
使用Python从PDF中提取图片和图片信息(坐标、宽度和高度等)
引言
PDF文件作为一种广泛使用的电子文档格式,不仅包含文字信息,还可能包含各种图片、图表等视觉元素。在某些场景下,我们可能需要从PDF文件中提取这些图片,用于其他用途,比如插入到演示文稿中,或者进行进一步的编辑和处理。手动从PDF中提取图片是一项耗时的工作,尤其是当需要处理大量PDF文档时。而使用Python自动化这一过程,可以大幅节省时间和精力。这篇博客将探讨如何使用Python从PDF中提取图片以及图片的相关信息如坐标、宽度和高度等。
使用工具
本文使用的是Spire.PDF for Python库来实现从PDF中提取图片和图片信息。
你可以通过在终端运行以下命令来从PyPI安装Spire.PDF for Python:
pip install Spire.PDF
Python从PDF的特定页面中提取图片
要从PDF的特定页面中提取图片,首先需要使用PdfDocument.Pages[page_index]属性访问目标页面。之后,使用PdfImageHelper.GetImagesInfo(page) 方法获取该页面上的图片信息。最后使用PdfImageInfo.Image.Save() 方法将每个图片保存为独立的图片文件。具体步骤如下:
- 创建 PdfDocument 类的实例并使用 PdfDocument.LoadFromFile() 方法加载 PDF 文档。
- 使用PdfDocument.Pages[page_index]属性访问目标页面,这里的page_index表示页面的索引,从0开始计数。
- 创建 PdfImageHelper 实例。
- 使用 PdfImageHelper.GetImagesInfo(page) 方法获取目标页面中的图片信息。
- 循环遍历获取结果,使用 PdfImageInfo.Image.Save() 方法将每张图片保存为独立的图片文件。
from spire.pdf.common import *
from spire.pdf import *
import os
def extract_images_from_pdf_page(pdf_path, page_index, output_dir):
"""
从 PDF 文件的指定页面中提取图片,并将其保存到指定的输出目录中。
参数:
pdf_path (str): PDF 文件的路径。
page_index (int): 要提取图片的页面的索引值。
output_dir (str): 输出图片文件的目录。
"""
# 创建 PdfDocument 实例并加载 PDF 文件
doc = PdfDocument()
doc.LoadFromFile(pdf_path)
# 获取需要提取图片的目标页面
page = doc.Pages[page_index]
# 创建 PdfImageHelper 实例
image_helper = PdfImageHelper()
# 获取目标页面的图片信息
image_infos = image_helper.GetImagesInfo(page)
image_count = 1
# 提取并保存图片
for image_index in range(len(image_infos)):
# 指定输出文件名
output_file = os.path.join(output_dir, f"Image-{image_count}.png")
# 将图片保存为图片文件
image_infos[image_index].Image.Save(output_file)
image_count += 1
doc.Close()
# 使用示例
extract_images_from_pdf_page("示例.pdf", 1, "C:/Users/Administrator/Desktop/图片")Python从PDF文档中提取图片
要从整个PDF文档中提取图片,只需要循环遍历文档中的页面,然后重复上面的步骤,从每个页面上提取图片信息,最后将图片保存为独立的图片文件即可。具体步骤如下:
- 创建 PdfDocument 实例并使用 PdfDocument.LoadFromFile() 方法加载 PDF 文档。
- 创建 PdfImageHelper 实例。
- 循环遍历文档中的页面。
- 使用 PdfImageHelper.GetImagesInfo(page) 方法获取每个页面中的图片信息。
- 遍历获取结果,使用 PdfImageInfo.Image.Save() 方法将每张图片保存为图片文件。
from spire.pdf.common import *
from spire.pdf import *
def extract_images_from_pdf(pdf_path, output_dir):
"""
从 PDF 文件中提取所有图片,并将其保存到指定的输出目录中。
参数:
pdf_path (str): 输入 PDF 文件的路径。
output_dir (str): 输出图片文件的目录。
"""
# 创建 PdfDocument 实例并加载 PDF 文件
doc = PdfDocument()
doc.LoadFromFile(pdf_path)
# 创建 PdfImageHelper 实例
image_helper = PdfImageHelper()
image_count = 1
# 循环遍历每个页面
for page_index in range(doc.Pages.Count):
page = doc.Pages[page_index]
# 获取页面的图片信息
image_infos = image_helper.GetImagesInfo(page)
# 提取并保存图片
for image_index in range(len(image_infos)):
# 指定输出文件名
output_file = os.path.join(output_dir, f"Image-{image_count}.png")
# 将图片保存为图片文件
image_infos[image_index].Image.Save(output_file)
image_count += 1
doc.Close()
# 使用示例
extract_images_from_pdf("示例.pdf", "C:/Users/Administrator/Desktop/图片")Python从PDF中提取图片的坐标、宽度和高度等信息
要提取 PDF 文件中图片的信息,例如位置(X和Y坐标)、宽度和高度,可以使用 PdfImageInfo.Bounds.X、PdfImageInfo.Bounds.Y、PdfImageInfo.Bounds.Width 和 PdfImageInfo.Bounds.Height 属性。具体步骤如下:
- 创建 PdfDocument 实例并使用 PdfDocument.LoadFromFile() 方法加载 PDF 文档。
- 创建 PdfImageHelper 实例。
- 循环遍历文档中的页面。
- 使用 PdfImageHelper.GetImagesInfo(page) 方法获取每个页面中的图片信息。
- 遍历获取结果,使用 PdfImageInfo.Bounds.X、PdfImageInfo.Bounds.Y、PdfImageInfo.Bounds.Width 和 PdfImageInfo.Bounds.Height 属性获取图片的坐标、宽度和高度。
from spire.pdf.common import *
from spire.pdf import *
def print_pdf_image_info(pdf_path):
"""
打印 PDF 文件中图片的坐标、宽度和高度。
参数:
pdf_path (str): 输入 PDF 文件的路径。
"""
# 创建 PdfDocument 实例并加载 PDF 文件
doc = PdfDocument()
doc.LoadFromFile(pdf_path)
# 创建 PdfImageHelper 实例
image_helper = PdfImageHelper()
# 循环遍历每个页面
for page_index in range(doc.Pages.Count):
page = doc.Pages[page_index]
# 获取页面的图片信息
image_infos = image_helper.GetImagesInfo(page)
# 打印图片的坐标位置、宽度和高度
for image_index, image_info in enumerate(image_infos):
print(f"第 {page_index + 1} 页, 第 {image_index + 1} 个图片:")
print(f" 图片位置: ({image_info.Bounds.X}, {image_info.Bounds.Y})")
print(f" 图片大小: {image_info.Bounds.Width} x {image_info.Bounds.Height}")
doc.Close()
# 使用示例
print_pdf_image_info("示例.pdf")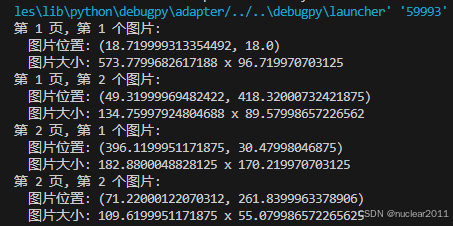
以上就是使用Python从PDF中提取图片和图片坐标、宽度和高度等信息的全部内容。
到此这篇关于使用Python从PDF中提取图片和图片信息(坐标、宽度和高度等)的文章就介绍到这了,更多相关Python PDF提取图片信息内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python错误调试及单元文档测试过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python错误调试及单元文档测试过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12 本文通过图文并茂的形式给大家介绍了win10环境下python3.5安装步骤,需要的朋友可以参考下2017-02-02
本文通过图文并茂的形式给大家介绍了win10环境下python3.5安装步骤,需要的朋友可以参考下2017-02-02 这篇文章主要介绍了Python反射和内置方法重写,结合实例形式较为详细的分析了Python反射概念、原理及内置方法重写相关操作技巧与注意事项,需要的朋友可以参考下2018-08-08
这篇文章主要介绍了Python反射和内置方法重写,结合实例形式较为详细的分析了Python反射概念、原理及内置方法重写相关操作技巧与注意事项,需要的朋友可以参考下2018-08-08
Python图像处理库scikit-image的使用方法详解
在计算机视觉与图像分析领域,Python已成为事实上的标准语言,scikit-image是SciPy生态的一部分,构建在NumPy、SciPy、matplotlib基础之上,旨在为科学计算和机器学习中的图像处理提供高质量、纯Python实现的算法,本文将从入门到实战,深入讲解scikit-image的方方面面2025-11-11
Python使用Selenium时遇到网页<body>划不动的问题解决方法
如果在使用 Selenium 时遇到网页的 <body> 划不动的问题,这通常是因为页面的滚动机制(例如,可能使用了一个具有固定高度的容器或自定义的滚动条)导致无法通过简单的 JavaScript 实现滚动,可以通过以下方法来解决该问题2024-10-10 这篇文章主要介绍了Python xlrd读取excel日期类型的2种方法,本文同时讲解了xlrd读取excel某个单元格的方法,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python xlrd读取excel日期类型的2种方法,本文同时讲解了xlrd读取excel某个单元格的方法,需要的朋友可以参考下2015-04-04
Python实现可视化Excel导入MySQL工具的完整代码
这篇文章主要为大家详细介绍了如何使用Python开发一个可视化桌面工具,无需命令行操作,点点鼠标就能实现Excel文件一键导入MySQL,感兴趣的小伙伴可以了解下2026-02-02 这篇文章主要介绍了Python函数的参数列表,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-12-12
这篇文章主要介绍了Python函数的参数列表,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-12-12
使用grappelli为django admin后台添加模板
本文介绍了一款非常流行的Django模板系统--grappelli,以及如何给Django的admin后台添加模板,非常的实用,这里推荐给大家。2014-11-11 这篇文章主要介绍了详解numpy的argmax的具体使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-05-05
这篇文章主要介绍了详解numpy的argmax的具体使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-05-05










最新评论