
使用Python实现一个简单实用的文本词频统计分析工具
更新时间:2025年05月29日 09:31:38 作者:笨笨轻松熊
文本分析是自然语言处理(NLP)中的基础任务,而词频统计则是文本分析的入门级应用,本文就来为大家介绍如何实现一个简单而实用的文本词频统计工具吧,非常适合Python初学者练手
前言
文本分析是自然语言处理(NLP)中的基础任务,而词频统计则是文本分析的入门级应用。通过词频分析,我们可以快速了解文本的主题倾向、关键信息分布以及语言使用习惯。本文将带你实现一个简单而实用的文本词频统计工具,非常适合Python初学者练手。
功能特点
支持任意.txt格式文本文件的词频分析
自动处理文本编码问题
使用正则表达式精确提取英文单词(包括带连字符和撇号的单词)
按频率排序并计算每个单词的出现比例
支持查看前N个高频词功能
代码实现
import re
from collections import defaultdict
def word_frequency(file_path, top_n=None):
"""
统计文本文件中的单词频率
:param file_path: 文本文件路径
:param top_n: 显示前N个高频词,默认显示全部
:return: 排序后的单词频率列表
"""
# 读取文件内容
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read().lower() # 转为小写
except FileNotFoundError:
print(f"错误:文件 {file_path} 未找到")
return []
except UnicodeDecodeError:
print("错误:文件编码不支持,请尝试使用其他编码(如gbk)")
return []
# 使用正则表达式提取单词(包括带连字符的单词)
words = re.findall(r"\b[a-zA-Z'-]+\b", text)
# 统计词频
frequency = defaultdict(int)
for word in words:
frequency[word] += 1
# 按频率排序
sorted_words = sorted(frequency.items(), key=lambda x: x[1], reverse=True)
# 输出结果
print(f"\n总共有 {len(words)} 个单词,其中唯一单词 {len(sorted_words)} 个")
print("排名 | 单词\t\t频率\t占比")
print("-" * 40)
total_words = len(words)
for rank, (word, count) in enumerate(sorted_words[:top_n], 1):
percentage = (count / total_words) * 100
print(f"{rank:4} | {word:12} {count:6} \t{percentage:.2f}%")
return sorted_words
if __name__ == "__main__":
# 使用示例
file_path = input("请输入文本文件路径:").strip()
top_n = input("要显示前多少个高频词(默认全部):").strip()
top_n = int(top_n) if top_n.isdigit() else None
word_frequency(file_path, top_n)
代码解析
导入必要模块:
- re:提供正则表达式支持,用于精确提取单词
- defaultdict:特殊字典类型,当键不存在时提供默认值,简化词频统计
核心函数设计:
- 异常处理确保文件打开的健壮性
- 使用正则表达式\b[a-zA-Z'-]+\b提取英文单词(包括带连字符和撇号的复杂形式)
- 采用defaultdict高效统计词频
- 使用Python内置的sorted()函数按词频排序
用户交互:
- 支持自定义文件路径输入
- 灵活设置显示的高频词数量
运行效果
将以下文本保存为txt文件,然后运行程序,输入文件路径即可看到分析结果:
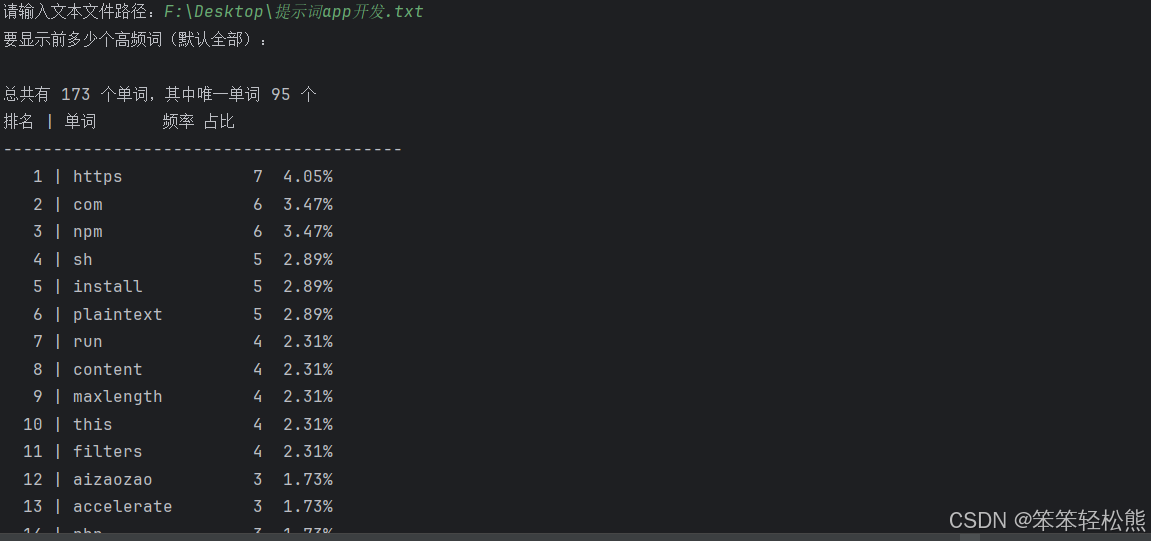
应用场景
英文文学作品词汇分析
论文关键词提取
网络文本主题挖掘
语言学习词汇频率研究
进阶改进方向
增加中文分词支持(可结合jieba等分词库)
