
Python批量上传文件信息到服务器的实现示例
一、背景
在进行软件测试的过程中,经常会需要准备一批数据,这不,今天就遇到了:后端开发好了文件信息上传接口,可是前端并未开发出相关界面,而其他同学正在调试其他接口,需要用到文件信息,那么这个时候就需要我上场了
简而言之就是需要通过接口上传一批文件信息到服务器
二、准备工作
1.Python环境:家中常备,这个就不多说了
2.requests第三方库:用于向服务器发送请求,未安装的同学移步控制台输入以下命令
pip install requests
3.源文件:将不同类型的文件(excel、word、pdf)放到一个文件夹下
4.文件云存储地址:文件已经批量上传到了云服务器,文件云存储地址示例:https://your_file_head_url/file_name.pdf
5.上传接口:从接口文档查看接口地址、传参、响应等,没有接口文档的情况请同学们另辟蹊径
三、编写脚本
获取文件名和类型
源文件夹是这样的:
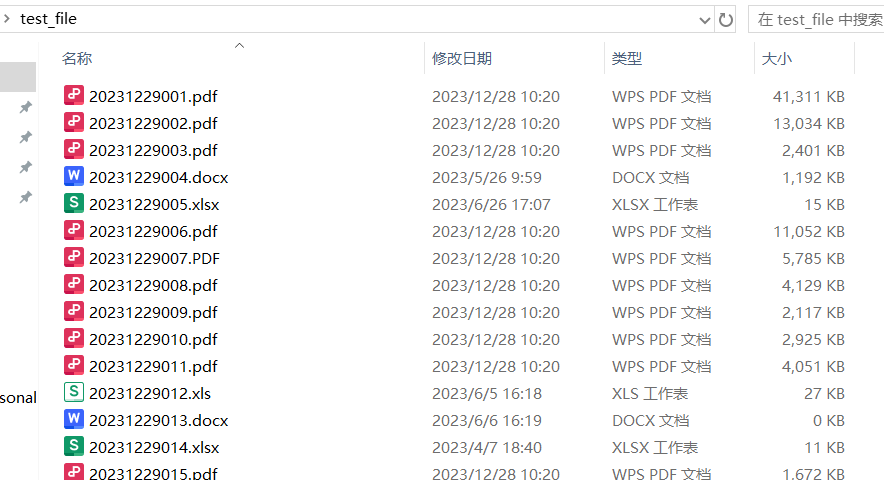
源文件名称是正常的,不包含“.”
源文件后缀也是正常的,与文件类型匹配
这里简单快速处理,使用split方法通过“.”将文件分割出名称和文件类型
dir_path = 'C:\\Users\\Administrator\\Desktop\\test_file'
# 获取文件名和类型
file_list = os.listdir(dir_path) # 文件列表
file_name_list = [] # 定义文件名列表
file_type_list = [] # 定义文件类型列表
for i in file_list:
file_name = i.split('.')[0] # 文件名
file_type = i.split('.')[-1] # 文件类型
file_name_list.append(file_name)
file_type_list.append(file_type)
print(file_name_list)
print(file_type_list)运行结果:

拼接文件信息
根据接口文档,上传的文件信息需要包含类型、名称、状态、url四个参数,这就需要对每个文件信息进行拼接
这里使用了enumerate函数来遍历文件名列表,可以枚举出列表的下标和值,灰常好用
注意:文件类型存在大写字母的情况(PDF,DOC等),所以使用lower函数将文件名转换为小写后再判断对应的参数值
# 拼接文件信息
file_url_head = 'https://your_file_head_url/' # 云存储地址
type_para_list = [1, 2, 3] # 文件类型列表:1--excel, 2--word, 3--pdf
file_msg_li = [] # 文件信息列表
for i, v in enumerate(file_name_list): # 遍历文件名列表
if file_type_list[i].lower() in ['xlsx', 'xls']:
type_para = 1
elif file_type_list[i].lower() in ['docx', 'doc']:
type_para = 2
elif file_type_list[i].lower() == 'pdf':
type_para = 3
else:
type_para = 0
file_msg = {
"file_type": type_para,
"name": v,
"status": random.choice(['true', 'false']), # 随机状态参数
"file_url": file_url_head + file_list[i] # 拼接文件url
