
Python实现读取PDF中的文本,图片与文档属性
更新时间:2025年06月08日 08:21:32 作者:Eiceblue
PDF格式因其版式固定、内容稳定而被广泛使用,本文将介绍如何用Python实现PDF文本读取,图片提取以及文档属性读取 三大核心操作,适用于信息抽取,电子档案处理等场景,有需要的可以了解下
在日常的数据采集、文档归档与信息挖掘过程中,PDF格式因其版式固定、内容稳定而被广泛使用。Python 开发者若希望实现 PDF 内容的自动化提取,选择一个易用且功能完善的库至关重要。本文将介绍如何用Python实现 PDF文本读取、图片提取 以及 文档属性读取 三大核心操作,适用于信息抽取、电子档案处理等场景。
本文使用免费的 Free Spire.PDF for Python,pip安装:pip install spire.pdf.free
Python读取PDF文本
在PDF中提取可识别的文字内容,是信息处理的基础需求。Spire.PDF 提供了 PdfTextExtractor 类,可逐页提取文本,并通过参数控制提取方式。
操作说明:
- 创建 PdfDocument 实例并加载PDF;
- 遍历每一页,构建 PdfTextExtractor;
- 设置提取选项,如是否简化布局;
- 累加获取到的文本内容。
代码示例:
from spire.pdf import PdfDocument, PdfTextExtractor, PdfTextExtractOptions
# 创建 PdfDocument 实例并加载文档
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
all_text = ""
# 遍历所有页面
for pageIndex in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(pageIndex)
# 创建文本提取器
text_extractor = PdfTextExtractor(page)
# 设置提取选项
options = PdfTextExtractOptions()
options.IsExtractAllText = True
options.IsSimpleExtraction = True
# 提取文本并累加
all_text += text_extractor.ExtractText(options)
# 输出全部文本内容
print(all_text)
PDF文档:

读取的PDF文本:

Python读取PDF图片
PDF中的图片可能包含插图、图标、水印等重要信息。Spire.PDF 提供了 PdfImageHelper 工具类,可提取页面中嵌入的图像并保存为文件。
操作说明:
- 加载PDF文档并获取页面;
- 使用 PdfImageHelper.GetImagesInfo() 获取图片信息;
- 遍历并保存提取的图片对象。
代码示例:
from spire.pdf import PdfDocument, PdfImageHelper
# 加载PDF文件
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# 获取第一页
page = pdf.Pages.get_Item(0)
# 创建图片助手
image_helper = PdfImageHelper()
# 获取页面中的图片信息
images_info = image_helper.GetImagesInfo(page)
# 保存图片为本地文件
for i in range(len(images_info)):
images_info[i].Image.Save("output/Images/image" + str(i) + ".png")
读取的PDF图片:
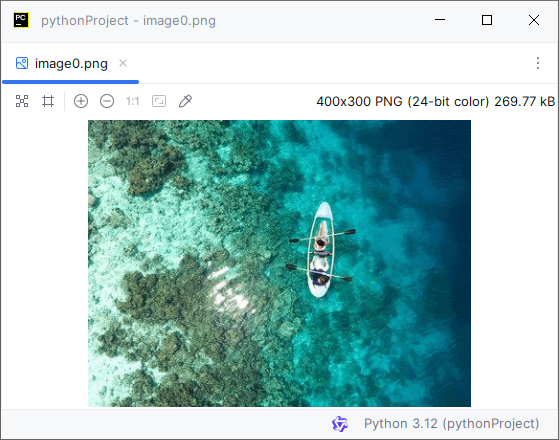
Python读取PDF文档属性
除了内容本身,PDF还可能包含元数据(如标题、作者、关键词等),便于进行文档分类与检索。Spire.PDF 支持直接读取这些信息。
操作说明:
- 加载PDF文件;
- 通过 DocumentInformation 属性访问文档元数据;
- 打印或记录相关属性值。
代码示例:
from spire.pdf import PdfDocument
# 加载PDF文件
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# 获取文档属性信息
properties = pdf.DocumentInformation
print("标题: " + properties.Title)
print("作者: " + properties.Author)
print("主题: " + properties.Subject)
print("关键词: " + properties.Keywords)
读取的PDF文档属性:
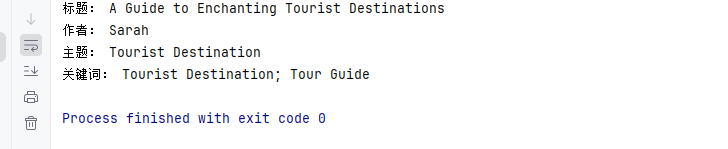
总结
使用 Free Spire.PDF for Python,可以轻松完成以下三类典型的 PDF 信息提取操作:
- 读取PDF文本:逐页提取文字内容,适用于全文分析、搜索系统等;
- 读取PDF图片:提取嵌入图像用于归档、识别或后续处理;
- 读取PDF文档属性:访问标题、作者、关键词等元信息,辅助分类索引。
以上功能均可在本地环境中快速部署,适合构建轻量级 PDF 处理工具或集成至业务系统中。
到此这篇关于Python实现读取PDF中的文本,图片与文档属性的文章就介绍到这了,更多相关Python读取PDF内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 通常,智商测试测验一个人在数字、空间、逻辑、词汇、创造、记忆等方面的能力。本文将利用Python实现一个IQ测试系统,感兴趣的可以了解一下2022-09-09
通常,智商测试测验一个人在数字、空间、逻辑、词汇、创造、记忆等方面的能力。本文将利用Python实现一个IQ测试系统,感兴趣的可以了解一下2022-09-09 我们几乎可以在任何操作系统上通过命令行指令与操作系统进行交互,本文实现了Python系统交互,具有一定的参考价值,感兴趣的可以了解一下2021-07-07
我们几乎可以在任何操作系统上通过命令行指令与操作系统进行交互,本文实现了Python系统交互,具有一定的参考价值,感兴趣的可以了解一下2021-07-07
基于Python+Dify实现批量OCR识别的自动化解决方案
在日常工作中,我们经常会遇到大量图片格式的PDF文件,这类文件无法直接复制文本,手动逐页OCR识别效率极低,下面我们看看如何使用Python和Dify实现全自动化解决这一问题吧2025-12-12 这篇文章主要介绍了使用Python实现跳一跳自动跳跃功能,本文图文并茂通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了使用Python实现跳一跳自动跳跃功能,本文图文并茂通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-07-07 今天小编就为大家分享一篇关于使用Scrapy爬取动态数据的文章,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2018-10-10
今天小编就为大家分享一篇关于使用Scrapy爬取动态数据的文章,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2018-10-10 这篇文章主要为大家详细介绍了使用python接入微信聊天机器人,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-06-06
这篇文章主要为大家详细介绍了使用python接入微信聊天机器人,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-06-06 工作中常需要压缩数据文件大小,压缩PDF文件是一种减少PDF文件大小的方法,这样可以使文件更易于传输和存储,本文将使用Python实现这一功能,需要的可以参考下2024-02-02
工作中常需要压缩数据文件大小,压缩PDF文件是一种减少PDF文件大小的方法,这样可以使文件更易于传输和存储,本文将使用Python实现这一功能,需要的可以参考下2024-02-02 在Python中,如果你有一个包含空值的数据列表,你可以使用列表推导式或循环将这些空值替换为0,本文就来介绍一下如何解决,感兴趣的可以了解一下2024-03-03
在Python中,如果你有一个包含空值的数据列表,你可以使用列表推导式或循环将这些空值替换为0,本文就来介绍一下如何解决,感兴趣的可以了解一下2024-03-03 本文给大家简单介绍了下如何使用Python实现获取IP归属地信息的方法和代码,非常的实用,有需要的小伙伴可以参考下2016-08-08
本文给大家简单介绍了下如何使用Python实现获取IP归属地信息的方法和代码,非常的实用,有需要的小伙伴可以参考下2016-08-08 在本文里小编给各位分享了一篇关于python怎么读出当前时间精度到秒的内容,对此有需要的朋友们可以学习参考下。2019-07-07
在本文里小编给各位分享了一篇关于python怎么读出当前时间精度到秒的内容,对此有需要的朋友们可以学习参考下。2019-07-07










最新评论