
一文详解如何分析python程序cpu占用率问题
问题
某天我看了一下目前在跑的一个 python 程序的 CPU 利用率,发现跑到了 100%

这个程序本身执行的任务很多,开启了很多的线程,跑到 100% 也可以说的过去。但是作为程序员的好奇心就被勾引起来了
java 可以通过 “top -Hp + jstack + 代码” 精准定位到 cpu 高利用率的原因。那么在 python 中,通过什么方式可以实现相同的目的?
一、方案调研
经过简单的调研,python 和 java 排查的思路不太一样,有下面三种工具可以使用:cProfile、py-spy、yappi
| cProfile | py-spy | yappi | |
|---|---|---|---|
| 使用便捷性 | 无需安装,使用简单(直接导入标准库) | 需额外安装,命令行操作,可能需要管理员权限 | 需额外安装,需在代码中初始化/启动/停止 |
| 功能特性 | 统计函数调用次数、执行时间等基础信息,不支持多线程/异步代码 | 支持多线程/异步分析,可实时分析运行中的进程,生成火焰图 | 支持多线程/协程分析,可自定义时钟类型(CPU时间或墙钟时间) |
| 性能影响 | 对性能有一定影响(大型程序更明显) | 非侵入式,对目标进程性能影响极小 | 性能影响较小,但大规模程序可能有开销 |
| 分析结果展示 | 文本输出(复杂场景难解读) | 火焰图可视化,直观定位瓶颈 | 详细统计数据(需学习成本),支持多种输出格式 |
| 适用场景 | 开发阶段初步性能分析(定位耗时函数) | 生产环境实时分析(快速定位CPU高负载问题) | 复杂多线程/异步程序深度分析 |
二、每个工具实际使用的效果
2.1 cProfile
基本使用方式是修改程序的启动入口
import cProfile
def main():
... # 程序入口
if __name__ == "__main__":
cProfile.run('main()', sort='cumtime')
然后控制台启动程序,运行足够长的时间后,终止程序(ctrl + c)时就会输出对应的函数执行统计,如下图:
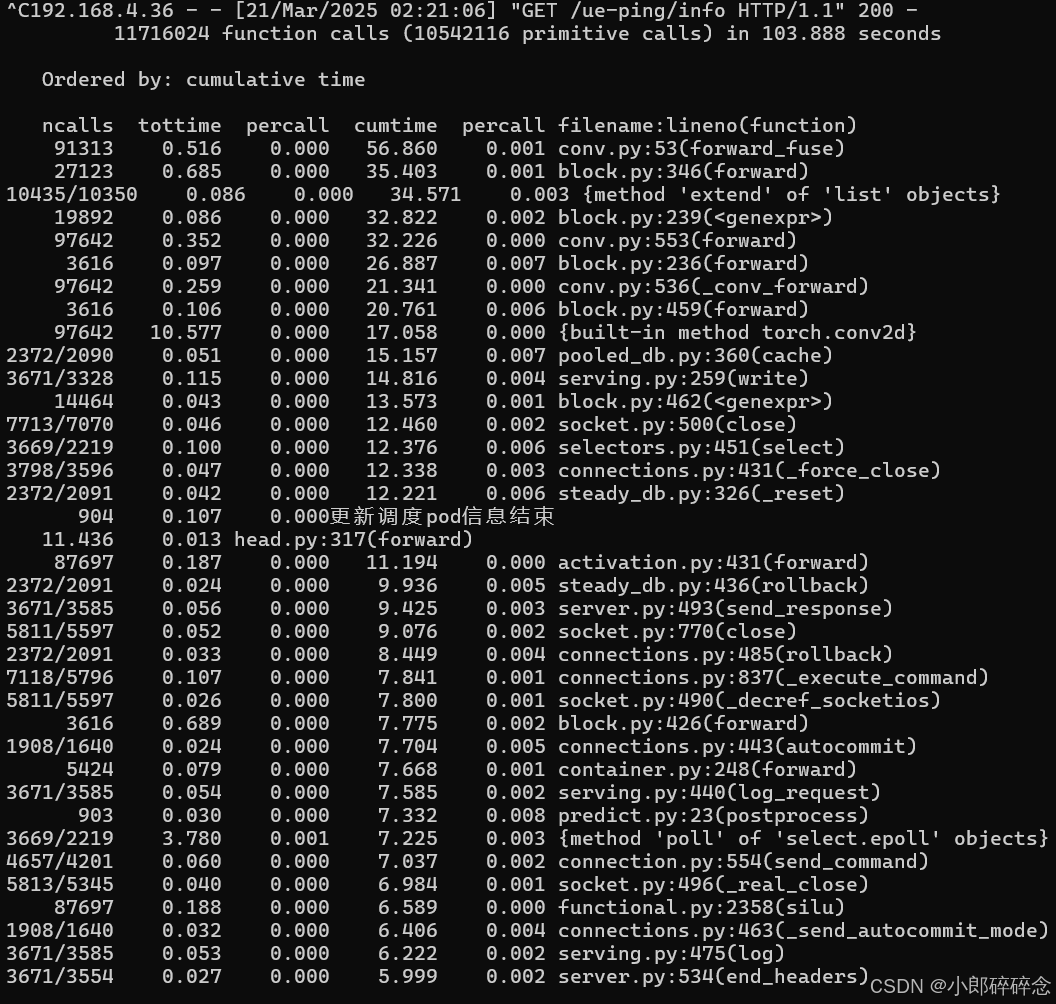
输出表格各列含义如下
- ncalls:函数被调用的次数。
- tottime:函数自身执行所耗费的总时间,不包含调用其他函数的时间。
- percall:每次调用函数所花费的平均时间,即 tottime / ncalls。
- cumtime:函数执行的累积时间,包含调用其他函数的时间。
- percall:函数每次调用的累积平均时间,即 cumtime / ncalls。
- filename:lineno(function):函数所在的文件名、行号以及函数名。
整体上看相对来说不够直观,所以我的策略是,将结果拷贝进 excel 表格,分别按照 tottime 和 cumtime 排序,然后将结果取前 20 行放入大语言模型进行分析。提示词如下
你是一位资深的 python 专家和系统运维专家
你的任务是使用 cProfile 工具排查 python 程序 cpu 利用率过高的问题,并提出对应的优化和解决建议
cProfile 的输出如下
按照 cumtime 排序
---
ncalls tottime pe rcall cumtime pe rcall filename:lineno(function)
