
Pandas如何获取数据的尺寸信息
更新时间:2024年02月23日 09:38:57 作者:勤奋的大熊猫
这篇文章主要介绍了Pandas如何获取数据的尺寸信息问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
Pandas获取数据的尺寸信息
Pandas中获取数据的尺寸信息,比如我们有如下的Excel数据:
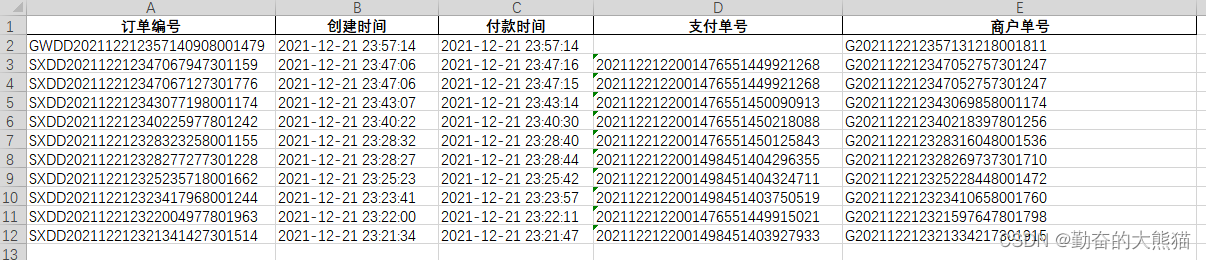
我们可以使用如下代码来获取数据的整体尺寸信息:
import pandas as pd file = pd.read_excel(r"C:\Users\15025\Desktop\uncle\debug.xlsx") print(file.size) print(file.shape) print(len(file)) """ result: 55 (11, 5) 11 """
可以看到,结果与numpy包中的结果类似,当我们的数据为二维时,使用size获取到的是数据的整体大小,为行数量11乘以列数量5。
当我们使用shape时,获取到的是二维数据行数量与列数量组成的一个元组(11, 5)。
当我们使用len()函数作用于二维数据时,我们获得的是行数量。
当数据为一维时,我们使用len()函数获取的结果将会与使用size获取到的结果一致。
pandas处理大数据信息
使用到的数据大小为130M
5 rows × 161 columns
g1.shape #(171907, 161) #17W的数据,有161列
pandas 可以处理几千万,上亿的数据
打印出每种类型占的内存量
for dtype in ['float64','int64','object']:
selected_dtype = g1.select_dtypes(include = [dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
mean_usage_mb = mean_usage_b/1024**2
print('平均内存占用 ',dtype , mean_usage_mb)
'''
deep : bool,默认为False
如果为True,则通过询问对象 dtype
来深入了解数据 的系统级内存消耗,
并将其包含在返回值中。
'''
让内存占用变小,int 类型从64 变为 32,在不影响使用的前提下
#查看每种类型最大 能表示多大的数
int_types = ['uint8','int8','int16','int32','int64']
for it in int_types:
print(np.iinfo(it))
g1_int = g1.select_dtypes(include = ['int64']) #生成一个只有int类型的DataFrame coverted_int = g1_int.apply(pd.to_numeric, downcast='unsigned') #apply 会将数据一条一条的读取,并传入目标进行执行 #int64 转换为了 unsigned
g1_float = g1.select_dtypes(include = ['float64']) #生成一个只有int类型的DataFrame coverted_floar = g1_int.apply(pd.to_numeric, downcast='float') #apply 会将数据一条一条的读取,并传入目标进行执行 #float64转换为了32
import pandas as pd
g1 = pd.read_csv('game_logs.csv')
g1_obj = g1.select_dtypes(include = ['object'])
g1.shape
#(171907, 78)
g1_obj.describe()
#查看信息生成的介绍
#count 数量
#unique 不重复的值
#top
#freq
dow = g1_obj.day_of_week
dow_cat = dow.astype('category')
dow_cat.head()
优化str占用内存
converted_obj = pd.DataFrame()
for col in g1_obj.columns:
num_unique_values = len(g1_obj[col].unique())
num_total_values= len(g1_obj[col])
if num_unique_values / num_total_values < 0.5:
converted_obj.loc[:,col] = g1_obj[col].astype('category')
else:
converted_obj.loc[:,col] = g1_obj[col]
#时间格式,写成标准格式的是比较占用内存的 #可以转换时间格式 g1['date'] = pd.to_datetime(date,format='%Y%m%d') #这种比较占用内存
结果:
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else:
usage_b = pandas_obj.memory_usagee(deep=True)
usage_mb = usage_b/1024**2
return '{:03.2f} MB'.format(usage_mb)
g1_int = g1.select_dtypes(include = ['int64'])
#生成一个只有int类型的DataFrame
coverted_int = g1_int.apply(pd.to_numeric, downcast='unsigned')
#apply 会将数据一条一条的读取,并传入目标进行执行
#int64 转换为了 unsigned
print(mem_usage(g1_int))
print(mem_usage(coverted_int))
7.87 MB
1.48 MB
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 七夕快到了,所以本文小编将给给大家介绍五种拿来就能用的炫酷表白代码,无限弹窗表白,爱心发射,心动表白,玫瑰花等表白代码,需要的小伙伴快来试试吧2023-08-08
七夕快到了,所以本文小编将给给大家介绍五种拿来就能用的炫酷表白代码,无限弹窗表白,爱心发射,心动表白,玫瑰花等表白代码,需要的小伙伴快来试试吧2023-08-08 这篇文章主要介绍了在 Python 中使用变量创建文件名,格式化的字符串文字使我们能够通过在字符串前面加上 f 来在字符串中包含表达式和变量,本文给大家详细讲解,需要的朋友可以参考下2023-03-03
这篇文章主要介绍了在 Python 中使用变量创建文件名,格式化的字符串文字使我们能够通过在字符串前面加上 f 来在字符串中包含表达式和变量,本文给大家详细讲解,需要的朋友可以参考下2023-03-03 这篇文章主要为大家介绍了django中使用memcached示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06
这篇文章主要为大家介绍了django中使用memcached示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06 这篇文章主要介绍了pytorch框架的详细介绍与应用,Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用,本文给大家详细讲解,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了pytorch框架的详细介绍与应用,Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用,本文给大家详细讲解,需要的朋友可以参考下2023-04-04 这篇文章主要介绍了Python多进程机制,以实例形式详细分析了Python多进程机制的原理与实现技巧,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了Python多进程机制,以实例形式详细分析了Python多进程机制的原理与实现技巧,需要的朋友可以参考下2015-07-07 这篇文章主要介绍了tensorflow常用函数API介绍,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04
这篇文章主要介绍了tensorflow常用函数API介绍,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04 这篇文章主要介绍了Python中序列与字典的相同和不同之处,序列这里讲到Python中最常用的列表和元组以及字典三种,需要的朋友可以参考下2016-01-01
这篇文章主要介绍了Python中序列与字典的相同和不同之处,序列这里讲到Python中最常用的列表和元组以及字典三种,需要的朋友可以参考下2016-01-01 Python Cook书中有很多章节都是针对某个库的使用进行介绍或是通过组合多个函数实现一些复杂的功能。我这里直接跳过了上一章节中对于文件处理的一些章节,直接进入对时间操作的章节。2008-09-09
Python Cook书中有很多章节都是针对某个库的使用进行介绍或是通过组合多个函数实现一些复杂的功能。我这里直接跳过了上一章节中对于文件处理的一些章节,直接进入对时间操作的章节。2008-09-09 这篇文章主要介绍了python drf各类组件的用法和作用,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2021-01-01
这篇文章主要介绍了python drf各类组件的用法和作用,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2021-01-01 在本篇文章里小编给大家整理了关于Python实现实时数据采集新型冠状病毒数据实例内容,有需要的朋友们可以学习参考下。2020-02-02
在本篇文章里小编给大家整理了关于Python实现实时数据采集新型冠状病毒数据实例内容,有需要的朋友们可以学习参考下。2020-02-02










最新评论