}
file_msg_li.append(file_msg)
pprint(file_msg_li)运行结果:
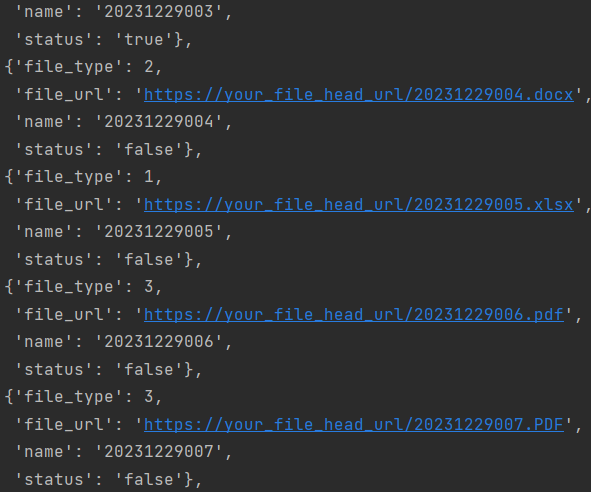
文件信息批量上传
使用requests.post方法请求接口即可
# 文件信息批量上传
for i in file_msg_li:
res = requests.post(url=server_url, json=i)
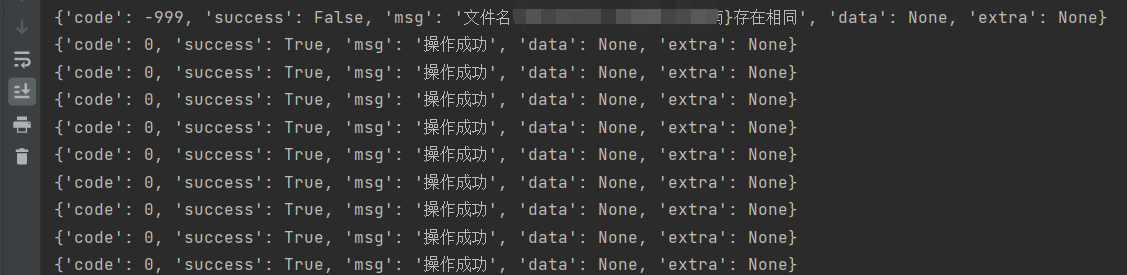
print(res.json())运行结果:
下面是控制台打印的接口请求返回结果:
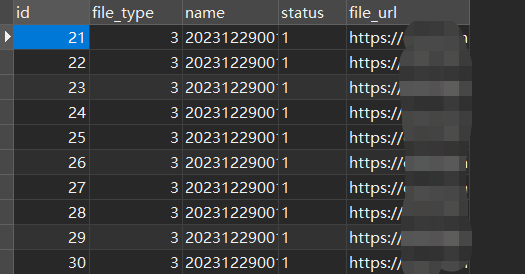
下图是数据库的查询结果:
四、优化
1.写到一个方法中,传入文件路径和地址等参数
2.使用列表推导式简化代码
3.文件类型列表改为字典,根据类型快速查找对应的参数
4添加接口响应异常情况处理
优化后完整代码:
import os
import random
import requests
def file_msg_to_server(dir_path, file_url_head, server_url):
# 获取文件名和类型
file_list = os.listdir(dir_path)
file_name_list = [i.split('.')[0] for i in file_list]
file_type_list = [i.split('.')[-1] for i in file_list]
# 拼接文件信息
type_para_dict = {'xlsx': 1, 'xls': 1, 'docx': 2, 'doc': 2, 'pdf': 3} # 文件类型字典:1--excel, 2--word, 3--pdf
file_msg_li = [{
"file_type": type_para_dict.get(file_type_list[i].lower(), 0), # 根据文件类型获取对应的参数值,若不存在则返回0
"name": v,
"status": random.choice(['true', 'false']), # 随机状态参数
"file_url": file_url_head + file_list[i] # 拼接文件url
} for i, v in enumerate(file_name_list)]
# 文件信息批量上传
for i in file_msg_li:
try:
res = requests.post(url=server_url, json=i)
res.raise_for_status()
return res.json()
except requests.exceptions.HTTPError as err:
return err
except requests.exceptions.Timeout as err:
return err
if __name__ == "__main__":
path = 'C:\\Users\\Administrator\\Desktop\\test_file'
url_head = 'https://your_file_head_url/' # 云存储地址
host = "http://your_server_url"
file_msg_to_server(path, url_head, host)到此这篇关于Python批量上传文件信息到服务器的实现示例的文章就介绍到这了,更多相关Python批量上传文件信息内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python使用列表的最佳方式,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-08-08
