
Pandas之使用drop_duplicates:去除重复项
更新时间:2023年12月19日 09:58:04 作者:小虎AI实验室
这篇文章主要介绍了Pandas之使用drop_duplicates:去除重复项方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
前言
本文,我们讲述Pandas如何去除重复项的操作,我们选择一个评价数据集来演示如何删除特定列上的重复项,如何删除重复项并保留最后一次出现,以及drop_duplicates的默认用法
方法
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
返回值
这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。
返回删除重复行的 DataFrame。
考虑某些列是可选的。
索引(包括时间索引)将被忽略。
参数
返回DataFrame格式的数据。
- subset : column label or sequence of labels, optional
- 用来指定特定的列,默认所有列
- keep : {‘first’, ‘last’, False}, default ‘first’
- 删除重复项并保留第一次出现的项
- inplace : boolean, default False
- 是直接在原来数据上修改还是保留一个副本
实验
构建包含拉面评级的数据集
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
数据集数据格式
df
brand style rating
0 Yum Yum cup 4.0
1 Yum Yum cup 4.0
2 Indomie cup 3.5
3 Indomie pack 15.0
4 Indomie pack 5.0
默认情况下,它会根据所有列删除重复的行
df.drop_duplicates()
brand style rating
0 Yum Yum cup 4.0
2 Indomie cup 3.5
3 Indomie pack 15.0
4 Indomie pack 5.0
要删除特定列上的重复项,请使用subset
df.drop_duplicates(subset=['brand'])
brand style rating
0 Yum Yum cup 4.0
2 Indomie cup 3.5
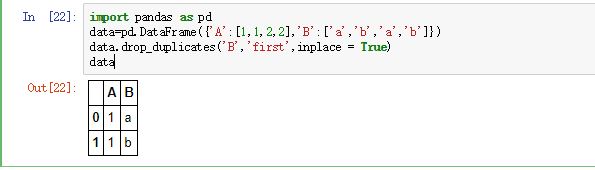
要删除重复项并保留最后一次出现,请使用 keep
df.drop_duplicates(subset=['brand', 'style'], keep='last')
brand style rating
1 Yum Yum cup 4.0
2 Indomie cup 3.5
4 Indomie pack 5.0
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
您可能感兴趣的文章:
相关文章
 这篇文章主要介绍了pytorch K折交叉验证过程说明及实现方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11
这篇文章主要介绍了pytorch K折交叉验证过程说明及实现方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11 这篇文章主要介绍了python爬虫学习笔记之pyquery模块基本用法,结合实例形式详细分析了python爬虫pyquery模块基本功能、用法及操作注意事项,需要的朋友可以参考下2020-04-04
这篇文章主要介绍了python爬虫学习笔记之pyquery模块基本用法,结合实例形式详细分析了python爬虫pyquery模块基本功能、用法及操作注意事项,需要的朋友可以参考下2020-04-04 这篇文章主要介绍了Python随机生成一个6位的验证码代码分享,本文直接给出代码实例,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了Python随机生成一个6位的验证码代码分享,本文直接给出代码实例,需要的朋友可以参考下2015-03-03 编写了一小段Python代码,将图片转为了Excel,纯属娱乐,下面这篇文章主要给大家介绍了关于利用python将图片转换成excel文档格式的相关资料,需要的朋友可以参考借鉴,下面来一起看看吧。2017-12-12
编写了一小段Python代码,将图片转为了Excel,纯属娱乐,下面这篇文章主要给大家介绍了关于利用python将图片转换成excel文档格式的相关资料,需要的朋友可以参考借鉴,下面来一起看看吧。2017-12-12 orm模型中的聚合函数跟MySQL中的聚合函数作用是一致的,也有像Sum、Avg、Count、Max、Min,接下来我们逐个介绍,下面就一起来了解一下2021-05-05
orm模型中的聚合函数跟MySQL中的聚合函数作用是一致的,也有像Sum、Avg、Count、Max、Min,接下来我们逐个介绍,下面就一起来了解一下2021-05-05
Python3.7在anaconda里面使用IDLE编译器的步骤详解
这篇文章主要介绍了Python3.7在anaconda里面使用IDLE编译器的步骤,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2020-04-04
通过Python中的http.server搭建文件上传下载服务功能
通过本文我们学习了如何使用Python的http.server模块搭建一个基本的HTTP服务器,并实现文件下载服务,介绍了如何设置服务器端口、自定义文件目录、定制HTTP响应头以及处理GET请求,感兴趣的朋友跟随小编一起看看吧2024-08-08 这篇文章主要介绍了如何向scrapy中的spider传递参数的几种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11
这篇文章主要介绍了如何向scrapy中的spider传递参数的几种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11 今天小编就为大家分享一篇python文件绝对路径写法介绍(windows),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12
今天小编就为大家分享一篇python文件绝对路径写法介绍(windows),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12 这篇文章主要介绍了Python实现弹球小游戏的方法,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-08-08
这篇文章主要介绍了Python实现弹球小游戏的方法,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-08-08










最新评论