
Selenium定位元素的方法小结及语法详解
更新时间:2025年02月18日 09:49:15 作者:静静在思考
Selenium是一种用于自动化网页操作的工具,通过不同定位策略可以精准定位网页元素,本文介绍了8种定位方法,并详细说明了每种方法的语法、使用场景及实际操作中的注意事项,需要的朋友可以参考下
以下是以百度网站为例,详细介绍 Selenium 中各种定位元素方法的语法及使用场景:
1. 通过 ID 定位
- 语法:使用
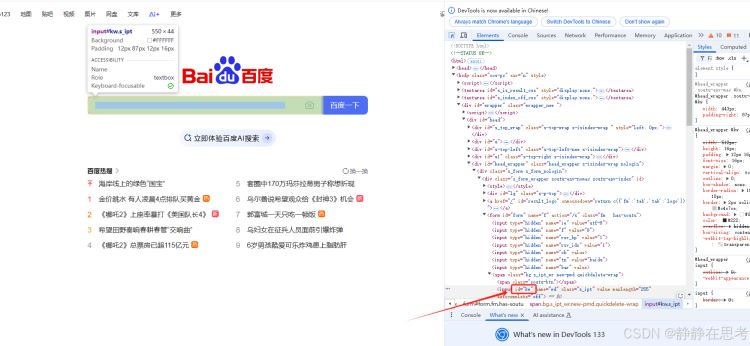
By.ID定位策略,在 Python 代码里通过find_element(By.ID, 'element_id')来定位元素,其中element_id是网页元素的id属性值。 - 使用场景:适用于元素具有唯一
id属性的情况,定位准确且速度快。在百度搜索页面,搜索框的id通常是kw,可以使用该方法定位搜索框。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
search_box = driver.find_element(By.ID, 'kw')
2. 通过 Name 定位
- 语法:运用
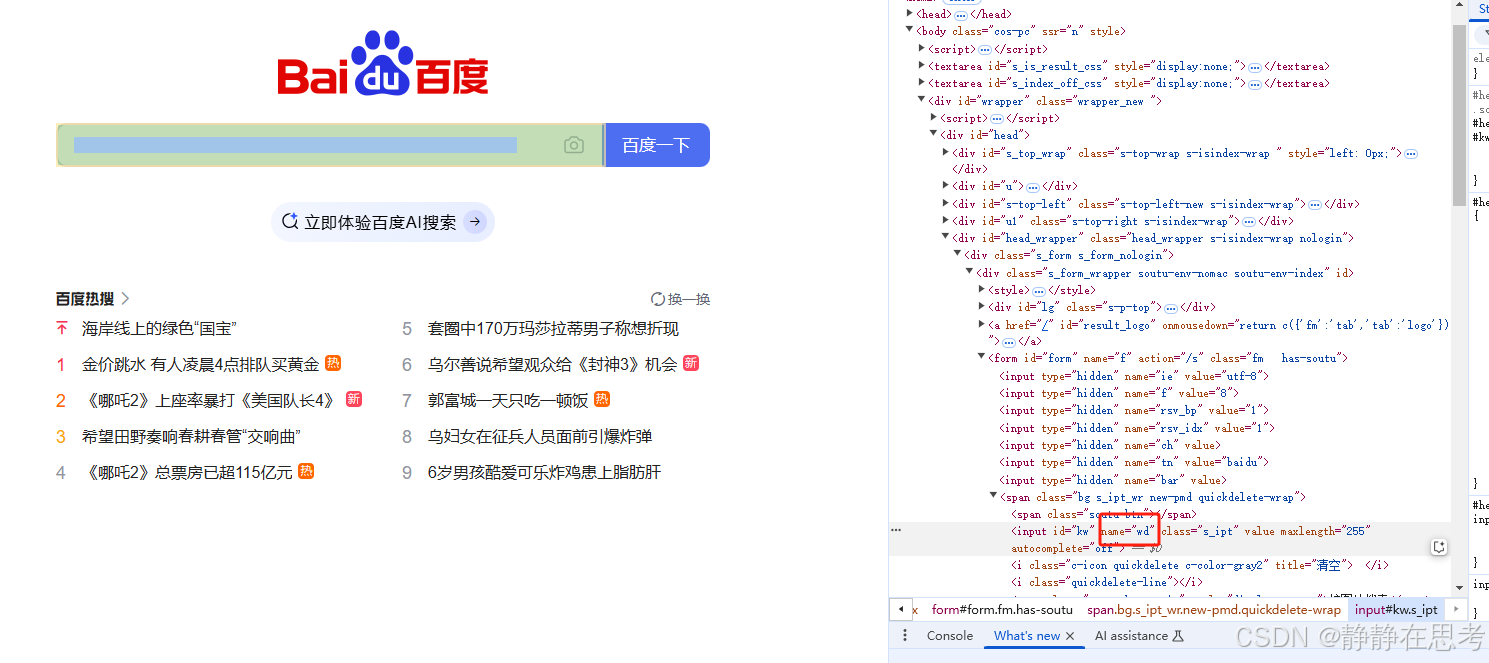
By.NAME定位策略,代码为find_element(By.NAME, 'element_name'),element_name是元素的name属性值。 - 使用场景:常用于表单元素,在百度搜索场景中,如果搜索框有
name属性,就可以用这种方式定位。不过百度搜索框name也是wd,与功能相关,方便表单提交数据。
driver.get('https://www.baidu.com')
search_box = driver.find_element(By.NAME, 'wd')
3. 通过 Class Name 定位
- 语法:采用
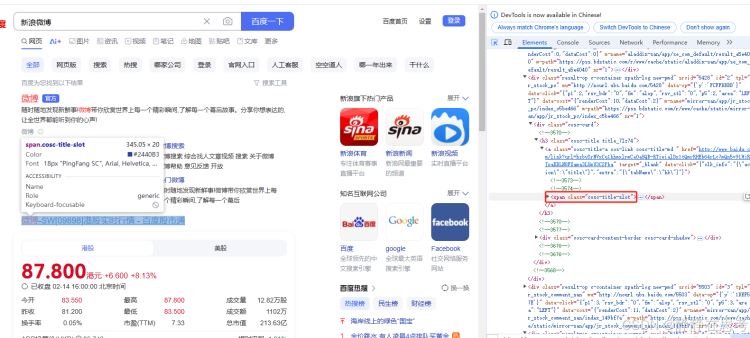
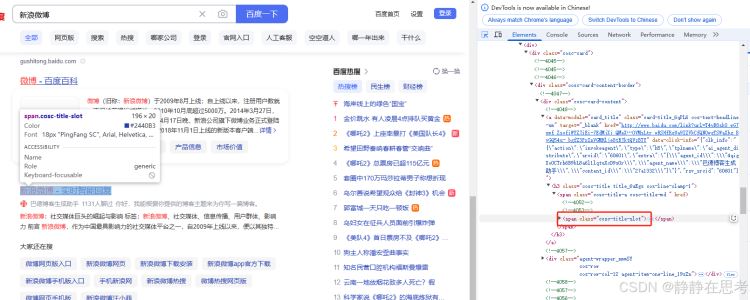
By.CLASS_NAME定位策略,代码是find_element(By.CLASS_NAME, 'element_class'),element_class是元素的class属性值。 - 使用场景:当需要定位一组具有相同样式或功能的元素时使用。在百度搜索结果页面,每个搜索结果的标题可能有相同的
class名,可借此定位所有标题元素。
driver.get('https://www.baidu.com/s?wd=python')
result_titles = driver.find_elements(By.CLASS_NAME, 'cosc-title-slot')
# 这里'cosc-title-slot' 需要替换为实际的 class 名
4. 通过 Tag Name 定位
- 语法:使用
By.TAG_NAME定位策略,代码为find_element(By.TAG_NAME, 'tag_name'),tag_name是 HTML 标签名,像div、input、a等。 - 使用场景:可快速定位某一类标签元素,但通常会结合其他定位方法。例如在百度页面获取所有的链接元素(
<a>标签)。
driver.get('https://www.baidu.com')
links = driver.find_elements(By.TAG_NAME, 'a')
5. 通过 Link Text 定位
- 语法:使用