91313 0.516 0 56.86 0.001 conv.py:53(forward_fuse)
27123 0.685 0 35.403 0.001 block.py:346(forward)
10435/10350 0.086 0 34.571 0 03 {method 'extend' of 'list' objects}
19892 0.086 0 32.822 0.002 block.py:239(<genexpr>)
97642 0.352 0 32.226 0 conv.py:553(forward)
3616 0.097 0 26.887 0.007 block.py:236(forward)
97642 0.259 0 21.341 0 conv.py:536(_conv_forward)
3616 0.106 0 20.761 0.006 block.py:459(forward)
97642 10.577 0 17.058 0 {built-in method torch.conv2d}
2372/2090 0.051 0 15.157 0.007 pooled_db.py:360(cache)
3671/3328 0.115 0 14.816 0.004 serving.py:259(write)
14464 0.043 0 13.573 0.001 block.py:462(<genexpr>)
7713/7070 0.046 0 12.46 0.002 socket.py:500(close)
3669/2219 0.1 0 12.376 0.006 selectors.py:451(select)
3798/3596 0.047 0 12.338 0.003 connections.py:431(_force_close)
2372/2091 0.042 0 12.221 0.006 steady_db.py:326(_reset)
904 0.107 0 11.436 0.013 head.py:317(forward)
87697 0.187 0 11.194 0 activation.py:431(forward)
2372/2091 0.024 0 9.936 0.005 steady_db.py:436(rollback)
3671/3585 0.056 0 9.425 0.003 server.py:493(send_response)
...(省略)
---
按照 tottime 如下
---
ncalls tottime pe rcall cumtime pe rcall filename:lineno(function)
97642 10.577 0 17.058 0 {built-in method torch.conv2d}
1492/89 10.445 0.007 0.751 0.008 {method 'read' of 'cv2.VideoCapture' objects}
3660/317 9.277 0.003 2.85 0.009 {method 'poll' of 'select.poll' objects}
741/0 6.681 0.009 0 {built-in method time.sleep}
3669/2219 3.78 0.001 7.225 0.003 {method 'poll' of 'select.epoll' objects}
1522/185 2.446 0.002 0.4 0.002 {flip}
