
详解如何在Pandas中删除常量列
更新时间:2025年03月24日 08:42:58 作者:python收藏家
常数列不提供可变性,这意味着它们无助于区分不同的数据点,在许多机器学习模型中,这些列会引入冗余或不相关的数据,从而对性能产生负面影响,因此,通常必须删除常量列,所以本文我们将探索如何使用Python识别和删除Pandas DataFrame中的常量列,需要的朋友可以参考下
在数据分析中,经常会遇到数据集中始终具有常量值的列(即,该列中的所有行包含相同的值)。这样的常量列不提供有意义的信息,可以安全地删除而不影响分析。
如:
在本文中,我们将探索如何使用Python识别和删除Pandas DataFrame中的常量列。
为什么要删除常量列?
常数列不提供可变性,这意味着它们无助于区分不同的数据点。在许多机器学习模型中,这些列会引入冗余或不相关的数据,从而对性能产生负面影响。因此,通常必须删除常量列,以便:
- 减少数据集的维数。
- 提高计算效率。
- 增强模型的可解释性。
步骤1:在Pandas中识别常量列
Pandas提供了几种识别和删除常量列的方法。我们可以检查唯一值的数量正好为1的列。
.nunique()函数在这方面特别有用,因为它返回每列中不同元素的数量。
import pandas as pd
# Sample DataFrame with constant and non-constant columns
data = {
'A': [1, 1, 1, 1],
'B': [2, 3, 4, 5],
'C': ['X', 'X', 'X', 'X'],
'D': [10, 11, 12, 13]
}
df = pd.DataFrame(data)
# Identify constant columns
constant_columns = [col for col in df.columns if df[col].nunique() == 1]
# Display constant columns
print("Constant columns:", constant_columns)
输出
Constant columns: ['A', 'C']
在这种情况下,列A和列C被标识为常量,因为它们只有一个唯一值。
步骤2:删除常量列
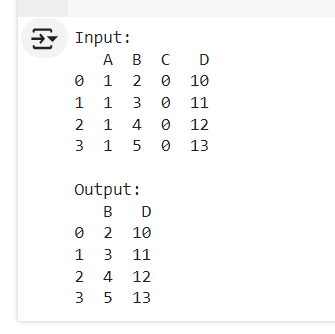
一旦我们确定了常量列,我们就可以使用Pandas中的.drop()函数轻松删除它们。
# Drop constant columns df_cleaned = df.drop(columns=constant_columns) # Display the cleaned DataFrame print(df_cleaned)
输出
B D 0 2 10 1 3 11 2 4 12 3 5 13
在这里,清理后的DataFrame已删除常量列A和C。
步骤3:删除较大数据集中的常量列
让我们考虑一个更大的数据集,其中某些列可能具有常量值。
import numpy as np
# Create a DataFrame with random and constant columns
data = {
'X1': np.random.randint(0, 100, size=100),
'X2': [5] * 100, # Constant column
'X3': np.random.randint(0, 100, size=100),
'X4': [3] * 100, # Constant column
}
df_large = pd.DataFrame(data)
# Remove constant columns in the larger dataset
constant_columns = [col for col in df_large.columns if df_large[col].nunique() == 1]
df_large_cleaned = df_large.drop(columns=constant_columns)
print("Original DataFrame Shape:", df_large.shape)
print(df_large.head())
print("Cleaned DataFrame Shape:", df_large_cleaned.shape)
print(df_large_cleaned.head())
输出

在本例中,删除了常量列X2和X4,在清理后的DataFrame中只留下X1和X3。
处理特殊情况
- 空DataFrame:如果DataFrame为空,则删除常量列无效,函数应返回原始DataFrame。
- 包含缺失值的列:如果所有非缺失值都相同,则包含缺失值(NA)的列仍可以被视为常数。您可以使用占位符(例如,fillna())之前确定常数列。
总结
从数据集中删除常量列是数据预处理的关键步骤,特别是在机器学习和数据分析中处理大型数据集时。在这篇文章中,我们有:
- 定义了常数列,并解释了它们在分析中缺乏意义。
- 展示了使用Pandas识别和删除常量列的多种方法。
- 提供了示例,包括在较大的数据集中删除常量列和处理特殊情况(如丢失数据)。
通过有效地删除这些冗余列,我们可以提高模型的性能并简化分析。
到此这篇关于详解如何在Pandas中删除常量列的文章就介绍到这了,更多相关Pandas删除常量列内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

