
Python实现将PDF文件拆分任意页数
更新时间:2025年02月12日 09:49:03 作者:py小王子
PyMuPDF,简称fitz,是一个轻量级的Python库,它简化和封装了PyMuPDF的功能,使得在Python中处理PDF文件更加简单,下面我们来看看如何使用他将PDF拆分任意页数
一、简介
PyMuPDF,简称fitz,是一个轻量级的Python库,它基于MuPDF的C++库,提供了丰富的功能,包括但不限于PDF的读取、编辑、转换和渲染。Fitz作为PyMuPDF的子模块,简化和封装了PyMuPDF的功能,使得在Python中处理PDF文件更加简单。
二、安装
PyMuPDF(包含fitz模块)可以通过Python的包管理器pip来安装。
在命令行工具中输入以下命令:
pip install PyMuPDF
这将从Python包索引下载并安装PyMuPDF及其依赖项。
或者
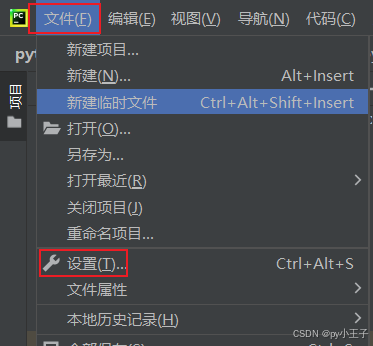
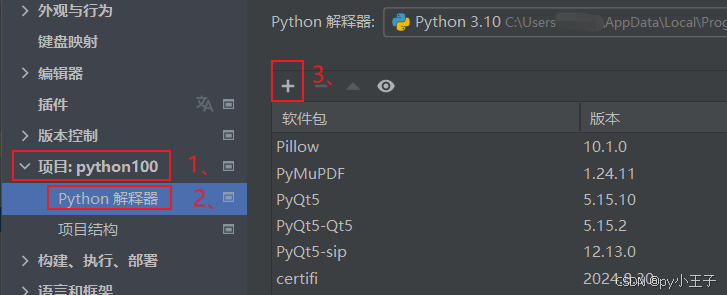
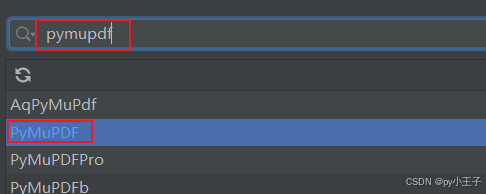

三、基本功能
1、打开PDF文件:
使用fitz.open()函数可以打开一个PDF文件,并返回一个表示该文件的对象。例如:
import fitz
doc = fitz.open("example.pdf")2、获取页面数量:
通过page_count属性可以获取PDF文件的总页数。例如:
page_count = doc.page_count
print("Number of pages:", page_count)3、提取文本:
使用get_text()方法可以提取当前页面的所有文本。例如:
text = page.get_text()
print("Extracted text:", text)此外,还可以遍历文档中的每一页,提取每一页的文本。
4、保存修改后的PDF:
使用save()方法可以保存对PDF文件所做的更改。例如:
doc.save("modified_example.pdf")
其他功能:
- 插入新的页面:使用
fitz.new_page()创建新页面,然后使用insert_pdf()方法将新页面插入到指定位置。 - 合并多个PDF文件:创建一个空的PDF文档对象,然后遍历要合并的PDF文件,将它们的页面插入到新的文档对象中,最后保存合并后的PDF。
- 提取PDF中的图片:遍历PDF的每一页,使用
get_images()方法获取页面上的所有图像,并保存它们。 - 提取PDF中的表格:使用
find_tables()方法获取页面上的表格,然后可以将表格数据保存为CSV格式文件。 四、应用场景
四、应用场景
PyMuPDF(fitz)适用于需要处理PDF文件的各种场景,如文本提取、页面操作、PDF合并与分割等。它以其快速、高效和易于使用而著称,是处理PDF文件的理想选择。
例如:PDF文件拆分任意页数.py
import fitz
import os
def split_pdf(pdf_path):
# 检查输入的PDF文件是否存在
if not os.path.exists(pdf_path):
print("您输入的路径无pdf文件!")
