
基于Python实现IP代理池
一、引言
在网络爬虫或数据采集领域,IP代理池是一种常用的工具,用于隐藏真实IP地址、绕过IP限制或增加请求的匿名性。本文将详细介绍如何使用Python实现一个简单的IP代理池,包括代理IP的获取、验证和使用。
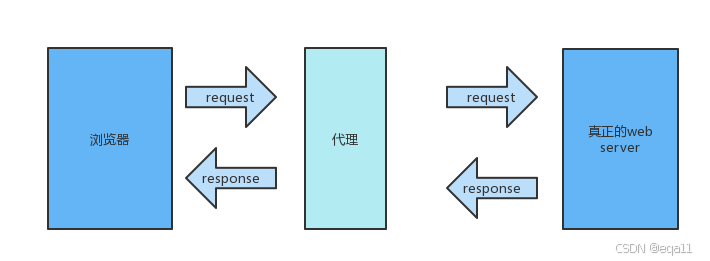
二、步骤一:获取代理IP
1、第一步:爬取代理IP
我们可以使用Python的requests和BeautifulSoup库来爬取公开的代理IP网站。以下是一个简单的代码示例,用于从代理网站获取IP地址和端口:
import requests
from bs4 import BeautifulSoup
def get_proxies():
url = 'https://www.xicidaili.com/nn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
proxies = []
for row in soup.find_all('tr')[1:]:
tds = row.find_all('td')
ip = tds[1].text
port = tds[2].text
protocol = tds[5].text.lower()
if protocol == 'http' or protocol == 'https':
proxies.append(f'{protocol}://{ip}:{port}')
return proxies
print(get_proxies())

2、第二步:验证代理IP的有效性
获取到代理IP后,我们需要验证这些IP是否可用。以下是一个简单的验证函数:
def check_proxy(proxy):
try:
response = requests.get('https://httpbin.org/ip', proxies={'http': proxy, 'https': proxy}, timeout=5)
if response.status_code == 200:
return True
except:
return False
return False
# 示例:验证代理IP
proxies = get_proxies()
valid_proxies = [proxy for proxy in proxies if check_proxy(proxy)]
print(valid_proxies)
三、步骤二:构建IP代理池
接下来,我们将创建一个IP代理池类,用于管理和轮换使用代理IP:
import random
class ProxyPool:
def __init__(self):
self.proxies = []
self.update_proxies()
def update_proxies(self):
self.proxies = [proxy for proxy in get_proxies() if check_proxy(proxy)]
print(f'Updated proxies: {self.proxies}')
def get_proxy(self):
if not self.proxies:
self.update_proxies()
return random.choice(self.proxies)
# 示例:使用代理池
proxy_pool = ProxyPool()
for _ in range(5):
proxy = proxy_pool.get_proxy()
print(f'Using proxy: {proxy}')
四、使用示例
在这一节中,我们将展示如何使用Python实现的IP代理池来发送网络请求。我们将使用requests库来发送请求,并使用我们之前创建的ProxyPool类来获取代理IP。
1、完整的使用示例
以下是一个完整的示例,展示了如何使用代理池来请求一个网页,并打印出网页的标题。
import requests
from bs4 import BeautifulSoup
from proxy_pool import ProxyPool # 假设我们已经定义了ProxyPool类
# 初始化代理池
proxy_pool = ProxyPool()
def fetch_with_proxy(url):
# 从代理池中获取一个代理
proxy = proxy_pool.get_proxy()
print(f'Using proxy: {proxy}')
# 设置代理
proxies = {
'http': proxy,
'https': proxy
}
try:
# 使用代理发送请求
response = requests.get(url, proxies=proxies, timeout=10)
response.raise_for_status() # 如果请求返回了一个错误状态码,抛出异常
return response.text
except requests.RequestException as e:
print(f'Request failed: {e}')
return None
# 要请求的网页
url = 'https://www.example.com'
# 使用代理池发送请求
html_content = fetch_with_proxy(url)
# 解析网页内容
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.title.string if soup.title else 'No title found'
print(f'Title of the page: {title}')
2、注意事项
异常处理:在发送请求时,可能会遇到各种异常,如连接超时、代理IP无效等。因此,我们需要捕获这些异常并进行处理。
超时设置:在请求中设置超时时间是一个好习惯,这可以避免程序在请求一个响应时间过长的代理时卡住。
网页解析:使用BeautifulSoup来解析网页内容,可以方便地提取网页的标题或其他元素。
3、处理网络问题
如果你在尝试访问https://www.example.com时遇到了网络问题,可能是因为以下原因:
代理IP无效:检查代理池中的IP是否有效,可能需要更新代理池。
网络连接问题:检查你的网络连接是否稳定。
网页链接问题:确保网页链接是正确的,没有拼写错误。
如果问题持续存在,建议检查代理IP的有效性,或者稍后再试。如果不需要代理,也可以尝试直接访问网页。
通过上述示例,你可以看到如何使用Python和IP代理池来发送网络请求,并处理可能出现的问题。这只是一个基本的示例,实际应用中可能需要更多的功能和错误处理。希望这个示例能帮助你理解如何使用IP代理池。
五、总结
本文介绍了如何使用Python制作一个简单的IP代理池。从获取代理IP、验证代理IP到创建代理池,这一系列步骤能够帮助你在网络爬虫和数据采集过程中更好地隐藏真实IP,提升成功率。当然,这只是一个基础示例,实际应用中可能需要更多的优化和完善,比如定期更新代理IP、处理更多的异常情况等。
以上就是基于Python实现IP代理池的详细内容,更多关于Python IP代理池的资料请关注脚本之家其它相关文章!
相关文章

