
如何使用 Python 实现 DeepSeek R1 本地化部署
DeepSeek R1 以其出色的表现脱颖而出,不少朋友想将其本地化部署,网上基于 ollama 的部署方式有很多,但今天我要带你领略一种全新的方法 —— 使用 Python 实现 DeepSeek R1 本地化部署,让你轻松掌握,打造属于自己的 AI 小助手。
硬件环境
要想让 DeepSeek R1 顺畅运行,硬件得跟上。你的电脑至少得配备 8GB 内存 ,要是想运行更大的模型,比如 7B 及以上的,那最好有更强劲的 CPU 和 GPU,内存也得相应增加。
Python 环境
安装 Python 3.8 及以上版本,这是后续部署的关键工具,Python 丰富的库和灵活的编程特性,能帮我们更好地实现部署。
安装依赖包
打开命令行工具,使用 pip 安装 DeepSeek R1 运行所需要的依赖包。比如,如果模型依赖一些自然语言处理相关的库,像 NLTK、transformers 等,都可以通过 pip 一键安装 :
pip install nltk transformers
Python 代码配置与运行:
编写 Python 脚本,导入必要的库,比如 transformers 库,用于加载和处理 DeepSeek R1 模型 :(这里以1.5B模型为例)
from transformers import AutoTokenizer, AutoModelForCausalLM
import os
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
model_path = "./model/deepseek_1.5b"
if not os.path.exists(model_path):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
print("Model loaded successfully.")
model.save_pretrained(model_path)
tokenizer.save_pretrained(model_path)
else:
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)实现与模型的交互逻辑,将输入传递给模型进行处理,并输出模型的回复 :
# 使用模型生成文本 input_text = "你好,世界!" input_ids = tokenizer.encode(input_text, return_tensors="pt") output = model.generate(input_ids, max_length=100) print(tokenizer.decode(output[0], skip_special_tokens=True))
等待模型加载完成,并完成推理结果如下:
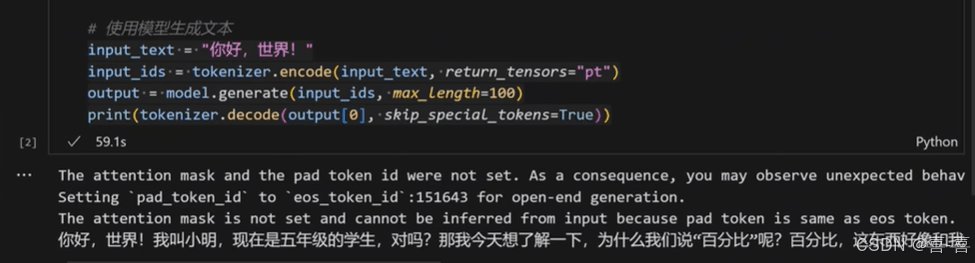
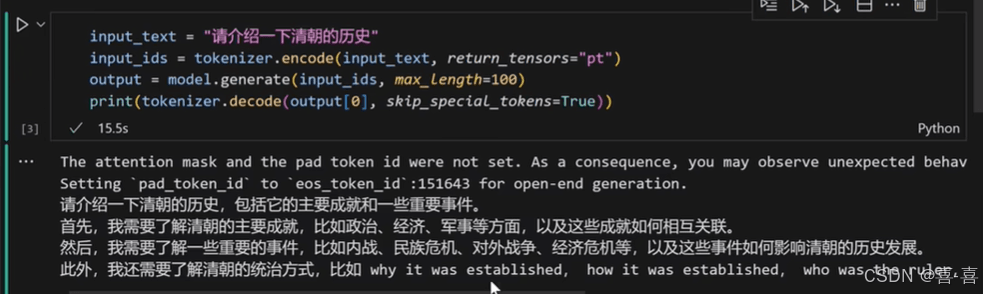
完整代码:
from transformers import AutoTokenizer, AutoModelForCausalLM
import os
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
model_path = "./model/deepseek_1.5b"
if not os.path.exists(model_path):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
print("Model loaded successfully.")
model.save_pretrained(model_path)
tokenizer.save_pretrained(model_path)
else:
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
# 使用模型生成文本
input_text = "你好,世界!"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
通过以上用 Python 实现 DeepSeek R1 本地化部署的步骤,你就可以在自己的设备上轻松运行 DeepSeek R1,享受本地化 AI 带来的便捷与高效,无论是用于日常的文本处理,还是更专业的自然语言处理任务,都能轻松应对。赶紧动手试试吧!