6328 1.948 0 3.359 0.001 {built-in method torch.einsum}
345354/12 1.613 0 1.368 0.114 module.py:1740(_call_impl)
903/1 1.581 0.002 0.003 0.003 {resize}
87697 1.573 0 4.584 0 {built-in method torch._C._nn.silu_}
16399/10112 1.556 0 3.308 0 00 {method 'recv_into' of '_socket.socket' objects}
23770/139 1.544 0 0.19 0.001 {method 'sendall' of '_socket.socket' objects}
345353/12 1.184 0 1.368 0.114 module.py:1732(_wrapped_call_impl)
3616 1.117 0 1.921 0.001 {built-in method torch._C._nn.linear}
439192 1.1 0 1.347 0 client.py:75(__setitem__)
9352/153 1.043 0 0.016 0 {method 'recv' of '_socket.socket' objects}
53147/50648 0.798 0 2.345 0 00 {method 'settimeout' of '_socket.socket' objects}
516359 0.783 0 0.783 0 module.py:1918(__getattr__)
18081 0.722 0 1.736 0 {built-in method torch.cat}
3616 0.689 0 7.775 0.002 block.py:426(forward)
...(省略)
---
你的分析结果应该包含每个问题的影响程度,以及你分析的依据(即从 cProfile 哪个数据得到的这个结论)
具体输出就不展示了,大语言模型每次都可以分析出问题的原因之一在于模型推理存在大量的 cpu 使用(未经过工程上的优化)。但是一些其他问题,输出不太稳定,例如 connections.py:431(_force_close) 有时能捕捉到是因为频繁地关闭数据库连接问题,但很多时候有捕捉不到这个问题。
主要的问题在于,cProfile 输出的每一行,都是以函数为维度的,函数之间的关联无法很好的捕捉到,例如 method 'extend' of 'list' objects 有点模糊。
2.2 py-spy
安装
pip install py-spy
使用(需要 sudo 权限),输出火焰图
# -o 输出文件名 # -d 采样多久 py-spy record -o profile.svg -d 60 -p <pid>
svg 文件可以直接使用浏览器打开,从下图可以看出,火焰图可以很直观地定位到一些瓶颈问题
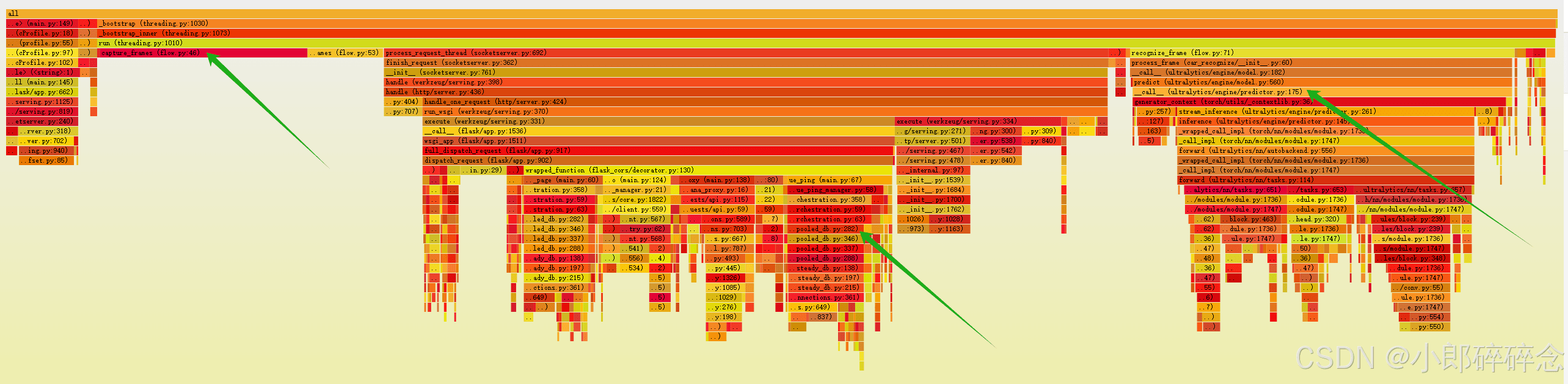
不过遗憾的是,svg 文件大语言模型还无法很好的支持,如果截图给 AI 分析,又有很多文字省略了。
2.3 yappi
安装
pip install yappi
使用,对于有执行结束的程序
yappi.set_clock_type("cpu") # cpu or wall
