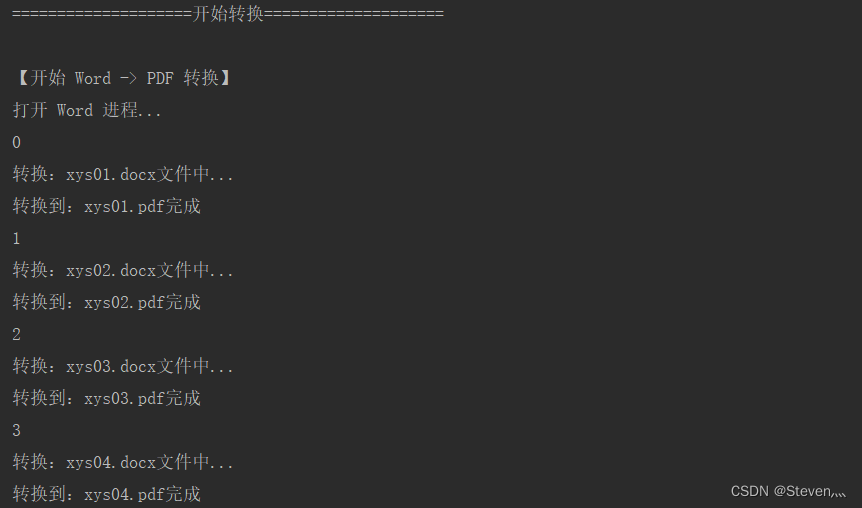
以上就是Python批量实现Word/EXCEL/PPT转PDF的详细内容,更多关于python word excel ppt转pdf的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了Python字典添加,删除,查询等相关操作方法详解,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python字典添加,删除,查询等相关操作方法详解,需要的朋友可以参考下2020-02-02 当用PyQt5开发一个GUI界面 ,需要执行业务逻辑时,后台逻辑执行时间长,界面就容易出现卡死、未响应等问题,本文主要介绍了PyQt界面阻塞卡死问题的解决2024-01-01
当用PyQt5开发一个GUI界面 ,需要执行业务逻辑时,后台逻辑执行时间长,界面就容易出现卡死、未响应等问题,本文主要介绍了PyQt界面阻塞卡死问题的解决2024-01-01 这篇文章主要介绍了python二分法查找算法实现方法,结合实例形式分析了Python使用递归与非递归算法实现二分查找的相关操作技巧,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python二分法查找算法实现方法,结合实例形式分析了Python使用递归与非递归算法实现二分查找的相关操作技巧,需要的朋友可以参考下2019-12-12 这篇文章主要介绍了Python的赋值、深拷贝与浅拷贝的区别,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python的赋值、深拷贝与浅拷贝的区别,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了Python分支语句常见的使用方法,Python分支语句,也称为选择语句,体现了程序的选择结构,即对应不同的场景,选择不同的处理方式,具体常见的用法需要的朋友可参考下面文章内容2022-06-06
这篇文章主要介绍了Python分支语句常见的使用方法,Python分支语句,也称为选择语句,体现了程序的选择结构,即对应不同的场景,选择不同的处理方式,具体常见的用法需要的朋友可参考下面文章内容2022-06-06
Python中if __name__ == ''__main__''作用解析
这篇文章主要介绍了Python中if __name__ == '__main__'作用解析,这断代码在Python中非常常见,它有作用?本文就解析了它的作用,需要的朋友可以参考下2015-06-06 今天我们主要来了解一下 Python 中的异常类型以及它们的处理方式。说到异常处理,我们首先要知道什么是异常。其实,异常就是一类事件,当它们发生时,会影响到程序的正常执行,具体内容跟随小编一起看看吧2021-08-08
今天我们主要来了解一下 Python 中的异常类型以及它们的处理方式。说到异常处理,我们首先要知道什么是异常。其实,异常就是一类事件,当它们发生时,会影响到程序的正常执行,具体内容跟随小编一起看看吧2021-08-08 这篇文章主要介绍了删除pycharm鼠标右键快捷键打开项目的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01
这篇文章主要介绍了删除pycharm鼠标右键快捷键打开项目的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01 本文主要系统性的讲解django rest framwork 序列化组件的使用,基本看完可以解决工作中序列化90%的问题,具有一定的参考价值,感兴趣的可以了解一下2021-09-09
本文主要系统性的讲解django rest framwork 序列化组件的使用,基本看完可以解决工作中序列化90%的问题,具有一定的参考价值,感兴趣的可以了解一下2021-09-09 PyCharm是一款由JetBrains开发的Python集成开发环境(IDE),它集成了代码编辑器、调试器、版本控制工具和测试工具等功能,下面这篇文章主要给大家介绍了关于pycharm安装包失败的解决方法,需要的朋友可以参考下2023-05-05
PyCharm是一款由JetBrains开发的Python集成开发环境(IDE),它集成了代码编辑器、调试器、版本控制工具和测试工具等功能,下面这篇文章主要给大家介绍了关于pycharm安装包失败的解决方法,需要的朋友可以参考下2023-05-05










最新评论