特别提醒:如果执行代码时,报如下错误,表示您无法访问网站https://huggingface.co来下载相关资源,请通过合理方式保障主机能够访问网站https://huggingface.co
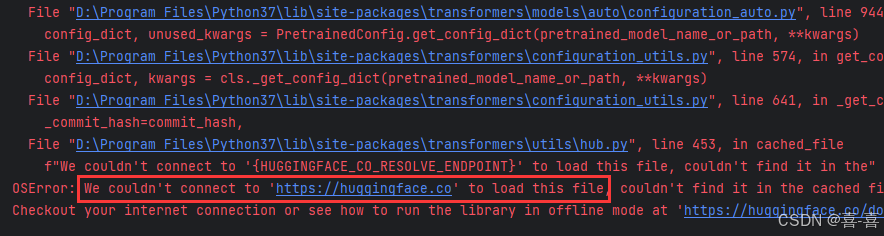
到此这篇关于用Python实现DeepSeekR1本地化部署的文章就介绍到这了,更多相关PythonDeepSeekR1本地化部署内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

python调用cmd命令时遇到的路径空格问题和中文乱码的解决
这篇文章主要介绍了python调用cmd命令时遇到的路径空格问题和中文乱码的解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02 今天小编就为大家分享一篇Tensorflow的梯度异步更新示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01
今天小编就为大家分享一篇Tensorflow的梯度异步更新示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01 这篇文章主要介绍了解读等值线图的Python绘制方法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了解读等值线图的Python绘制方法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 在C++编程中,文件操作是常见的需求之一,本文将深入探讨如何使用std::ofstream将文件保存到特定的磁盘路径,特别是D盘,并分析各种路径表示方法的优缺点,希望对大家有所帮助2025-12-12
在C++编程中,文件操作是常见的需求之一,本文将深入探讨如何使用std::ofstream将文件保存到特定的磁盘路径,特别是D盘,并分析各种路径表示方法的优缺点,希望对大家有所帮助2025-12-12 python实现串口通信是一件简单的事情,只要通过pyserial模块就可以实现,本文主要介绍了python实现串口通信的示例代码,感兴趣的可以了解一下2023-10-10
python实现串口通信是一件简单的事情,只要通过pyserial模块就可以实现,本文主要介绍了python实现串口通信的示例代码,感兴趣的可以了解一下2023-10-10 今天小编就为大家分享一篇tensorflow 中对数组元素的操作方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07
今天小编就为大家分享一篇tensorflow 中对数组元素的操作方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07
python为tornado添加recaptcha验证码功能
tornado作为微框架,并没有自带验证码组件,recaptcha是著名的验证码解决方案,简单易用,被很多公司运用来防止恶意注册和评论。tornado添加recaptchaHA非常容易2014-02-02 今天教各位小伙伴怎么用Python处理excel,文中有非常详细的代码示例及相关知识总结,对正在学习python的小伙伴们很有帮助,需要的朋友可以参考下2021-05-05
今天教各位小伙伴怎么用Python处理excel,文中有非常详细的代码示例及相关知识总结,对正在学习python的小伙伴们很有帮助,需要的朋友可以参考下2021-05-05 今天小编就为大家分享一篇python 字符串和整数的转换方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06
今天小编就为大家分享一篇python 字符串和整数的转换方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06 本文详细介绍了Pandas库中read_json和to_json方法,涵盖了参数解读、实际应用、嵌套JSON处理、时间序列数据、缺失值处理、性能优化以及使用Dask处理大型数据集等内容助你高效处理JSON数据,需要的朋友可以参考下2025-11-11
本文详细介绍了Pandas库中read_json和to_json方法,涵盖了参数解读、实际应用、嵌套JSON处理、时间序列数据、缺失值处理、性能优化以及使用Dask处理大型数据集等内容助你高效处理JSON数据,需要的朋友可以参考下2025-11-11










最新评论