yappi.start()
my_function()
yappi.stop()
stats = yappi.get_func_stats()
# stats.print_all()
stats.save('yappi_stats.callgrind', type='callgrind')
对于无法结束的程序,例如网络接口,可以如下(使用 kill -10 <pid> 来触发写入结果,实测写的过程会 hang 住主进程,最好再单独开启一个写文件线程!)
import yappi
import signal
def start_all():
app.run(debug=False, host='0.0.0.0', port=5000)
def handle_sigusr1(signum, frame):
print("接收到 SIGUSR1 信号,正在停止 yappi 分析并保存结果...")
yappi.stop()
stats = yappi.get_func_stats()
stats.save('yappi_stats.callgrind', type='callgrind')
print("yappi 分析结果已保存为 yappi_stats.callgrind")
if __name__ == '__main__':
yappi.set_clock_type("cpu")
yappi.start()
# 注册 SIGUSR1 信号处理函数
signal.signal(signal.SIGUSR1, handle_sigusr1)
start_all()callgrind 是一种特殊格式的文件,windows 可以使用 QCacheGrind 查看(下载地址)
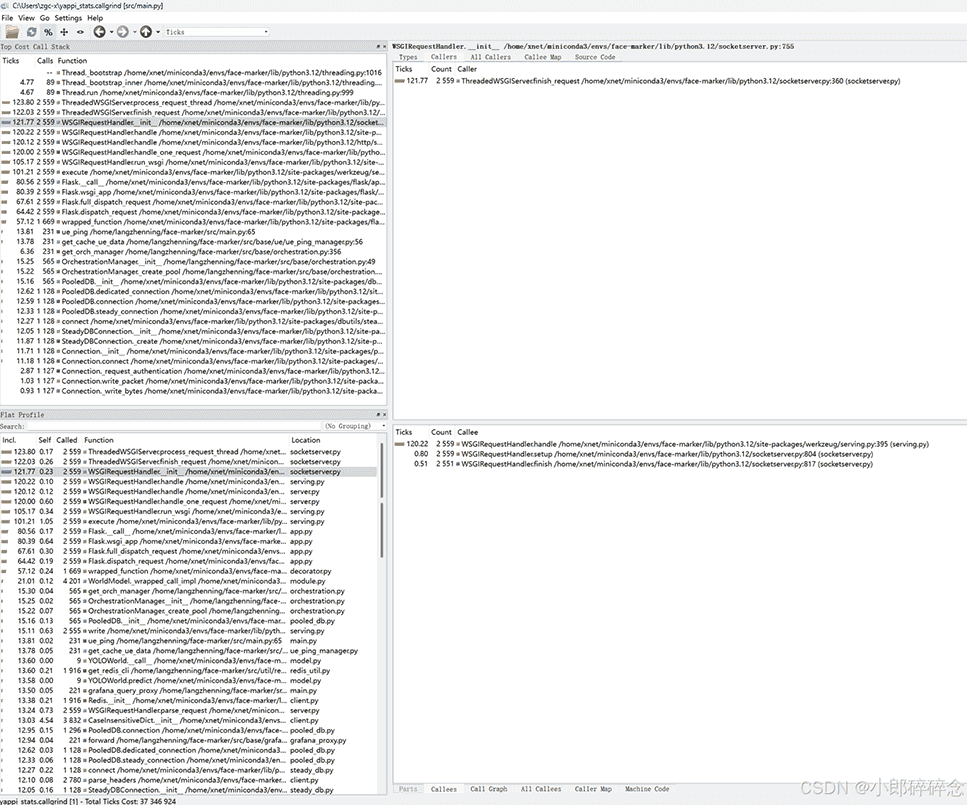
我仔细看了这里列的热点代码,整体上来说和 cProfile 以及 py-spy 相差较多,基本分析不出来什么有用信息。
我也不知道是不是自己使用姿势有问题,但如果这个工具学习成本这么高,说明它实际上也不是一个简单易用的工具。
总结
整体使用下来,cProfile 和 py-spy 的结果是可以相互印证的。但我还是 比较推荐 py-spy,原因如下
- 安装简单
- 不需要改代码,使用方便
- 火焰图结果看起来直观易懂
- 看文档还可以把完整的执行栈 dump 出来,这样实际可以和 java 的排查思路一致了(上面例子中没有尝试,后面有实际问题可以尝试一下)
当然,实际情况下,很可能要多种工具齐上阵,综合分析才能得到准确的问题排查结果。
到此这篇关于python程序cpu占用率问题的文章就介绍到这了,更多相关python程序cpu占用率问题内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 使用数据库时,我们利用查询操作对各列或各行中的数据进行分组,可以针对其中的每一组数据进行各种不同的操作,本文主要介绍了pandas聚合分组,感兴趣的可以了解一下2024-03-03
使用数据库时,我们利用查询操作对各列或各行中的数据进行分组,可以针对其中的每一组数据进行各种不同的操作,本文主要介绍了pandas聚合分组,感兴趣的可以了解一下2024-03-03 这篇文章主要给大家介绍了关于python问题汇总之pycharm查找不到安装库的解决方法,PyCharm是一款非常流行的Python集成开发环境(IDE),它提供了丰富的功能和插件,可以帮助程序员更高效地编写Python代码,需要的朋友可以参考下2023-09-09
