
Python爬虫抓取豆瓣TOP250数据从分析到实践的全过程(详细图解)

一、开门见山,探究网页结构
在爬取之前我们要确定需要的数据究竟是在页面源代码里,还是不在页面源代码里(是不是一次性全加载进来的),如果页面源代码里没有想要的数据,说明还有其它请求获取的数据。
让我们打开页面:
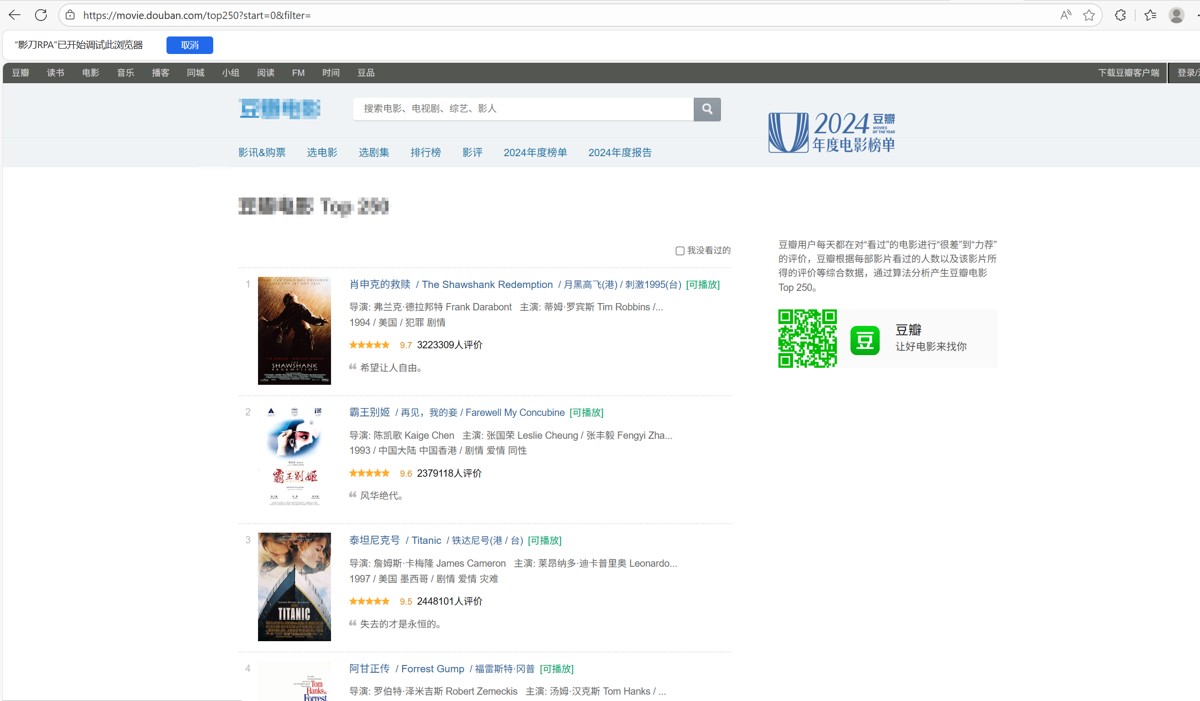
右键查看页面源代码,Ctrl+/页面搜索关键词:肖申克
可以看到这时候我们需要的数据是都在页面源代码里的,验证了我们的想法:该页面数据是一次性全加载进来的,因此得到以下思路。
二、确定思路
1.拿到页面源代码/响应
2.编写正则,提取页面数据
3.保存数据
三、步骤详解
1.初步爬取
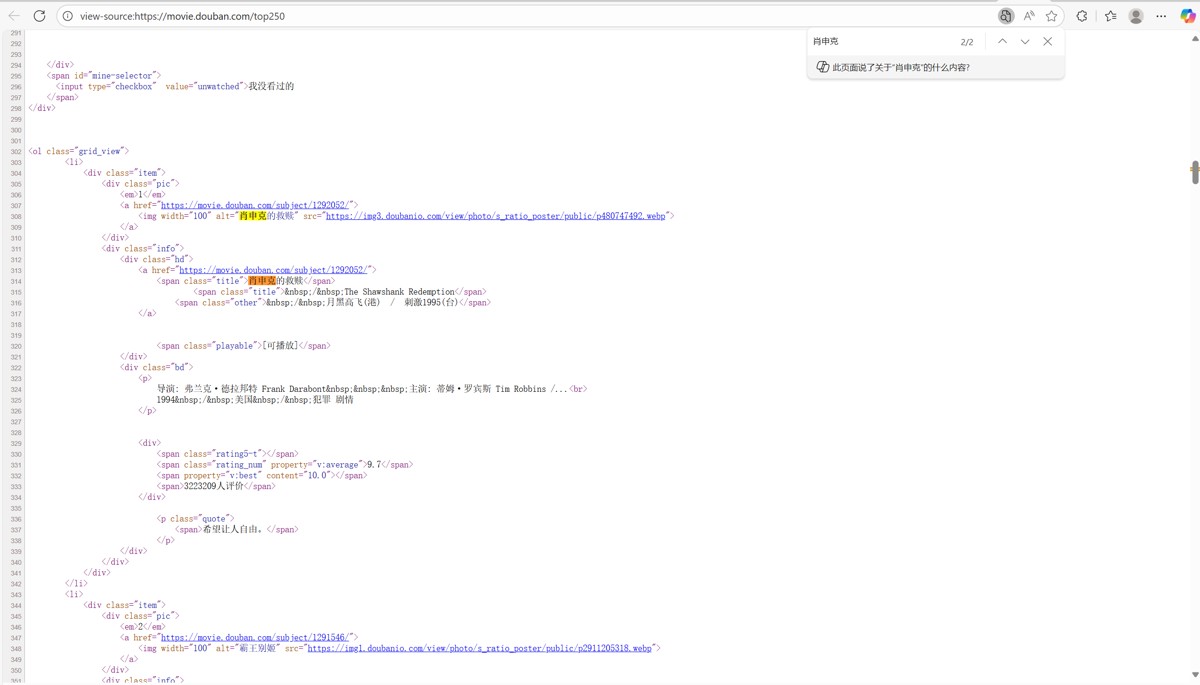