By.LINK_TEXT定位策略,代码是find_element(By.LINK_TEXT, 'link_text'),link_text是<a>标签的完整文本内容。 - 使用场景:专门用于定位链接元素,当知道链接的完整文本内容时使用。比如百度页面上可能有“新闻”链接。
driver.get('https://www.baidu.com')
news_link = driver.find_element(By.LINK_TEXT, '新闻')

6. 通过 Partial Link Text 定位
- 语法:使用
By.PARTIAL_LINK_TEXT定位策略,代码为find_element(By.PARTIAL_LINK_TEXT, 'partial_link_text'),partial_link_text是<a>标签文本内容的一部分。 - 使用场景:当链接文本较长,只记得部分内容时适用。假设百度页面有个链接文本是“百度学术 - 权威学术资源平台”,只记得“百度学术”。
driver.get('https://www.baidu.com')
academic_link = driver.find_element(By.PARTIAL_LINK_TEXT, '百度学术')
7. 通过 CSS Selector 定位
- 语法:使用
By.CSS_SELECTOR定位策略,代码是find_element(By.CSS_SELECTOR, 'css_selector'),css_selector是符合 CSS 选择器语法的表达式。 - 使用场景:CSS 选择器很灵活,可结合元素的标签名、类名、
id、属性等进行定位。比如定位百度搜索按钮,它可能有特定的class和type属性。
driver.get('https://www.baidu.com')
search_button = driver.find_element(By.CSS_SELECTOR, 'input.some-class[type="submit"]')
# 这里'some-class' 需要替换为实际的 class 名
8. 通过 XPath 定位
- 语法:使用
By.XPATH定位策略,代码为find_element(By.XPATH, 'xpath_expression'),xpath_expression是符合 XPath 语法的表达式。 - 使用场景:XPath 是最强大的定位方式,能根据元素的属性、层级关系、文本内容等进行定位,适用于复杂的定位需求。例如定位百度搜索结果中第一个标题元素。
driver.get('https://www.baidu.com/s?wd=python')
first_result_title = driver.find_element(By.XPATH, '//*[@id="1"]/div/div[1]/div[1]/h3/a[1]/em')
# 这里的 XPath 要根据实际页面结构调整
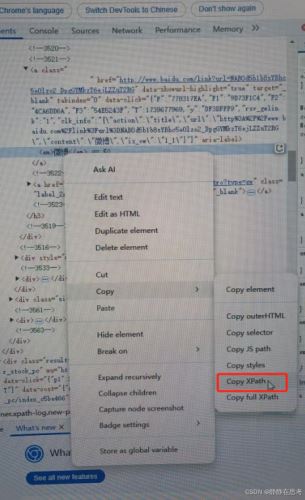
在实际操作中,要根据百度页面元素的特点和定位的准确性、便捷性来选择合适的定位方法。百度页面结构可能会更新,实际定位时要以最新页面为准。
以上就是Selenium定位元素的方法小结及语法详解的详细内容,更多关于Selenium定位元素的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要为大家介绍了Python Pyecharts绘制桑基图分析用户行为路径,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了Python Pyecharts绘制桑基图分析用户行为路径,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 在本篇文章里小编给大家分享了关于python+webdriver自动化环境搭建的详细步骤以及注意点,需要的朋友们参考下。2019-06-06
