
Python使用TextRank算法实现文献关键信息提取
更新时间:2025年03月12日 10:56:56 作者:Atlas Shepherd
TextRank算法是一种基于图的排序算法,主要用于文本处理中的关键词提取和文本摘要,下面我们就来看看如何使用TextRank算法实现文献关键信息提取吧
算法介绍
TextRank算法是一种基于图的排序算法,主要用于文本处理中的关键词提取和文本摘要。它由PageRank算法改进而来,PageRank算法是谷歌用于网页重要性排序的算法。TextRank算法通过构建文本的图模型,利用句子之间的相似度作为边的权重,通过迭代计算句子的TextRank值,最后抽取排名高的句子组合成文本摘要。
实现思路
我们基于python代码,使用PyQt5创建图形用户界面(GUI),同时支持中英文两种语言的文本论文文献关键信息提取。
PyQt5:用于创建GUI应用程序。
jieba:中文分词库,用于中文文本的处理。
re:正则表达式模块,用于文本清理和句子分割。
numpy:提供数值计算能力,如数组操作、矩阵运算等,主要用于TextRank算法的实现。
完整代码
import sys
import re
import jieba
import numpy as np
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout,
QHBoxLayout, QTextEdit, QPushButton, QLabel,
QMessageBox, QSpinBox, QFileDialog, QComboBox)
from PyQt5.QtCore import Qt
class TextRankSummarizer:
def __init__(self, language='chinese'):
self.language = language
self.stopwords = self.load_stopwords()
# 初始化jieba中文分词器
if language == 'chinese':
jieba.initialize()
def load_stopwords(self):
"""内置停用词表"""
if self.language == 'chinese':
return {'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '也', '要'}
else: # 英文停用词
return {'a', 'an', 'the', 'and', 'or', 'but', 'if', 'is', 'are', 'of', 'to', 'in', 'on'}
def preprocess_text(self, text):
"""文本预处理"""
# 清洗特殊字符
text = re.sub(r'[^\w\s。,.?!]', '', text)
# 分句处理
if self.language == 'chinese':
sentences = re.split(r'[。!?]', text)
else:
sentences = re.split(r'[.!?]', text)
return [s.strip() for s in sentences if len(s) > 2]
def calculate_similarity(self, sentence, other_sentence):
"""计算句子相似度"""
words1 = [w for w in (jieba.cut(sentence) if self.language == 'chinese' else sentence.lower().split())
if w not in self.stopwords]
words2 = [w for w in
(jieba.cut(other_sentence) if self.language == 'chinese' else other_sentence.lower().split())
if w not in self.stopwords]
# 使用Jaccard相似度
intersection = len(set(words1) & set(words2))
union = len(set(words1) | set(words2))
return intersection / union if union != 0 else 0
def textrank(self, sentences, top_n=5, damping_factor=0.85, max_iter=100):
"""TextRank算法实现"""
similarity_matrix = np.zeros((len(sentences), len(sentences)))
# 构建相似度矩阵
for i in range(len(sentences)):
for j in range(len(sentences)):
if i != j:
similarity_matrix[i][j] = self.calculate_similarity(sentences[i], sentences[j])
# 归一化矩阵
row_sum = similarity_matrix.sum(axis=1)
normalized_matrix = similarity_matrix / row_sum[:, np.newaxis]
# 初始化得分
scores = np.ones(len(sentences))
# 迭代计算
for _ in range(max_iter):
prev_scores = np.copy(scores)
for i in range(len(sentences)):
scores[i] = (1 - damping_factor) + damping_factor * np.sum(normalized_matrix[i, :] * prev_scores)
if np.linalg.norm(scores - prev_scores) < 1e-5:
break
# 获取重要句子索引
ranked_indices = np.argsort(scores)[::-1][:top_n]
return sorted(ranked_indices)
def summarize(self, text, ratio=0.2):
"""生成摘要"""
sentences = self.preprocess_text(text)
if len(sentences) < 3:
return "文本过短,无法生成有效摘要"
top_n = max(1, int(len(sentences) * ratio))
important_indices = self.textrank(sentences, top_n=top_n)
# 按原文顺序排列
selected_sentences = [sentences[i] for i in sorted(important_indices)]
# 中文使用句号连接,英文使用.连接
separator = '。' if self.language == 'chinese' else '. '
return separator.join(selected_sentences) + ('。' if self.language == 'chinese' else '.')