return
# 打开pdf文件
doc = fitz.open(pdf_path)
page_count = len(doc)
print(f"该pdf文件页数为:{page_count}")
while True:
# 获取起始页码(0基索引)
page_num1 = None
while True:
try:
user_input = input("请输入您拆分的起始页码(输入q/Q退出):")
if user_input.lower() == 'q':
doc.close()
return
page_num1 = int(user_input) - 1
if page_num1 < 0 or page_num1 >= page_count:
print("起始页码无效,请重新输入。")
else:
break
except ValueError:
print("请输入有效的起始页码或q/Q退出。")
# 获取结束页码(0基索引)
page_num2 = None
while True:
try:
user_input = input("请输入您拆分的截止页码(输入q/Q退出):")
if user_input.lower() == 'q':
doc.close()
return
page_num2 = int(user_input) - 1
if page_num2 < 0 or page_num2 >= page_count:
print("截止页码无效,请重新输入。")
else:
break
except ValueError:
print("请输入有效的截止页码或q/Q退出。")
# 创建一个新的PDF文档并插入指定的页面范围
new_doc = fitz.open()
new_doc.insert_pdf(doc, from_page=page_num1, to_page=page_num2)
# 获取用户输入的PDF基础名字和保存目录
pdf_base_name = input("请输入您的PDF基础名字:")
if not pdf_base_name.lower().endswith('.pdf'):
pdf_name = f"{pdf_base_name}_{page_num1 + 1}-{page_num2 + 1}.pdf"
else:
pdf_name = f"{pdf_base_name[:-4]}_{page_num1 + 1}-{page_num2 + 1}.pdf"
save_dir = input("请输入您想要保存PDF的目录(例如:C:/Users/YourName/Documents/):")
# 确保目录末尾有斜杠,并检查目录是否存在
if not save_dir.endswith(os.sep) and save_dir != "":
save_dir += os.sep
os.makedirs(save_dir, exist_ok=True)
output_path = os.path.join(save_dir, pdf_name)
new_doc.save(output_path)
new_doc.close()
print(f"Saved: {output_path}")
# 检查是否继续拆分或退出
is_continue = input("是否继续拆分其他页面范围(q/Q退出)?").strip().lower()
if is_continue == 'q':
doc.close()
break
# 调用函数进行PDF拆分
pdf_path = input("请输入您需要拆分的PDF路径:")
split_pdf(pdf_path)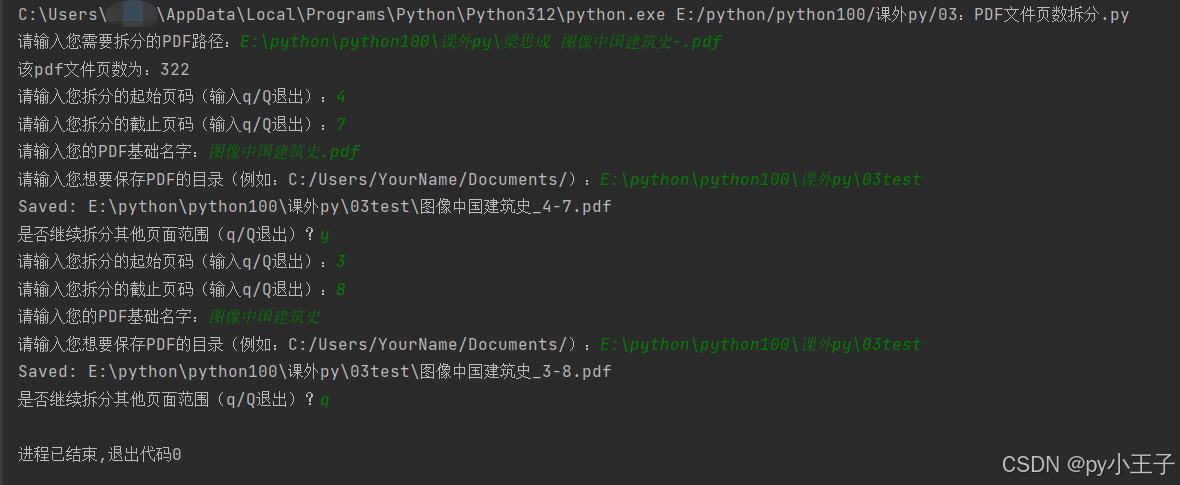
到此这篇关于Python实现将PDF文件拆分任意页数的文章就介绍到这了,更多相关Python PDF拆分内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 在做python编程时,碰到了需要将字母转换成ascii码的需求,所以下面这篇文章主要给大家介绍了关于Python字符与ASCII码相互转换的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2023-06-06
