
Python重复文件批量整理工具的设计与实现
更新时间:2025年02月09日 07:56:11 作者:黑客白泽
这篇文章主要为大家详细介绍了如何通关Python编写一个重复文件批量整理工具,可以在文件夹内对文件进行去重和分类存储,有需要的可以了解下
1. 简介
这款文件整理工具主要用于在文件夹内对文件进行去重和分类存储,尤其适用于处理图片等文件类型。用户可以通过选择源目录、目标目录、重复文件目录以及非重复文件目录,快速完成文件分类和去重工作。工具支持读取 MD5 列表来识别重复文件,并根据文件的修改时间进行分类存储。此外,工具还支持多线程处理,避免界面卡顿,提升用户体验。
功能
1.目录选择和配置:
- 支持设置基准目录、目标目录、重复文件目录和非重复文件目录。
- 支持通过浏览按钮快速选择文件夹路径。
2.文件去重和分类:
- 使用 MD5 校验码对文件进行去重,判断文件是否重复。
- 如果启用了 MD5 列表,工具会加载先前保存的 MD5 列表,以加速去重过程。
- 根据文件的修改时间,自动将文件按年和月分类存储。
3.多线程处理:
- 采用多线程技术,使得文件处理过程不阻塞主线程,确保界面保持响应。
- 文件的移动操作在后台线程中进行,避免影响 UI 界面的流畅性。
4.支持图片文件类型:
- 支持常见图片格式,如 JPEG、PNG、BMP 和 HEIC。
- 对 HEIC 文件进行特殊处理,提取文件的 EXIF 时间戳,作为文件分类的依据。
5.日志记录:
- 提供实时日志记录功能,记录文件处理的详细过程。
- 支持日志批量更新,减少对 UI 的频繁更新,提高性能。
6.MD5 列表管理:
可加载和保存 MD5 列表,记录基准文件的 MD5 值,帮助后续识别重复文件。
使用方法
配置目录:
- 启动工具后,首先配置四个文件夹路径:
- 基准目录:包含待处理文件的源目录。
- 目标目录:包含待比对的目标文件夹。
- 重复文件目录:存放重复文件的目录。
- 非重复文件目录:存放未重复文件的目录。
选择选项:
- 启用“读取 MD5 列表”选项来加载已保存的 MD5 列表。
- 启用“启用分类存储”选项将文件按年和月进行分类存储。
开始处理:
- 点击“开始处理”按钮,工具会自动扫描源目录和目标目录,识别重复文件并进行分类存储。
- 处理过程中,工具会在日志框中显示详细的操作信息。
文件分类与去重:
- 工具根据文件的 MD5 校验码判断是否为重复文件,重复文件将移动到指定的“重复文件目录”。
- 未重复的文件将按其修改时间(年月)分类,存放到指定的“非重复文件目录”中。
完成处理:
文件处理完成后,工具会在日志框中显示相关信息,并自动保存更新的 MD5 列表到“非重复文件目录”中。
2. 运行效果
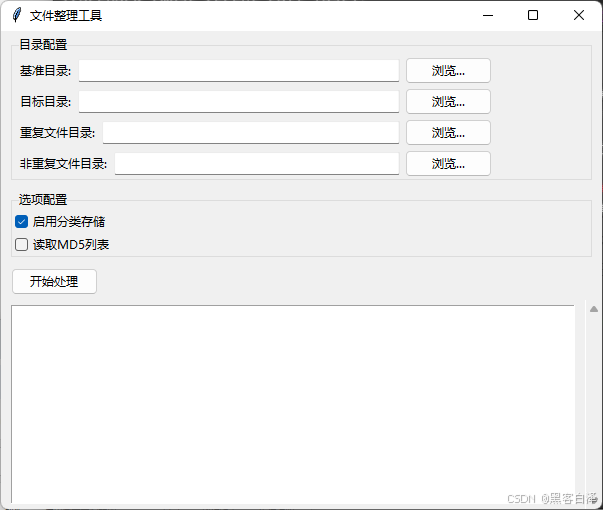
3.相关源码
import os
import hashlib
import shutil
import json
import threading
import re
import io
import exifread
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from datetime import datetime
from PIL import Image
from PIL.ExifTags import TAGS
import pillow_heif
from pillow_heif import register_heif_opener
class FileOrganizerApp:
def __init__(self, root):
self.root = root
self.root.title("文件整理工具")
# 变量初始化
self.base_dir = tk.StringVar()
self.target_dir = tk.StringVar()
self.duplicate_dir = tk.StringVar()
self.unique_dir = tk.StringVar()
self.enable_classify = tk.BooleanVar(value=True)
self.enable_md5list = tk.BooleanVar(value=False)
self.dictfile_name = "base_md5_list.txt"
# 创建register_heif_opener模块里的一个类然后再Image.open打开HEIC文件
register_heif_opener()
# 创建界面组件
self.create_widgets()
def create_widgets(self):
# 目录选择部分
dir_frame = ttk.LabelFrame(self.root, text="目录配置")
dir_frame.pack(padx=10, pady=5, fill=tk.X)
self.create_dir_selector(dir_frame, "基准目录:", self.base_dir, 0)
self.create_dir_selector(dir_frame, "目标目录:", self.target_dir, 1)
self.create_dir_selector(dir_frame, "重复文件目录:", self.duplicate_dir, 2)
self.create_dir_selector(dir_frame, "非重复文件目录:", self.unique_dir, 3)
# 选项配置
opt_frame = ttk.LabelFrame(self.root, text="选项配置")
opt_frame.pack(padx=10, pady=5, fill=tk.X)
ttk.Checkbutton(opt_frame, text="启用分类存储", variable=self.enable_classify).pack(anchor=tk.W)
ttk.Checkbutton(opt_frame, text="读取MD5列表", variable=self.enable_md5list).pack(anchor=tk.W)
# 操作按钮
btn_frame = ttk.Frame(self.root)
btn_frame.pack(padx=10, pady=5, fill=tk.X)
ttk.Button(btn_frame, text="开始处理", command=self.start_processing).pack(side=tk.LEFT)
# 日志显示
self.log_text = tk.Text(self.root, height=15)
self.scrollbar = tk.Scrollbar(root, command=self.log_text.yview)
self.scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.log_text.config(yscrollcommand=self.scrollbar.set)
self.log_text.pack(padx=10, pady=5, fill=tk.BOTH, expand=True)
def create_dir_selector(self, parent, label, var, row):
frame = ttk.Frame(parent)
frame.grid(row=row, column=0, sticky="ew", padx=5, pady=2)
ttk.Label(frame, text=label).pack(side=tk.LEFT)
entry = ttk.Entry(frame, textvariable=var, width=40)
entry.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=5)
ttk.Button(frame, text="浏览...", command=lambda: self.select_directory(var)).pack(side=tk.LEFT)