添加停用词过滤功能
实现数据可视化展示(如词云图)
开发GUI界面提升用户体验
支持批量文件分析比较
到此这篇关于使用Python实现一个简单实用的文本词频统计分析工具的文章就介绍到这了,更多相关Python文本词频统计分析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

Python Opencv 通过轨迹(跟踪)栏实现更改整张图像的背景颜色
这篇文章主要介绍了Python Opencv 通过轨迹(跟踪)栏实现更改整张图像的背景颜色,在文章末尾有一个小训练——是将所学得的图像颜色修改应用为画板一般的刷新,需要的朋友可以参考下2020-03-03
Python的Django中django-userena组件的简单使用教程
这篇文章主要介绍了Python的Django中django-userena组件的简单使用教程,包括用户登陆和注册等简单功能的实现,需要的朋友可以参考下2015-05-05 今天小编就为大家分享一篇python在html中插入简单的代码并加上时间戳的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10
今天小编就为大家分享一篇python在html中插入简单的代码并加上时间戳的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10 下面小编就为大家分享一篇python 删除列表里所有空格项的方法总结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
下面小编就为大家分享一篇python 删除列表里所有空格项的方法总结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04 这篇文章主要为大家介绍了python算法深入理解风控中的KS原理解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2021-11-11
这篇文章主要为大家介绍了python算法深入理解风控中的KS原理解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2021-11-11
opencv python 图像轮廓/检测轮廓/绘制轮廓的方法
这篇文章主要介绍了opencv python 图像轮廓/检测轮廓/绘制轮廓的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07 这篇文章主要介绍了Python xpath表达式如何实现数据处理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了Python xpath表达式如何实现数据处理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06 遗传算法(GA)是最早由美国Holland教授提出的一种基于自然界的“适者生存,优胜劣汰”基本法则的智能搜索算法。本文主要介绍了如何通过Python实现遗传算法,感兴趣的同学可以看一看2021-11-11
遗传算法(GA)是最早由美国Holland教授提出的一种基于自然界的“适者生存,优胜劣汰”基本法则的智能搜索算法。本文主要介绍了如何通过Python实现遗传算法,感兴趣的同学可以看一看2021-11-11 这篇文章主要介绍了Python 实现多表和工作簿合并及一表按列拆分,文章围绕主题展开详细的资料介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-05-05
这篇文章主要介绍了Python 实现多表和工作簿合并及一表按列拆分,文章围绕主题展开详细的资料介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-05-05
Python调用Java接口失败(Java日志打印警告:JSON parse error:xxxx)
文章描述了Python调用Java接口时遇到400错误和JSON解析错误的问题,通过分析问题发现参数传递方式可能存在问题,修改Python代码使用data参数并序列化数据后,问题解决,文章总结了在Python调用Java接口传递JSONObject数据时的注意事项,需要的朋友可以参考下2025-11-11










最新评论