PyTorch中OptionalCUDAGuard的使用小结
PyTorch的OptionalCUDAGuard通过RAII机制实现GPU设备上下文安全切换,支持可选设备参数,自动在作用域结束时恢复原设备状态,感兴趣的可以了解一下2025-06-06 本文精心整理了20个Python办公自动化的真实案例,涵盖了文件处理、数据分析、文档操作、邮件发送等多个方面,无论你是编程新手,还是希望提高办公效率的职场人士,都能从中找到灵感和实用的解决方案2025-11-11
本文精心整理了20个Python办公自动化的真实案例,涵盖了文件处理、数据分析、文档操作、邮件发送等多个方面,无论你是编程新手,还是希望提高办公效率的职场人士,都能从中找到灵感和实用的解决方案2025-11-11 这篇文章主要介绍了Python在软件开发中自动化测试和质量保障的重要性,以及如何使用Python的测试框架如unittest和pytest进行测试,它还讨论了编写高效的测试用例、持续集成和持续部署(CI/CD)、测试驱动开发(TDD)的实践以及性能测试和代码覆盖率分析等2025-01-01
这篇文章主要介绍了Python在软件开发中自动化测试和质量保障的重要性,以及如何使用Python的测试框架如unittest和pytest进行测试,它还讨论了编写高效的测试用例、持续集成和持续部署(CI/CD)、测试驱动开发(TDD)的实践以及性能测试和代码覆盖率分析等2025-01-01 这篇文章主要为大家介绍了图神经网络GNN算法基本原理详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了图神经网络GNN算法基本原理详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
在python项目的docker镜像里如何使用pdm管理依赖
在 DjangoStarter 项目中,我已经使用 pdm 作为默认的包管理器,不再直接使用 pip,所以部署的时候 dockerfile 和 docker-compose 配置需要修改一下,这篇文章主要介绍了在python项目的docker镜像里使用pdm管理依赖,需要的朋友可以参考下2024-08-08 这篇文章主要介绍了使用Requests库来进行爬虫的方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11
这篇文章主要介绍了使用Requests库来进行爬虫的方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11 这篇文章主要介绍了python字典和JSON格式的转换方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了python字典和JSON格式的转换方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05 这篇文章主要介绍了Django 迁移、操作数据库的相关知识,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了Django 迁移、操作数据库的相关知识,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08 pip 就是 Python 标准库(The Python Standard Library)中的一个包,只是这个包比较特殊,用它可以来管理 Python 标准库(The Python Standard Library)中其他的包。本文为大家介绍了pip安装第三方库的方法,需要的可以参考一下2022-11-11
pip 就是 Python 标准库(The Python Standard Library)中的一个包,只是这个包比较特殊,用它可以来管理 Python 标准库(The Python Standard Library)中其他的包。本文为大家介绍了pip安装第三方库的方法,需要的可以参考一下2022-11-11 Python的filter()函数用于筛选序列元素,返回迭代器,适合函数式编程,相比列表推导式,内存更优,尤其适用于大数据集,结合lambda或命名函数,能提升代码简洁性和可读性,本文探讨filter()函数的工作原理、使用场景、性能特点及与其他Python特性的对比,帮助全面掌握这一实用工具2025-08-08
Python的filter()函数用于筛选序列元素,返回迭代器,适合函数式编程,相比列表推导式,内存更优,尤其适用于大数据集,结合lambda或命名函数,能提升代码简洁性和可读性,本文探讨filter()函数的工作原理、使用场景、性能特点及与其他Python特性的对比,帮助全面掌握这一实用工具2025-08-08










最新评论