def select_directory(self, var):
dir_path = filedialog.askdirectory()
if dir_path:
var.set(dir_path)
def log(self, message):
# 批量更新日志,减少频繁刷新UI
self.log_text.insert(tk.END, message + "\n")
self.root.update_idletasks()
def calculate_md5(self, filepath):
hash_md5 = hashlib.md5()
with open(filepath, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
def save_dict_to_file(self, dictionary, file_path):
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(dictionary, file, ensure_ascii=False, indent=4)
def load_dict_from_file(self, file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return json.load(file)
def get_unique_filename(self, dest_dir, filename):
base, ext = os.path.splitext(filename)
counter = 1
new_name = filename
while os.path.exists(os.path.join(dest_dir, new_name)):
new_name = f"{base}_{counter}{ext}"
counter += 1
return new_name
def is_image(self, file_path):
ext = os.path.splitext(file_path)[1].lower()
return ext in [".jpg", ".jpeg", ".png", ".bmp", ".heic"]
def get_file_time(self, file_path):
mtime = os.path.getmtime(file_path)
ext = os.path.splitext(file_path)[1].lower()
if self.is_image(file_path):
if ext == ".heic":
mtime = self.get_heic_original(file_path)
mtime = self.replace_limited(mtime, ':', '-', 2)
dt_object = datetime.strptime(mtime, "%Y-%m-%d %H:%M:%S")
mtime = dt_object.timestamp()
else:
with open(file_path, 'rb') as f:
tags = exifread.process_file(f, details=False)
if 'EXIF DateTimeOriginal' in tags:
mtime = str(tags['EXIF DateTimeOriginal'])
mtime = self.replace_limited(mtime, ':', '-', 2)
dt_object = datetime.strptime(mtime, "%Y-%m-%d %H:%M:%S")
mtime = dt_object.timestamp()
return mtime
def process_files(self):
base_files = {}
if self.enable_md5list.get():
base_md5_path = os.path.join(self.base_dir.get(), self.dictfile_name)
if os.path.exists(base_md5_path):
base_files = self.load_dict_from_file(base_md5_path)
self.log(f"基准MD5已加载: {base_md5_path}")
else:
for root, _, files in os.walk(self.base_dir.get()):
for file in files:
path = os.path.join(root, file)
md5 = self.calculate_md5(path)
base_files[md5] = file
self.log(f"基准文件已扫描: {path}")
for root, _, files in os.walk(self.target_dir.get()):
for file in files:
src_path = os.path.join(root, file)
md5 = self.calculate_md5(src_path)
self.log(f"正在处理: {src_path}")
if md5 in base_files:
dest_dir = self.duplicate_dir.get()
dest_path = os.path.join(dest_dir, self.get_unique_filename(dest_dir, file))
shutil.move(src_path, dest_path)
self.log(f"重复文件已移动: {dest_path}")
else:
if self.enable_classify.get():
mtime = self.get_file_time(src_path)
date_dir_Y = datetime.fromtimestamp(mtime).strftime("%Y")
date_dir_m = datetime.fromtimestamp(mtime).strftime("%m")
dest_dir = os.path.join(self.unique_dir.get(), date_dir_Y, date_dir_m)
else:
dest_dir = self.unique_dir.get()
os.makedirs(dest_dir, exist_ok=True)
dest_path = os.path.join(dest_dir, self.get_unique_filename(dest_dir, file))
shutil.move(src_path, dest_path)
self.log(f"非重复文件已移动: {dest_path}")
dest_md5_path = os.path.join(self.unique_dir.get(), self.dictfile_name)
self.save_dict_to_file(base_files, dest_md5_path)
self.log(f"基准MD5已输出: {dest_md5_path}")
def start_processing(self):
try:
dirs = [
self.base_dir.get(),
self.target_dir.get(),
self.duplicate_dir.get(),
self.unique_dir.get()
]
for d in dirs:
if not d:
raise ValueError("所有目录都必须设置")
os.makedirs(d, exist_ok=True)
# 启动新线程处理文件
threading.Thread(target=self.process_files, daemon=True).start()
messagebox.showinfo("完成", "文件处理已开始,请稍候!")
