
python SQLAlchemy 数据库连接池的实现
SQLALchemy 链接数据库使用数据库连接池技术,原理是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的链接,而是从链接池中取出一个已建立的空闲链接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而链接的建立,断开都由链接池来管理,同时,还可以通过设置链接池的参数来控制链接池中的初始链接数,链接的上下限数以及每个链接的最大使用次数,最大空闲时间等。
1. 安装
安装SQLAlchemy
pip install SQLAlchemy
安装mysql
pip install pymysql
2. 创建数据库引擎
示例:
from sqlalchemy import create_engine engine = create_engine(mysql_url, echo=True, pool_size=5, max_overflow=4, pool_recycle=7200, pool_timeout=30)
echo=True: 这表示在执行 SQL 查询时会输出所有 SQL 语句及其参数到控制台,方便调试。
pool_size=5: 这设置了数据库连接池的大小为 5,表示在连接池中最多可以保持 5 个连接。
max_overflow=4: 这允许在需要时,连接池外再创建最多 4 个额外的连接,超出连接池大小的部分会在使用后关闭。
pool_recycle=7200: 这表示连接在 7200 秒(2 小时)后会被回收,避免因长时间连接而导致的问题(例如,MySQL 的“互动超时”)。
pool_timeout=30: 这是连接池的超时时间,表示如果在 30 秒内没有获取到可用的连接,将会抛出异常。
3. 新建表,增删改查demo
配置文件:
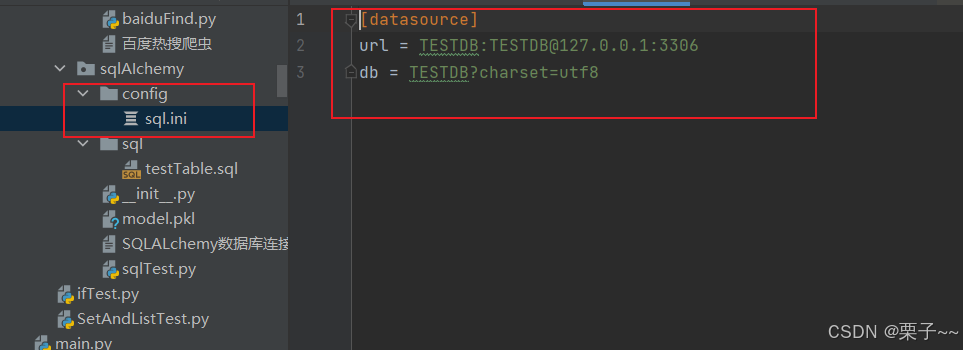
sql.ini:
[datasource] url = TESTDB:TESTDB@127.0.0.1:3306 db = TESTDB?charset=utf8
python demo:
from sqlalchemy import create_engine, Column, String, Integer, DateTime, Index, text
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
import pathlib
import configparser
# 设置配置文件
current_dir = pathlib.Path(__file__).parent
config_file = current_dir / 'config' / 'sql.ini'
config = configparser.ConfigParser()
with open(config_file, 'r', encoding='utf-8') as f:
config.read_file(f)
url = config['datasource']['url']
db = config['datasource']['db']
mysql_url = f'mysql+pymysql://{url}/{db}'
# 创建数据库引擎
"""
echo=True: 这表示在执行 SQL 查询时会输出所有 SQL 语句及其参数到控制台,方便调试。
pool_size=5: 这设置了数据库连接池的大小为 5,表示在连接池中最多可以保持 5 个连接。
max_overflow=4: 这允许在需要时,连接池外再创建最多 4 个额外的连接,超出连接池大小的部分会在使用后关闭。
pool_recycle=7200: 这表示连接在 7200 秒(2 小时)后会被回收,避免因长时间连接而导致的问题(例如,MySQL 的“互动超时”)。
pool_timeout=30: 这是连接池的超时时间,表示如果在 30 秒内没有获取到可用的连接,将会抛出异常。
"""
engine = create_engine(mysql_url, echo=True, pool_size=5, max_overflow=4, pool_recycle=7200, pool_timeout=30)
Base = declarative_base()
# 设置会话
Session = sessionmaker(bind=engine)
session = Session()
# 表结构
class YzyTest(Base):