这篇文章主要给大家介绍了关于python问题汇总之pycharm查找不到安装库的解决方法,PyCharm是一款非常流行的Python集成开发环境(IDE),它提供了丰富的功能和插件,可以帮助程序员更高效地编写Python代码,需要的朋友可以参考下2023-09-09 这篇文章主要为大家介绍了pandas选择或添加列生成新的DataFrame实现,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了pandas选择或添加列生成新的DataFrame实现,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 本文主要介绍了python中opencv支持向量机的实现,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03
本文主要介绍了python中opencv支持向量机的实现,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03 下面小编就为大家分享一篇Python序列循环移位的3种方法推荐,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
下面小编就为大家分享一篇Python序列循环移位的3种方法推荐,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04 这篇文章主要介绍了pytorch 梯度NAN异常值的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了pytorch 梯度NAN异常值的解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06 这篇文章主要介绍了python在线编译器的简单原理及简单实现代码,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-02-02
这篇文章主要介绍了python在线编译器的简单原理及简单实现代码,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-02-02 在本篇文章中我们给大家分享了Python找出微信上删除你好友的人脚本写法以及相关实例代码,有需要的朋友们参考下。2018-11-11
在本篇文章中我们给大家分享了Python找出微信上删除你好友的人脚本写法以及相关实例代码,有需要的朋友们参考下。2018-11-11 这篇文章主要介绍了一文秒懂Python中的字符串,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03
这篇文章主要介绍了一文秒懂Python中的字符串,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03
Python将Markdown转换为HTML的主流实现方法对比
在日常的技术写作和文档管理中,Markdown 凭借其简洁的语法成为众多开发者的首选,本文将介绍使用 Python 将 Markdown 转换为 HTML 的常用方法,分别适用于不同的使用场景,大家可以根据需要进行选择2026-04-04










最新评论