1.1 确定请求方式
接下来按F12,进入开发者工具看看怎么个事儿,发现有个Top250(这个就是第一页的页面url链接,即响应就是页面源代码)
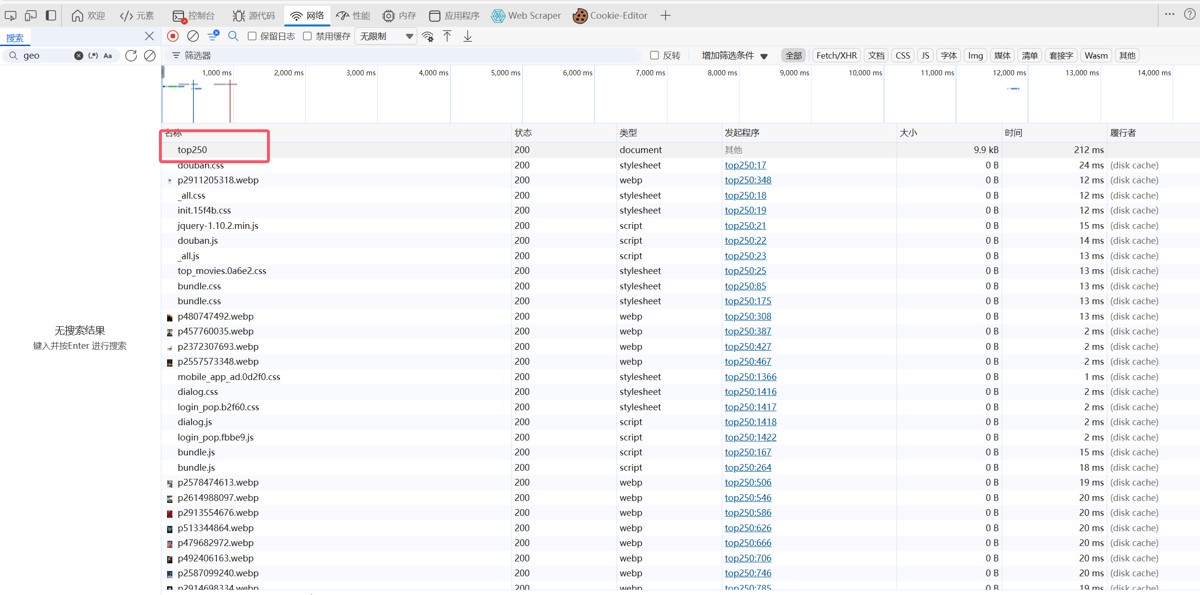
1.2 引入request模块
发现这里的请求是Get,因此引入request模块,导入request.get(页面链接)

import requests url="https://movie.douban.com/top250" resp=requests.get(url) #获取对应页面url的请求响应 pageSource=resp.text #把页面源代码输出 print(pageSource) #打印
这时候运行发现结果是空的:
2.绕过反爬
2.1 加入请求头