except Exception as e:
messagebox.showerror("错误", str(e))
self.log(f"错误发生: {str(e)}")
if __name__ == "__main__":
root = tk.Tk()
app = FileOrganizerApp(root)
root.mainloop()
4.总结
这款文件整理工具是一个高效且易于使用的文件去重和分类存储工具。它结合了 MD5 校验和文件时间戳分类,确保用户能够快速识别重复文件并将文件按时间进行合理分类。工具采用了多线程技术,有效避免了长时间操作导致的界面卡顿,提供了流畅的用户体验。通过日志记录和 MD5 列表管理,用户可以清晰地了解文件处理的每一步操作。此外,该工具支持多种常见的图片格式,且对 HEIC 文件进行了专门的处理,使其适应了现代文件管理的需求。
以上就是Python重复文件批量整理工具的设计与实现的详细内容,更多关于Python整理重复文件的资料请关注脚本之家其它相关文章!
相关文章

安装python依赖包psycopg2来调用postgresql的操作
这篇文章主要介绍了安装python依赖包psycopg2来调用postgresql的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01 语音转文字的核心是通过信号处理、特征提取和模式识别将声波转换为文本,下面这篇文章主要介绍了主流Python语音转文字(STT)库的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考下2026-01-01
语音转文字的核心是通过信号处理、特征提取和模式识别将声波转换为文本,下面这篇文章主要介绍了主流Python语音转文字(STT)库的相关资料,文中通过代码介绍的非常详细,需要的朋友可以参考下2026-01-01 这篇文章主要介绍了Python中用pycurl监控http响应时间脚本分享,本文脚本实现监控http相应码,响应大小,建立连接时间,准备传输时间,传输第一个字节时间,完成时间,需要的朋友可以参考下2015-02-02
这篇文章主要介绍了Python中用pycurl监控http响应时间脚本分享,本文脚本实现监控http相应码,响应大小,建立连接时间,准备传输时间,传输第一个字节时间,完成时间,需要的朋友可以参考下2015-02-02
Python实现Window路径格式转换为Linux路径格式的代码
这篇文章主要介绍了Python实现Window路径格式转换为Linux路径格式的方法,文中通过代码示例讲解的非常详细,对大家的学习或工作有一定的帮助,需要的朋友可以参考下2024-07-07 这篇文章主要介绍了Python统计文件中去重后uuid个数的方法,实例分析了Python正则匹配及字符串操作的相关技巧,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了Python统计文件中去重后uuid个数的方法,实例分析了Python正则匹配及字符串操作的相关技巧,需要的朋友可以参考下2015-07-07 这篇文章主要介绍了python包实现time时间管理操作,文章通过获取当前时间戳,即当前系统内表示时间的一个浮点数,下文更多相关内容需要的小伙伴可以参考一下2022-04-04
这篇文章主要介绍了python包实现time时间管理操作,文章通过获取当前时间戳,即当前系统内表示时间的一个浮点数,下文更多相关内容需要的小伙伴可以参考一下2022-04-04 今天小编就为大家分享一篇Python Pywavelet 小波阈值实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇Python Pywavelet 小波阈值实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 这篇文章主要介绍了关于PyQt5主窗口图标显示问题汇总,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03
这篇文章主要介绍了关于PyQt5主窗口图标显示问题汇总,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03 这篇文章主要为大家详细介绍了常用python编程模板,总结了Python编程常用模板,感兴趣的朋友可以参考一下2016-02-02
这篇文章主要为大家详细介绍了常用python编程模板,总结了Python编程常用模板,感兴趣的朋友可以参考一下2016-02-02 这篇文章主要介绍了编写自定义的Django模板加载器的简单示例,Django是各色人气Python框架中最为著名的一个,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了编写自定义的Django模板加载器的简单示例,Django是各色人气Python框架中最为著名的一个,需要的朋友可以参考下2015-07-07










最新评论