
Python如何提取Word文档中的超链接
前言
在数字化办公场景中,Word文档作为承载结构化信息的重要载体,常包含大量嵌入的超链接以关联外部资源或实现内容交互。这些链接可能隐含着关键参考数据、云端资源定位或动态更新的数据源接口,但人工逐条检索不仅效率低下且易出现遗漏。自动化提取技术不仅能快速建立链接索引,还能分析链接分布特征,支撑链接有效性验证、文档版本监控等场景,显著降低人工操作风险,确保信息管理的完整性与可追溯性。本文将介绍如何使用Python实现Word文档中超链接的批量提取,包括超链接锚文本、URL以及屏幕提示文本的提取。
本文所使用的方法需要用到免费的Free Spire.Doc for Python,PyPI:pip install spire.doc.free。
用Python提取Word文档中的所有超链接
我们可以使用库中的 Document 类来载入Word文档进行处理。由于Word文档中的超链接是以域(Field)的形式添加到段落文本中的,因此,我们可以通过判断文档各节子对象类型来找出所有段落,然后再判断段落子对象类型来找出所有域,最后判断域类型来找出所有超链接域。找出超链接域之后,我们可以使用 Field.FieldText 属性获取超链接的锚文本,以及 Field.Code 属性获取以下格式的域代码:
- 普通超链接域代码:HYPERLINK "https://www.example.com/"
- 带屏幕提示的超链接域代码:HYPERLINK "https://www.example.com/ai" \o "屏幕提示内容"
通过剪切域代码,我们可以获取超链接的地址的屏幕提示内容,从而提取完整的超链接信息。
以下是使用Python提取Word文档超链接的操作步骤:
所需模块:Document、Paragraph、Field、FieldType。
1.加载 Word 文档:创建 Document 对象并使用 Document.LoadFromFile() 方法加载目标文件。
2.遍历文档结构:
- 遍历所有节 Sections。
- 遍历每个节的主体子对象 Section.Body.ChildObjects。
- 筛选出段落 Paragraph 类型的子对象,再遍历段落中的对象 Paragraph.ChildObjects。
3.提取超链接:
- 识别 Field 类型的段落子对象,同时确定子对象的 FieldType 属性是否为 FieldType.FieldHyperlink。
- 解析 FieldText(锚文本)和 Field.Code(URL 及屏幕提示)。
4.保存提取的超链接信息。
代码示例
from spire.doc import Document, Paragraph, Field, FieldType
# 创建Document对象
doc = Document()
# 加载Word文件
doc.LoadFromFile("示例.docx")
# 创建字符串列表用于储存超链接信息
hyperlinks = []
# 遍历文档中的节
for i in range(doc.Sections.Count):
# 获取当前节
section = doc.Sections.get_Item(i)
# 遍历节中的主体子对象
for j in range(section.Body.ChildObjects.Count):
# 获取当前子对象
secObj = section.Body.ChildObjects.get_Item(j)
# 判断子对象是否为段落
if isinstance(secObj, Paragraph):
# 遍历段落中的子对象
for k in range(secObj.ChildObjects.Count):
# 获取当前子对象
paraObj = secObj.ChildObjects.get_Item(k)
# 判断子对象是否为域以及是否为超链接域
if isinstance(paraObj, Field) and paraObj.Type == FieldType.FieldHyperlink:
# 获取超链接的锚文本
anchorText = paraObj.FieldText
# 获取超链接的URL
url = paraObj.Code.split('"')[1]
# 判断是否存在屏幕提示
if "\\o" in paraObj.Code:
# 获取屏幕提示
hyperlinkTip = paraObj.Code.split('\"')[3].strip()
# 将锚文本、URL和屏幕提示组合到字符串中
hyperlinks.append(f"锚文本:{anchorText}\nURL:{url}\n屏幕提示:{hyperlinkTip}\n\n")
else:
# 将锚文本和URL组合到字符串中
hyperlinks.append(f"锚文本:{anchorText}\nURL:{url}\n\n")
# 将超链接信息写入文件
with open("output/提取的超链接.txt", "w", encoding="utf-8") as file:
for hyperlink in hyperlinks:
file.write(hyperlink)
# 关闭文档
doc.Close()
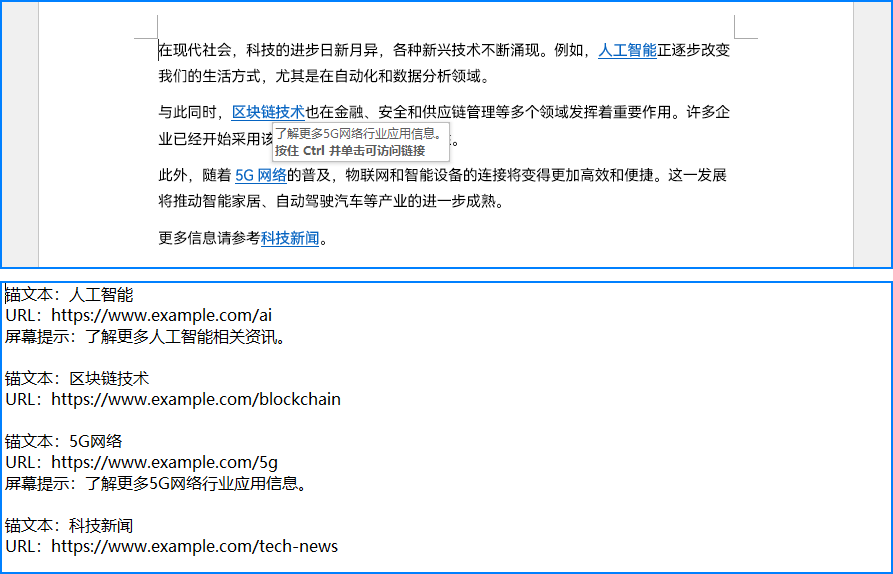
提取结果
方法补充
Python提取docx中的超链接
Python如何解析 <w:t></w:t>中间的内容
用 xml + 正则表达式如果仅仅使用 for paragraph in document.paragraphs 获取不包含表格的段落时,还应加上.text属性
import re
from docx import Document
def get_paragraph_from_docx(file_name):
"""
网址:https:blog.csdn.net,这是一段有hyperlink的段落
这是一段没有hyperlink的段落
可用于处理包含超链接的文本,但会自动跳过表格
:param file_name:
:return:
"""
text = []
document = Document(file_name)