说明缺少一个反爬的验证,浏览器自动拦截了,这时候需要加一个请求头
import requests
url="https://movie.douban.com/top250"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
resp=requests.get(url,headers=headers)
pageSource=resp.text
print(pageSource)这样就可以了:
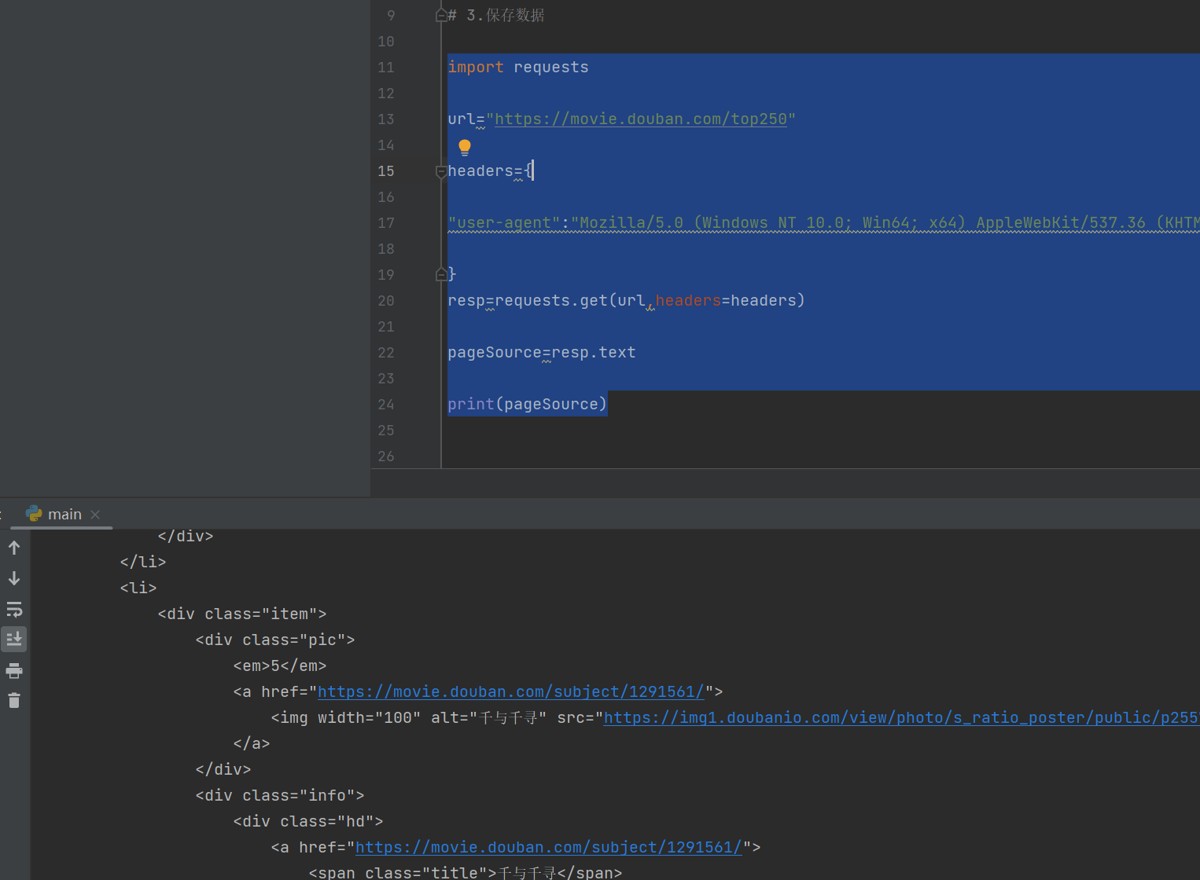
3.编写正则表达式与正则匹配
3.1 编写正则表达式
接下来就需要进行数据分离:
引入re模块,编写正则表达式:
首先从标题开始提取,从<div class="item">为开头,目标是第二个框里的文字内容,这时候需要用到惰性匹配:.*?