在做python编程时,碰到了需要将字母转换成ascii码的需求,所以下面这篇文章主要给大家介绍了关于Python字符与ASCII码相互转换的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2023-06-06
python的pywebview库结合Flask和waitress开发桌面应用程序完整代码
pywebview是轻量级Python库,用于创建跨平台桌面应用,结合HTML/CSS/JS界面与Python交互,支持Windows/macOS/Linux,资源占用低,可与Flask、Waitress集成,便于开发、部署,本文给大家介绍python的pywebview库结合Flask和waitress开发桌面应用程序简介,感兴趣的朋友一起看看吧2025-07-07 这篇文章主要介绍了Python with/as使用说明,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-12-12
这篇文章主要介绍了Python with/as使用说明,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-12-12
如何使用Python修改matplotlib.pyplot.colorbar的位置以对齐主图
使用matplotlib.colors模块可以完成大多数常见的任务,下面这篇文章主要给大家介绍了关于如何使用Python修改matplotlib.pyplot.colorbar的位置以对齐主图的相关资料,需要的朋友可以参考下2022-07-07 这篇文章主要介绍了python 实现tar文件压缩解压的实例详解的相关资料,这里提供实现方法,帮助大家学习理解这部分内容,需要的朋友可以参考下2017-08-08
这篇文章主要介绍了python 实现tar文件压缩解压的实例详解的相关资料,这里提供实现方法,帮助大家学习理解这部分内容,需要的朋友可以参考下2017-08-08 本文介绍了在Python中调用和运行其他.py文件的四种方法:subprocess模块、exec函数、import语句和os.system函数,每种方法都有其适用场景和优缺点2025-02-02
本文介绍了在Python中调用和运行其他.py文件的四种方法:subprocess模块、exec函数、import语句和os.system函数,每种方法都有其适用场景和优缺点2025-02-02 这篇文章主要介绍了Python列表嵌套常见坑点及解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-09-09
这篇文章主要介绍了Python列表嵌套常见坑点及解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-09-09 工欲善其事必先利其器,Pycharm 是最受欢迎的Python开发工具,它提供的功能非常强大,是构建大型项目的理想工具之一,如果能挖掘出里面实用技巧,能带来事半功倍的效果2018-04-04
工欲善其事必先利其器,Pycharm 是最受欢迎的Python开发工具,它提供的功能非常强大,是构建大型项目的理想工具之一,如果能挖掘出里面实用技巧,能带来事半功倍的效果2018-04-04 这篇文章主要为大家详细介绍了python使用梯度下降算法实现一个多线性回归,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-03-03
这篇文章主要为大家详细介绍了python使用梯度下降算法实现一个多线性回归,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-03-03 今天小编就为大家分享一篇解决tensorflow打印tensor有省略号的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
今天小编就为大家分享一篇解决tensorflow打印tensor有省略号的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02










最新评论