在本篇文章里小编给大家分享了关于python+webdriver自动化环境搭建的详细步骤以及注意点,需要的朋友们参考下。2019-06-06
pandas DataFrame 警告(SettingWithCopyWarning)的解决
这篇文章主要介绍了pandas DataFrame 警告(SettingWithCopyWarning)的解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
如何在 ASP.NET Core 中创建 gRPC 客户端和服务器
gRPC 是一种高性能、开源的远程过程调用(RPC)框架,它基于 Protocol Buffers(protobuf)定义服务,并使用 HTTP/2 协议进行通信,这篇文章主要介绍了在 ASP.NET Core 中创建 gRPC 客户端和服务器,需要的朋友可以参考下2024-11-11
macOS M1(Apple Silicon)安装配置Conda环境的具体实现
由于常用的Anaconda和Miniconda现在都没有提供M1处理器支持的conda环境,以下是conda-forge提供的miniforge,感兴趣的可以了解一下2021-08-08 paramiko 是一个用于在Python中执行远程操作的模块,支持SSH协议,它可以用于连接到远程服务器,执行命令、上传和下载文件,以及在远程服务器上执行各种操作,这篇文章主要介绍了python的paramiko模块基本用法,需要的朋友可以参考下2023-08-08
paramiko 是一个用于在Python中执行远程操作的模块,支持SSH协议,它可以用于连接到远程服务器,执行命令、上传和下载文件,以及在远程服务器上执行各种操作,这篇文章主要介绍了python的paramiko模块基本用法,需要的朋友可以参考下2023-08-08 在本篇内容里小编给大家分享的是关于python如何判断模块是否安装的技术文章,有兴趣的朋友们可以参考下。2020-06-06
在本篇内容里小编给大家分享的是关于python如何判断模块是否安装的技术文章,有兴趣的朋友们可以参考下。2020-06-06 在实际工作中,我们经常会遇到需要修改已打包的Python EXE程序的情况,可能是界面文字需要调整,也可能是功能需要微调,本文将系统介绍如何对PyInstaller打包的EXE程序进行反编译、修改和重新打包,帮助你掌握这一实用技能,需要的朋友可以参考下2026-05-05
在实际工作中,我们经常会遇到需要修改已打包的Python EXE程序的情况,可能是界面文字需要调整,也可能是功能需要微调,本文将系统介绍如何对PyInstaller打包的EXE程序进行反编译、修改和重新打包,帮助你掌握这一实用技能,需要的朋友可以参考下2026-05-05 这篇文章主要介绍了Python测试网络连通性,结合实例形式分析了Python通过发送ping请求测试网络连通性相关操作技巧,需要的朋友可以参考下2018-08-08
这篇文章主要介绍了Python测试网络连通性,结合实例形式分析了Python通过发送ping请求测试网络连通性相关操作技巧,需要的朋友可以参考下2018-08-08 这篇文章主要介绍了Python 如何定位特定类型文件,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-08-08
这篇文章主要介绍了Python 如何定位特定类型文件,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-08-08










最新评论