3.2 对比表格
这里样例的惰性匹配的结果是两个结果的额原因是开启了全局模式
特性 .*(贪婪).*?(非贪婪/懒惰)核心原则 匹配尽可能多的字符 匹配尽可能少的字符 别名 贪婪模式 非贪婪模式、懒惰模式、最小匹配模式 回溯行为 先吃到尾,再往回找 吃一个看一次,满足就停 示例文本 Hello "World" and "Universe"Hello "World" and "Universe"正则 ".*"".*?"匹配结果 一个结果: "World" and "Universe"两个结果: "World"和"Universe"适用场景 匹配大块的、从开始标志到结束标志之间的所有内容 匹配多个、成对标签/引号之间的单个内容
没有
g标志:
引擎在找到第一个匹配项后就停止。
有
g标志:
引擎在找到第一个匹配项后,会从上次匹配结束的位置开始,继续寻找下一个匹配项。
但是这里还有一个坑,那就是.在匹配的时候是跳过所有非换行符的内容
而re.S可以让正则表达式中的.匹配换行符
#编写正则表达式 re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
3.3 进行正则匹配
接下来进行正则匹配:
#进行正则匹配
result=obj.finditer(pageSource)
for item in result:
print(item.group("name"))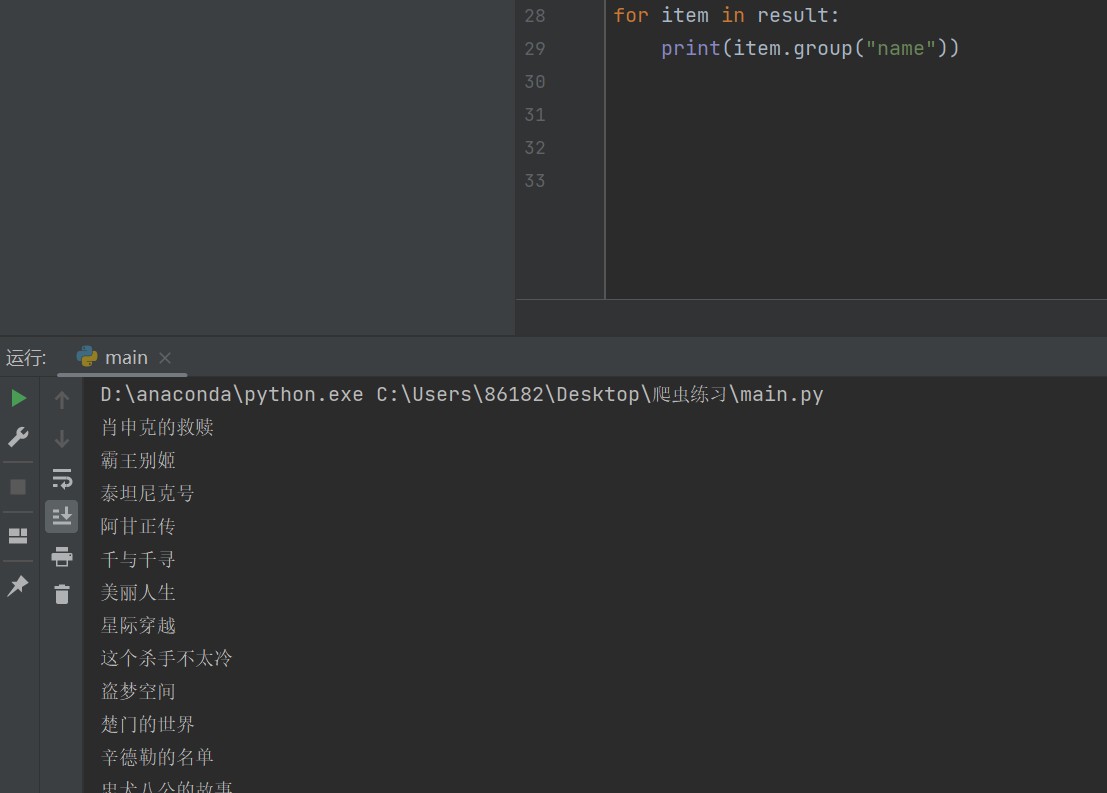
然后根据上面的规则对源代码进行匹配:
#编写正则表达式
obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<div class="bd">'
r'.*?<p>.*?导演: (?P<dao>.*?) '
r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)人评价</span>',re.S)
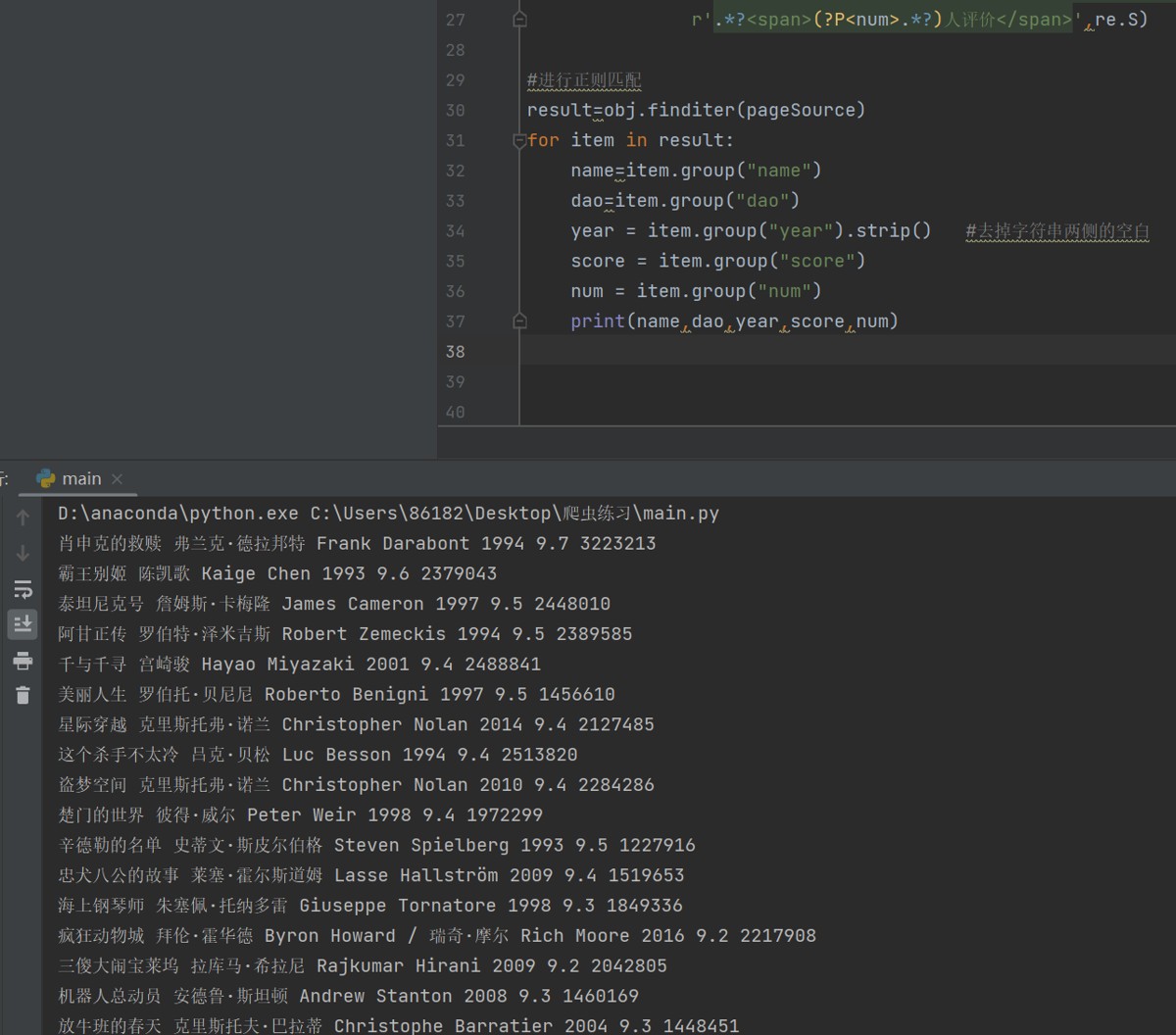
#进行正则匹配
result=obj.finditer(pageSource)
for item in result:
name=item.group("name")
dao=item.group("dao")
year = item.group("year").strip() #去掉字符串两侧的空白
score = item.group("score")
num = item.group("num")
print(name,dao,year,score,num)得到了结果:
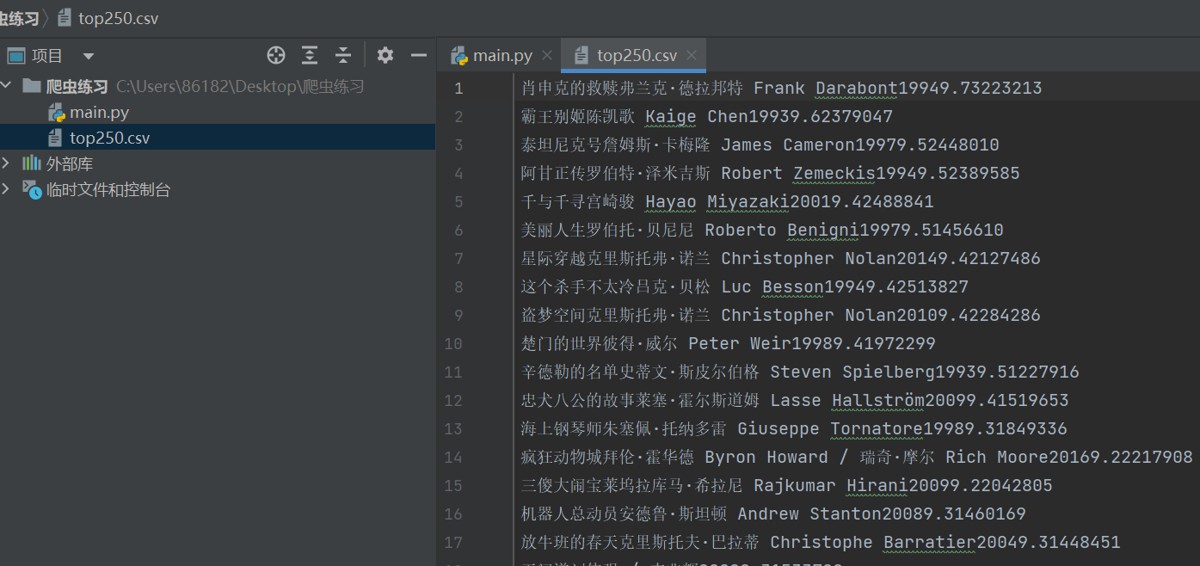
3.4 保存文件
接下来保存为文件:
f=open("top250.csv",mode="w",encoding='utf-8')导出数据:
f.write(f"{name}{dao}{year}{score}{num}\n")
爬取一页的完整代码:
# 思路:
#
# 1.拿到页面源代码
#
# 2.编写正则,提取页面数据
#
# 3.保存数据
import requests
import re
f=open("top250.csv",mode="w",encoding='utf-8')
url="https://movie.douban.com/top250"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
resp=requests.get(url,headers=headers)
resp.encoding="utf-8" #解决乱码问题
pageSource=resp.text
#编写正则表达式
obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<div class="bd">'
r'.*?<p>.*?导演: (?P<dao>.*?) '
r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)人评价</span>',re.S)
#进行正则匹配
result=obj.finditer(pageSource)
for item in result:
name=item.group("name")
dao=item.group("dao")
year = item.group("year").strip() #去掉字符串两侧的空白
score = item.group("score")
num = item.group("num")
f.write(f"{name}{dao}{year}{score}{num}\n")
print(name,dao,year,score,num)
f.close()
resp.close()
print("豆瓣Top250提取完毕")
这时候思考,现在的代码只能爬取一页的25条信息,如何爬取全部250条?