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
# 初始化摘要器
self.summarizer = TextRankSummarizer()
# 界面设置
self.setup_ui()
def setup_ui(self):
self.setWindowTitle("TextRank文本摘要工具")
self.setGeometry(100, 100, 1000, 800)
main_widget = QWidget()
layout = QVBoxLayout()
# 输入区
self.input_text = QTextEdit()
self.input_text.setPlaceholderText("在此粘贴需要摘要的文本(建议500字以上)...")
# 控制区
control_layout = QHBoxLayout()
self.ratio_spin = QSpinBox()
self.ratio_spin.setRange(5, 50)
self.ratio_spin.setValue(20)
self.ratio_spin.setSuffix("%")
self.lang_combo = QComboBox()
self.lang_combo.addItems(["中文", "英文"])
self.summarize_btn = QPushButton("生成摘要")
self.import_btn = QPushButton("导入文件")
self.clear_btn = QPushButton("清空")
control_layout.addWidget(QLabel("摘要比例:"))
control_layout.addWidget(self.ratio_spin)
control_layout.addWidget(QLabel("语言:"))
control_layout.addWidget(self.lang_combo)
control_layout.addWidget(self.import_btn)
control_layout.addWidget(self.summarize_btn)
control_layout.addWidget(self.clear_btn)
# 输出区
self.output_text = QTextEdit()
self.output_text.setReadOnly(True)
# 布局组合
layout.addWidget(QLabel("输入文本:"))
layout.addWidget(self.input_text)
layout.addLayout(control_layout)
layout.addWidget(QLabel("摘要结果:"))
layout.addWidget(self.output_text)
main_widget.setLayout(layout)
self.setCentralWidget(main_widget)
# 信号连接
self.summarize_btn.clicked.connect(self.generate_summary)
self.import_btn.clicked.connect(self.import_file)
self.clear_btn.clicked.connect(self.clear_content)
self.lang_combo.currentTextChanged.connect(self.change_language)
def change_language(self, lang):
self.summarizer = TextRankSummarizer('chinese' if lang == "中文" else 'english')
def generate_summary(self):
text = self.input_text.toPlainText().strip()
if not text:
QMessageBox.warning(self, "输入错误", "请输入需要摘要的文本")
return
ratio = self.ratio_spin.value() / 100
summary = self.summarizer.summarize(text, ratio)
self.output_text.setPlainText(summary)
def import_file(self):
path, _ = QFileDialog.getOpenFileName(
self, "打开文本文件", "",
"文本文件 (*.txt);;所有文件 (*.*)"
)
if path:
try:
with open(path, 'r', encoding='utf-8') as f:
self.input_text.setPlainText(f.read())
except Exception as e:
QMessageBox.critical(self, "错误", f"文件读取失败:\n{str(e)}")
def clear_content(self):
self.input_text.clear()
self.output_text.clear()
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())效果图
最后效果如下
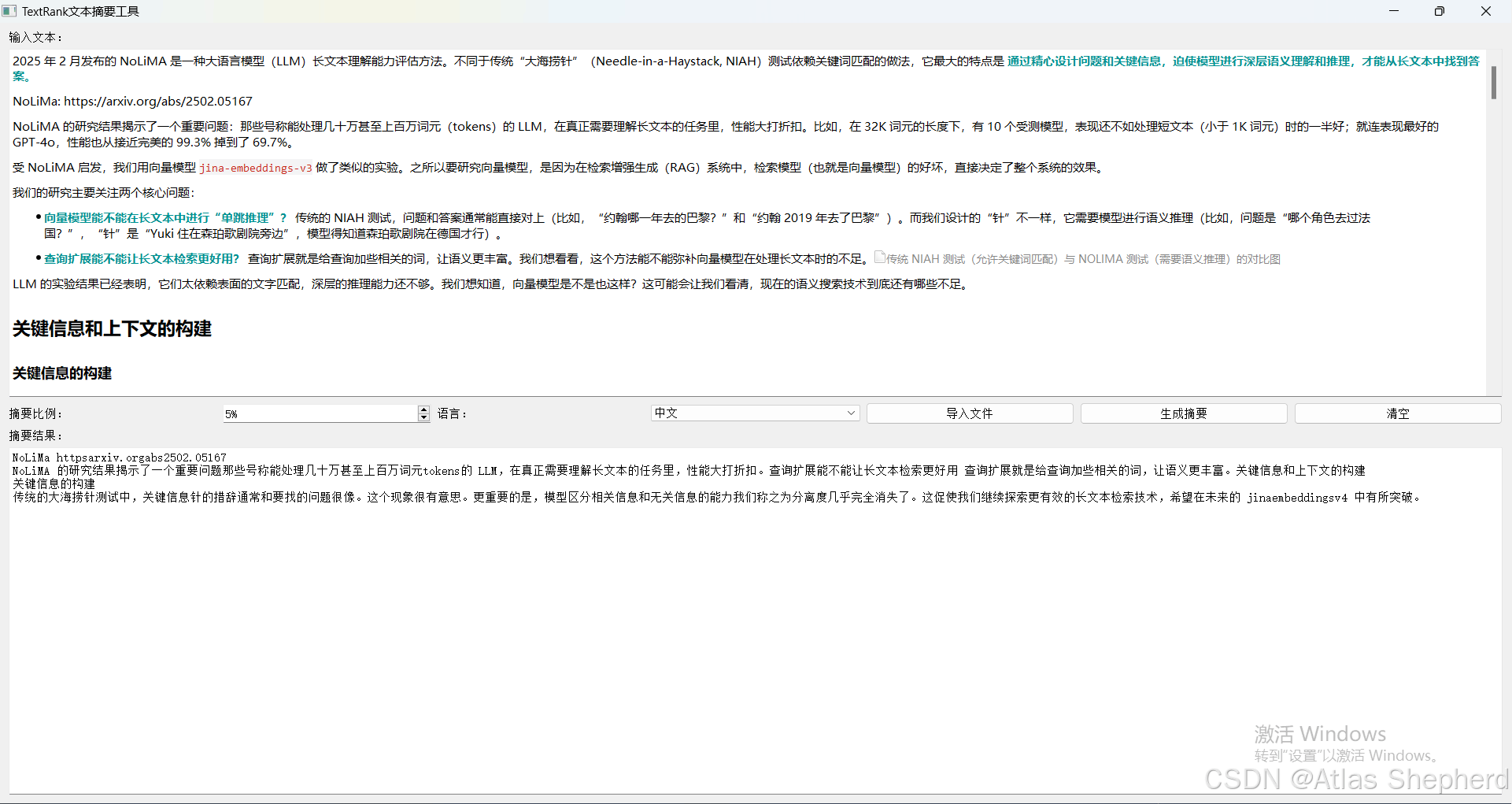
到此这篇关于Python使用TextRank算法实现文献关键信息提取的文章就介绍到这了,更多相关Python TextRank关键信息提取内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 Pillow 是一个 Python 的图像处理库,它是 Python Imaging Library (PIL) 的一个分支,并且增加了更多的功能,下面我们看看如何利用它实现批量在图片上写上自定义的文本吧2024-11-11
Pillow 是一个 Python 的图像处理库,它是 Python Imaging Library (PIL) 的一个分支,并且增加了更多的功能,下面我们看看如何利用它实现批量在图片上写上自定义的文本吧2024-11-11 这篇文章主要介绍了通过实例了解python property属性,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了通过实例了解python property属性,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11 这篇文章主要介绍了Windows下Anaconda安装、换源与更新的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04
这篇文章主要介绍了Windows下Anaconda安装、换源与更新的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04 本文向大家详细介绍了Python装饰器的函数式编程的相关资料,需要的朋友可以参考下2015-02-02
本文向大家详细介绍了Python装饰器的函数式编程的相关资料,需要的朋友可以参考下2015-02-02
python中tqdm使用,对于for和while下的两种不同情况问题
这篇文章主要介绍了python中tqdm使用,对于for和while下的两种不同情况问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 线程(Thread)是操作系统能够进行运算调度的最小单位;线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源2022-12-12
线程(Thread)是操作系统能够进行运算调度的最小单位;线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源2022-12-12 这篇文章主要介绍了python中class的定义及使用,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了python中class的定义及使用,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-09-09
Python时间模块datetime、time、calendar的使用方法
这篇文章主要介绍了Python时间模块的使用方法,主要包括三大模块datetime、time、calendar,感兴趣的小伙伴们可以参考一下2016-01-01 在本篇文章里小编给大家整理的是一篇关于Django视图类型的总结内容,有兴趣的朋友们可以学习下。2021-02-02
在本篇文章里小编给大家整理的是一篇关于Django视图类型的总结内容,有兴趣的朋友们可以学习下。2021-02-02 Python 的 pandas 库提供了便捷的 read_excel() 方法,但在实际使用中,我们可能会遇到各种问题,本文将分析这些常见错误,并提供 Python 和 Java 的解决方案,有需要的可以参考下2025-04-04
Python 的 pandas 库提供了便捷的 read_excel() 方法,但在实际使用中,我们可能会遇到各种问题,本文将分析这些常见错误,并提供 Python 和 Java 的解决方案,有需要的可以参考下2025-04-04










最新评论