详解Python中__new__和__init__的区别与联系
在Python中,每个对象都有两个特殊的方法:__new__和__init__,本文将详细介绍这两个方法的不同之处以及它们之间的联系,具有一定的参考价值,感兴趣的可以了解一下2023-12-12 这篇文章主要介绍了Python如何使用turtle库绘制图形,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python如何使用turtle库绘制图形,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02 在现代软件开发和自动化流程中,邮件通知是一个常见且实用的功能,无论是用于发送报告、告警信息还是用户提醒,通过 Python 实现自动化的邮件发送功能都能极大提升工作效率,本文将介绍基于Python实现自动化邮件发送系统的完整指南,需要的朋友可以参考下2025-08-08
在现代软件开发和自动化流程中,邮件通知是一个常见且实用的功能,无论是用于发送报告、告警信息还是用户提醒,通过 Python 实现自动化的邮件发送功能都能极大提升工作效率,本文将介绍基于Python实现自动化邮件发送系统的完整指南,需要的朋友可以参考下2025-08-08 这篇文章主要介绍了Python实现Windows上气泡提醒效果的方法,涉及Python针对windows窗口操作的相关技巧,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了Python实现Windows上气泡提醒效果的方法,涉及Python针对windows窗口操作的相关技巧,需要的朋友可以参考下2015-06-06 web.py是一款轻量级的Python web开发框架,简单、高效、学习成本低,特别适合作为python web开发的入门框架2016-04-04
web.py是一款轻量级的Python web开发框架,简单、高效、学习成本低,特别适合作为python web开发的入门框架2016-04-04 这篇文章主要介绍了Python实现查询剪贴板自动匹配信息,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-07-07
这篇文章主要介绍了Python实现查询剪贴板自动匹配信息,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-07-07 这篇文章主要介绍了Python统计分析模块statistics用法,结合实例形式分析了Python统计分析模块statistics计算平均数、中位数、出现次数、标准差等相关操作技巧,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了Python统计分析模块statistics用法,结合实例形式分析了Python统计分析模块statistics计算平均数、中位数、出现次数、标准差等相关操作技巧,需要的朋友可以参考下2019-09-09 在使用Python进行开发时,安装各种第三方库是必不可少的,不过,有时候我们会遇到一些麻烦,尤其是当pip的版本较低时,下面我们来看看如何解决这一问题吧2025-03-03
在使用Python进行开发时,安装各种第三方库是必不可少的,不过,有时候我们会遇到一些麻烦,尤其是当pip的版本较低时,下面我们来看看如何解决这一问题吧2025-03-03 这篇文章主要介绍了Python闭包与装饰器原理及实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04
这篇文章主要介绍了Python闭包与装饰器原理及实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04
Python数据结构与算法之图的最短路径(Dijkstra算法)完整实例
这篇文章主要介绍了Python数据结构与算法之图的最短路径(Dijkstra算法),结合完整实例形式分析了Python图的最短路径算法相关原理与实现技巧,需要的朋友可以参考下2017-12-12










最新评论