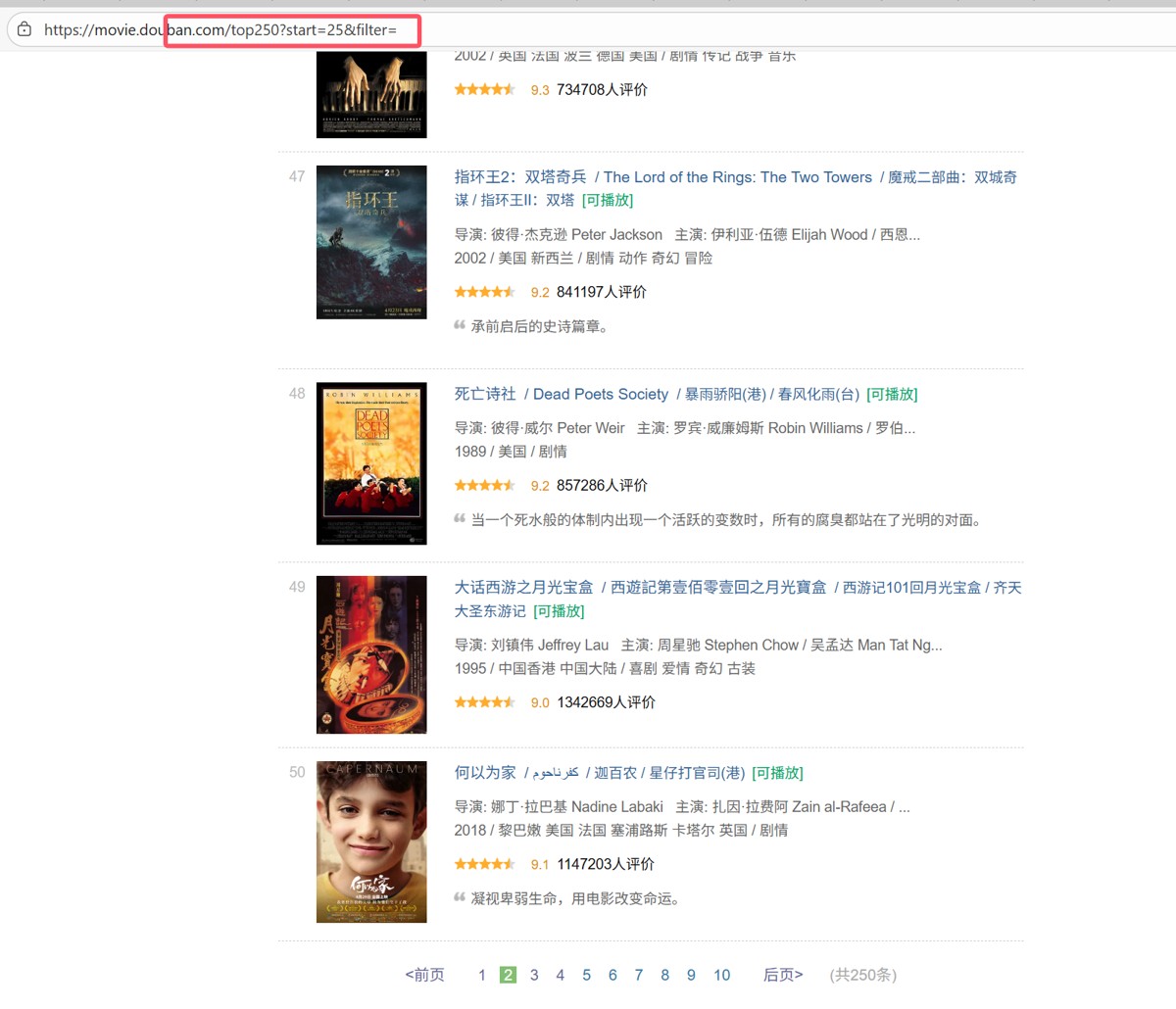
4.翻页爬取
由于发现每跳转一页页面url的start都会增加25,因此得出可以用while循环来爬取全部数据
start=(页数-1)*25
四、完整代码与注意点
1.完整代码
# 思路:
#
# 1.拿到页面源代码
#
# 2.编写正则,提取页面数据
#
# 3.保存数据
import requests
import re
f=open("top250.csv",mode="w",encoding='utf-8')
#start=(页数-1)*25
page=1
while page<=10:
url=f"https://movie.douban.com/top250?start={(page - 1) * 25}&filter="
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
resp=requests.get(url,headers=headers)
resp.encoding="utf-8" #解决乱码问题
pageSource=resp.text
#编写正则表达式
obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<div class="bd">'
r'.*?<p>.*?导演: (?P<dao>.*?) '
r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)人评价</span>',re.S)
#进行正则匹配
result=obj.finditer(pageSource)
for item in result:
name=item.group("name")
dao=item.group("dao")
year = item.group("year").strip() #去掉字符串两侧的空白
score = item.group("score")
num = item.group("num")
f.write(f"{name}{dao}{year}{score}{num}\n")
print(name,dao,year,score,num)
print(f"第{page}页爬取完成")
page = page + 1
f.close()
resp.close()
print("豆瓣Top250提取完毕")2.注意点
解释一下
url=f"https://movie.douban.com/top250?start={(page - 1) * 25}&filter="这里的f必须要加
不加 f 的情况:
url="https://movie.douban.com/top250?start={(page - 1) * 25}&filter="实际URL变成了:
https://movie.douban.com/top250?start={(page - 1) * 25}&filter=注意:{(page - 1) * 25} 被当作普通字符串,而不是要计算的表达式。无论 page 是多少,URL 始终是这个固定的字符串。
豆瓣服务器收到这个请求时,看到 start={(page - 1) * 25},它不知道这是什么,通常会将其视为 start=0 或者忽略这个参数,所以每次都返回第一页的数据。
五、结果展示

成功爬取250条数据~
到此这篇关于Python爬虫抓取豆瓣TOP250数据从分析到实践的全过程(详细图解)的文章就介绍到这了,更多相关Python爬取豆瓣TOP数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python 结巴分词实现关键词抽取分析,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10