__tablename__ = 't_yzy_test'
SEQUENCE_NO = Column(Integer, primary_key=True, autoincrement=True, comment='序列号')
PK_STD_POINT_AI_RELATION = Column(String(36), unique=True, nullable=False, comment='id')
FK_STD_AUDIT_POINT = Column(String(36), nullable=False, comment='审核标准id')
FK_AI_STD = Column(String(36), nullable=False, comment='aiId')
CHANNEL_TAG = Column(String(45), nullable=False, comment='渠道')
FK_USER_CREATE = Column(String(36), nullable=True, comment='创建人id')
USER_NAME_CREATE = Column(String(64), nullable=True, comment='创建人姓名')
CREATE_TIME = Column(DateTime, default=text('CURRENT_TIMESTAMP'), nullable=False, comment='创建时间')
__table_args__ = (
Index('u_t_yzy_test_01', 'FK_STD_AUDIT_POINT', 'FK_AI_STD', 'CHANNEL_TAG', unique=True),
)
# 创建表
def create_table():
Base.metadata.create_all(engine)
# 查询数据
def query():
return session.query(YzyTest).all()
# 插入数据
def save(param):
session.add(param)
session.commit()
# 更新数据
def update(param_id, updated_data):
param = session.query(YzyTest).filter(YzyTest.PK_STD_POINT_AI_RELATION == param_id).first()
if param:
for key, value in updated_data.items():
setattr(param, key, value)
session.commit()
# 删除数据
def delete(param_id):
param = session.query(YzyTest).filter(YzyTest.PK_STD_POINT_AI_RELATION == param_id).first()
if param:
session.delete(param)
session.commit()
if __name__ == '__main__':
create_table()
# 示例用法:
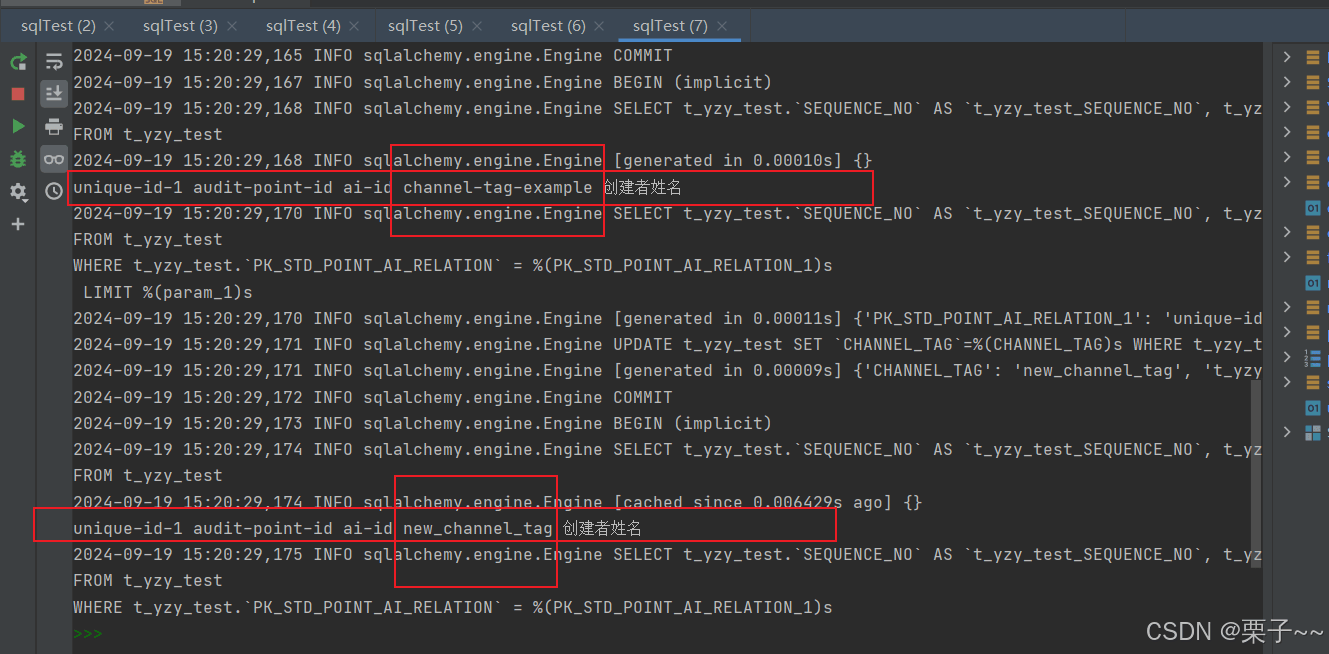
new_param = YzyTest(
PK_STD_POINT_AI_RELATION='unique-id-1',
FK_STD_AUDIT_POINT='audit-point-id',
FK_AI_STD='ai-id',
CHANNEL_TAG='channel-tag-example',
USER_NAME_CREATE='创建者姓名'
)
save(new_param)
params = query()
for param in params:
print(param.PK_STD_POINT_AI_RELATION, param.FK_STD_AUDIT_POINT, param.FK_AI_STD, param.CHANNEL_TAG, param.USER_NAME_CREATE)
update('unique-id-1', {'CHANNEL_TAG': 'new_channel_tag'})
params = query()
for param in params:
print(param.PK_STD_POINT_AI_RELATION, param.FK_STD_AUDIT_POINT, param.FK_AI_STD, param.CHANNEL_TAG, param.USER_NAME_CREATE)
delete('unique-id-1')
测试:

到此这篇关于python SQLAlchemy 数据库连接池的实现的文章就介绍到这了,更多相关python SQLAlchemy连接池内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 一谈到Web页面,可能大家首先想到就是HTML,CSS或JavaScript。 本次小F就给大家介绍一下如何用Python制作一个数据可视化网页,使用到的是Streamlit库。轻松的将一个Excel数据文件转换为一个Web页面,提供给所有人在线查看。2021-05-05
一谈到Web页面,可能大家首先想到就是HTML,CSS或JavaScript。 本次小F就给大家介绍一下如何用Python制作一个数据可视化网页,使用到的是Streamlit库。轻松的将一个Excel数据文件转换为一个Web页面,提供给所有人在线查看。2021-05-05
Python绘图工具使用Matplotlib、Seaborn和Pyecharts绘制散点图详解
这篇文章主要介绍了Python绘图工具使用Matplotlib、Seaborn和Pyecharts绘制散点图的相关资料,每种库都有其特点和适用场景,通过实际操作,学习如何使用这些库绘制散点图,并比较它们的优缺点,需要的朋友可以参考下2026-01-01
python列表插入append(), extend(), insert()用法详解
在本篇文章里小编给大家整理了关于python列表插入append(), extend(), insert()用法以及相关知识点,有需要的朋友们参考下。2019-09-09 Python 的强大之处在于它自带了丰富的工具箱,截至 Python 3.12 版本,官方提供了 71 个内置函数,这些函数无需 import 任何模块即可直接使用,为了方便查阅和记忆,本文将这 71 个函数按功能分类2026-01-01
Python 的强大之处在于它自带了丰富的工具箱,截至 Python 3.12 版本,官方提供了 71 个内置函数,这些函数无需 import 任何模块即可直接使用,为了方便查阅和记忆,本文将这 71 个函数按功能分类2026-01-01 这篇文章主要介绍了python数组和矩阵的用法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了python数组和矩阵的用法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
Python中pandas库sort_values()方法的使用
最后去看了有关于 sort_values 的文档,成功解决先把单词出现频次由高往低依次排序,再把频次相同的情况下的单词按照 MD5 值排序这个问题,下面通过本文讲解下Python中pandas库sort_values()方法的使用,感兴趣的朋友一起看看吧2023-07-07 这篇文章主要介绍了Python的time库的使用教程,文中有非常详细的代码示例,对正在学习python基础的小伙伴们有非常好的帮助,需要的朋友可以参考下2022-04-04
这篇文章主要介绍了Python的time库的使用教程,文中有非常详细的代码示例,对正在学习python基础的小伙伴们有非常好的帮助,需要的朋友可以参考下2022-04-04 这篇文章主要介绍了python简单文本处理的方法,涉及Python针对文本文件及字符串操作的相关技巧,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了python简单文本处理的方法,涉及Python针对文本文件及字符串操作的相关技巧,需要的朋友可以参考下2015-07-07 这篇文章主要介绍了python排序算法之归并排序,归并排序算法就是一个先把数列拆分为子数列,对子数列进行排序后,再把有序的子数列合并为完整的有序数列的算法,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了python排序算法之归并排序,归并排序算法就是一个先把数列拆分为子数列,对子数列进行排序后,再把有序的子数列合并为完整的有序数列的算法,需要的朋友可以参考下2023-04-04 在日常工作中,Excel表格无疑是我们处理数据最常用的工具之一,本文将深入探讨如何利用 Free Spire.XLS for Python 免费库完成这一任务,让你的数据处理工作效率倍增,希望对大家有所帮助2025-11-11
在日常工作中,Excel表格无疑是我们处理数据最常用的工具之一,本文将深入探讨如何利用 Free Spire.XLS for Python 免费库完成这一任务,让你的数据处理工作效率倍增,希望对大家有所帮助2025-11-11










最新评论