这篇文章主要介绍了python使用列表的最佳方式,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-08-08
python调用ffmpeg命令行工具便捷操作视频示例实现过程
现在短视频很流行,有很多视频编辑软件,功能丰富,而我们需要的只是裁剪功能,而且需要用编程的方式调用,那么最合适的莫过于ffmpeg了2021-11-11 在Python中将字典(dict)进行合并操作,是一个比较常见的问题。下面这篇文章主要给大家总结介绍了关于Python中字典(dict)合并的四种方法,需要的朋友可以参考借鉴,下面随着小编来一起学习学习吧。2017-08-08
在Python中将字典(dict)进行合并操作,是一个比较常见的问题。下面这篇文章主要给大家总结介绍了关于Python中字典(dict)合并的四种方法,需要的朋友可以参考借鉴,下面随着小编来一起学习学习吧。2017-08-08
tensorflow 用矩阵运算替换for循环 用tf.tile而不写for的方法
今天小编就为大家分享一篇tensorflow 用矩阵运算替换for循环 用tf.tile而不写for的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07 很多家长都想让孩子学习编程,今天我们给大家分享一下关于儿童python的入门以及简单的代码,有兴趣的朋友阅读下吧。2018-05-05
很多家长都想让孩子学习编程,今天我们给大家分享一下关于儿童python的入门以及简单的代码,有兴趣的朋友阅读下吧。2018-05-05 在数学计算、工程建模、物理分析等场景中,二次方程求根是基础且核心的需求,本文主要为大家详细介绍了如何使用Python实现二次方程求根,感兴趣的可以了解下2025-08-08
在数学计算、工程建模、物理分析等场景中,二次方程求根是基础且核心的需求,本文主要为大家详细介绍了如何使用Python实现二次方程求根,感兴趣的可以了解下2025-08-08
python批量处理多DNS多域名的nslookup解析实现
这篇文章主要介绍了python批量处理多DNS多域名的nslookup解析实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06 这篇文章主要为大家详细介绍了如何利用Python语言实现Gif图片分解功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起动手尝试一下2022-08-08
这篇文章主要为大家详细介绍了如何利用Python语言实现Gif图片分解功能,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起动手尝试一下2022-08-08 这篇文章主要介绍了Python多进程方式抓取基金网站内容的方法,结合实例形式分析了Python多进程抓取网站内容相关实现技巧与操作注意事项,需要的朋友可以参考下2019-06-06
这篇文章主要介绍了Python多进程方式抓取基金网站内容的方法,结合实例形式分析了Python多进程抓取网站内容相关实现技巧与操作注意事项,需要的朋友可以参考下2019-06-06 今天小编就为大家分享一篇查看django版本的方法分享,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
今天小编就为大家分享一篇查看django版本的方法分享,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05










最新评论