这篇文章主要介绍了Python 结巴分词实现关键词抽取分析,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10 在Python中正则写复杂了很麻烦,难写难调试,其实只需要两个函数,就能用简单正则组合构建复杂正则,感兴趣的小伙伴可以跟随小编一起学习一下2024-12-12
在Python中正则写复杂了很麻烦,难写难调试,其实只需要两个函数,就能用简单正则组合构建复杂正则,感兴趣的小伙伴可以跟随小编一起学习一下2024-12-12 这篇文章主要介绍了Python语言实现获取主机名根据端口杀死进程的相关资料,需要的朋友可以参考下2016-03-03
这篇文章主要介绍了Python语言实现获取主机名根据端口杀死进程的相关资料,需要的朋友可以参考下2016-03-03 本文介绍了创建DTSO转DTBO工具的步骤,包括安装Python、使用Python编写命令行和图形界面应用、使用PyInstaller打包为可执行文件,以及测试和分发注意事项,最后提到工具与Flutter无直接关联,后者是Google开发的UI工具包,需要的朋友可以参考下2026-05-05
本文介绍了创建DTSO转DTBO工具的步骤,包括安装Python、使用Python编写命令行和图形界面应用、使用PyInstaller打包为可执行文件,以及测试和分发注意事项,最后提到工具与Flutter无直接关联,后者是Google开发的UI工具包,需要的朋友可以参考下2026-05-05 今天带各位小伙伴学习一下Python高级语法,主要有Lambda表达式,map函数,filter函数,reduce函数,三大推导式等,文中有非常详细的介绍,需要的朋友可以参考下2021-05-05
今天带各位小伙伴学习一下Python高级语法,主要有Lambda表达式,map函数,filter函数,reduce函数,三大推导式等,文中有非常详细的介绍,需要的朋友可以参考下2021-05-05 这篇文章主要介绍了Numpy数组array和矩阵matrix转换方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08
这篇文章主要介绍了Numpy数组array和矩阵matrix转换方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08 这篇文章主要介绍了Python Serial串口的简单数据收发方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09
这篇文章主要介绍了Python Serial串口的简单数据收发方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09 这篇文章主要介绍了python使用sklearn实现决策树的方法示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-09-09
这篇文章主要介绍了python使用sklearn实现决策树的方法示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-09-09 这篇文章主要介绍了如何在pycharm中安装第三方包,本文分步骤通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了如何在pycharm中安装第三方包,本文分步骤通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-10-10 这篇文章主要介绍了Python使用numpy模块创建数组操作,结合实例形式分析了Python使用numpy模块实现数组的创建、赋值、修改、打印等相关操作技巧与注意事项,需要的朋友可以参考下2018-06-06
这篇文章主要介绍了Python使用numpy模块创建数组操作,结合实例形式分析了Python使用numpy模块实现数组的创建、赋值、修改、打印等相关操作技巧与注意事项,需要的朋友可以参考下2018-06-06










最新评论