for paragraph in document.paragraphs:
t_para = u""
# 有无超链接均可处理
xml_str = str(paragraph.paragraph_format.element.xml)
wt_list = re.findall('<w:t[\S\s]*?</w:t>', xml_str)
for wt in wt_list:
wt_content = re.sub('<[\S\s]*?>', u"", wt)
t_para += wt_content
if t_para:
t_para = t_para.strip()
t_para = re.sub('[\s]', '', t_para)
if t_para:
text.append(t_para)
return text
d = docx.Document(./test.docx)
for p in d.paragraphs:
xml = p.paragraph_format.element.xml
xml_str = str(xml)
wt_list = re.findall('<w:t[\S\s]*?</w:t>', xml_str)
hyperlink = u''
for wt in wt_list:
wt_content = re.sub('<[\S\s]*?>', u'', wt)
hyperlink += wt_content
print(hyperlink)
到此这篇关于Python如何提取Word文档中的超链接的文章就介绍到这了,更多相关Python提取Word超链接内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了解决TensorFlow训练模型及保存数量限制的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03
这篇文章主要介绍了解决TensorFlow训练模型及保存数量限制的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03
Python代码显得Pythonic(区别于其他语言的写法)
这篇文章主要介绍了Python代码显得Pythonic(区别于其他语言的写法),对于字符串连接,相比于简单的+,更pythonic的做法是尽量使用%操作符或者format函数格式化字符串,感兴趣的小伙伴和小编一起进入文章了解更详细相关知识内容吧2022-02-02 这篇文章主要介绍了Python中pip安装非PyPI官网第三方库的方法,pip最新的版本(1.5以上的版本), 出于安全的考 虑,pip不允许安装非PyPI的URL,本文就给出两种解决方法,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了Python中pip安装非PyPI官网第三方库的方法,pip最新的版本(1.5以上的版本), 出于安全的考 虑,pip不允许安装非PyPI的URL,本文就给出两种解决方法,需要的朋友可以参考下2015-06-06 这篇文章主要介绍了pyspark 随机森林的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04
这篇文章主要介绍了pyspark 随机森林的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-04-04 这篇文章主要介绍了Python简单计算文件MD5值的方法,涉及Python文件读取、hash运算及md5加密等相关操作技巧,需要的朋友可以参考下2018-04-04
这篇文章主要介绍了Python简单计算文件MD5值的方法,涉及Python文件读取、hash运算及md5加密等相关操作技巧,需要的朋友可以参考下2018-04-04
细数nn.BCELoss与nn.CrossEntropyLoss的区别
今天小编就为大家整理了一篇细数nn.BCELoss与nn.CrossEntropyLoss的区别,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 在数字图像处理领域,裁剪和分析图像的直方图是两个非常基本且重要的操作,本文将通过一个简单的Python项目,展示如何使用skimage和matplotlib库来裁剪图像并分析其RGB通道的直方图,感兴趣的小伙伴跟着小编一起来看看吧2025-01-01
在数字图像处理领域,裁剪和分析图像的直方图是两个非常基本且重要的操作,本文将通过一个简单的Python项目,展示如何使用skimage和matplotlib库来裁剪图像并分析其RGB通道的直方图,感兴趣的小伙伴跟着小编一起来看看吧2025-01-01
pytorch如何自定义forward和backward函数
PyTorch自动求导功能强大,但在特定情况下需要用户自行定义backward函数,通过实例解释了保存变量、计算梯度、链式法则等核心概念,并展示了如何通过自定义函数集成到网络中以及如何正确返回梯度,此外,还讨论了多输出情况下的梯度传递2024-10-10 这篇文章主要介绍了如何使用Python绘制散点图,包括导入包、准备数据、绘制图像、修饰图像(添加标题、坐标轴标签、颜色图例)以及整合所有代码,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-12-12
这篇文章主要介绍了如何使用Python绘制散点图,包括导入包、准备数据、绘制图像、修饰图像(添加标题、坐标轴标签、颜色图例)以及整合所有代码,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-12-12 这篇文章主要介绍了Python程序与服务器连接的WSGI接口,是Python网络编程学习当中的重要内容,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python程序与服务器连接的WSGI接口,是Python网络编程学习当中的重要内容,需要的朋友可以参考下2015-04-04










最新评论