
将PyInstaller打包的exe文件转换为pyc文件的方法
更新时间:2026年03月01日 15:00:33 作者:Miku-Y
这篇文章主要介绍了如何将.exe文件转换为.py文件,然后使用PyLingual反编译器将.py文件反编译回源代码的过程,需要的朋友可以参考下
一、将exe文件转换成pyc文件
- 新建一个
unpack.py文件,将以下代码复制粘贴进去
from __future__ import print_function
import os
import struct
import marshal
import zlib
import sys
from uuid import uuid4 as uniquename
class CTOCEntry:
def __init__(self, position, cmprsdDataSize, uncmprsdDataSize, cmprsFlag, typeCmprsData, name):
self.position = position
self.cmprsdDataSize = cmprsdDataSize
self.uncmprsdDataSize = uncmprsdDataSize
self.cmprsFlag = cmprsFlag
self.typeCmprsData = typeCmprsData
self.name = name
class PyInstArchive:
PYINST20_COOKIE_SIZE = 24 # For pyinstaller 2.0
PYINST21_COOKIE_SIZE = 24 + 64 # For pyinstaller 2.1+
MAGIC = b'MEI\014\013\012\013\016' # Magic number which identifies pyinstaller
def __init__(self, path):
self.filePath = path
self.pycMagic = b'\0' * 4
self.barePycList = [] # List of pyc's whose headers have to be fixed
def open(self):
try:
self.fPtr = open(self.filePath, 'rb')
self.fileSize = os.stat(self.filePath).st_size
except:
print('[!] Error: Could not open {0}'.format(self.filePath))
return False
return True
def close(self):
try:
self.fPtr.close()
except:
pass
def checkFile(self):
print('[+] Processing {0}'.format(self.filePath))
searchChunkSize = 8192
endPos = self.fileSize
self.cookiePos = -1
if endPos < len(self.MAGIC):
print('[!] Error : File is too short or truncated')
return False
while True:
startPos = endPos - searchChunkSize if endPos >= searchChunkSize else 0
chunkSize = endPos - startPos
if chunkSize < len(self.MAGIC):
break
self.fPtr.seek(startPos, os.SEEK_SET)
data = self.fPtr.read(chunkSize)
offs = data.rfind(self.MAGIC)
if offs != -1:
self.cookiePos = startPos + offs
break
endPos = startPos + len(self.MAGIC) - 1
if startPos == 0:
break
if self.cookiePos == -1:
print('[!] Error : Missing cookie, unsupported pyinstaller version or not a pyinstaller archive')
return False
self.fPtr.seek(self.cookiePos + self.PYINST20_COOKIE_SIZE, os.SEEK_SET)
if b'python' in self.fPtr.read(64).lower():
print('[+] Pyinstaller version: 2.1+')
self.pyinstVer = 21 # pyinstaller 2.1+
else:
self.pyinstVer = 20 # pyinstaller 2.0
print('[+] Pyinstaller version: 2.0')
return True
def getCArchiveInfo(self):
try:
if self.pyinstVer == 20:
self.fPtr.seek(self.cookiePos, os.SEEK_SET)
# Read CArchive cookie
(magic, lengthofPackage, toc, tocLen, pyver) = \
struct.unpack('!8siiii', self.fPtr.read(self.PYINST20_COOKIE_SIZE))
elif self.pyinstVer == 21:
self.fPtr.seek(self.cookiePos, os.SEEK_SET)
# Read CArchive cookie
(magic, lengthofPackage, toc, tocLen, pyver, pylibname) = \
struct.unpack('!8sIIii64s', self.fPtr.read(self.PYINST21_COOKIE_SIZE))
except:
print('[!] Error : The file is not a pyinstaller archive')
return False
self.pymaj, self.pymin = (pyver//100, pyver%100) if pyver >= 100 else (pyver//10, pyver%10)
print('[+] Python version: {0}.{1}'.format(self.pymaj, self.pymin))
# Additional data after the cookie
tailBytes = self.fileSize - self.cookiePos - (self.PYINST20_COOKIE_SIZE if self.pyinstVer == 20 else self.PYINST21_COOKIE_SIZE)
# Overlay is the data appended at the end of the PE
self.overlaySize = lengthofPackage + tailBytes
self.overlayPos = self.fileSize - self.overlaySize
self.tableOfContentsPos = self.overlayPos + toc
self.tableOfContentsSize = tocLen
print('[+] Length of package: {0} bytes'.format(lengthofPackage))
return True
def parseTOC(self):
# Go to the table of contents
self.fPtr.seek(self.tableOfContentsPos, os.SEEK_SET)
self.tocList = []
parsedLen = 0
# Parse table of contents
while parsedLen < self.tableOfContentsSize:
(entrySize, ) = struct.unpack('!i', self.fPtr.read(4))
nameLen = struct.calcsize('!iIIIBc')
(entryPos, cmprsdDataSize, uncmprsdDataSize, cmprsFlag, typeCmprsData, name) = \
struct.unpack( \
'!IIIBc{0}s'.format(entrySize - nameLen), \
self.fPtr.read(entrySize - 4))
try:
name = name.decode("utf-8").rstrip("\0")
except UnicodeDecodeError:
newName = str(uniquename())
print('[!] Warning: File name {0} contains invalid bytes. Using random name {1}'.format(name, newName))
name = newName
# Prevent writing outside the extraction directory
if name.startswith("/"):
name = name.lstrip("/")
if len(name) == 0:
name = str(uniquename())
print('[!] Warning: Found an unamed file in CArchive. Using random name {0}'.format(name))
self.tocList.append( \
CTOCEntry( \
self.overlayPos + entryPos, \
cmprsdDataSize, \
uncmprsdDataSize, \
cmprsFlag, \
typeCmprsData, \
name \
))
parsedLen += entrySize
print('[+] Found {0} files in CArchive'.format(len(self.tocList)))
def _writeRawData(self, filepath, data):
nm = filepath.replace('\\', os.path.sep).replace('/', os.path.sep).replace('..', '__')
nmDir = os.path.dirname(nm)
if nmDir != '' and not os.path.exists(nmDir): # Check if path exists, create if not
os.makedirs(nmDir)
with open(nm, 'wb') as f:
f.write(data)
def extractFiles(self):
print('[+] Beginning extraction...please standby')
extractionDir = os.path.join(os.getcwd(), os.path.basename(self.filePath) + '_extracted')
if not os.path.exists(extractionDir):
os.mkdir(extractionDir)
os.chdir(extractionDir)
for entry in self.tocList:
self.fPtr.seek(entry.position, os.SEEK_SET)
data = self.fPtr.read(entry.cmprsdDataSize)
if entry.cmprsFlag == 1:
try:
data = zlib.decompress(data)
except zlib.error:
print('[!] Error : Failed to decompress {0}'.format(entry.name))
continue
# Malware may tamper with the uncompressed size
# Comment out the assertion in such a case
assert len(data) == entry.uncmprsdDataSize # Sanity Check
if entry.typeCmprsData == b'd' or entry.typeCmprsData == b'o':
# d -> ARCHIVE_ITEM_DEPENDENCY
# o -> ARCHIVE_ITEM_RUNTIME_OPTION
# These are runtime options, not files
continue
basePath = os.path.dirname(entry.name)
if basePath != '':
# Check if path exists, create if not
if not os.path.exists(basePath):
os.makedirs(basePath)
if entry.typeCmprsData == b's':
# s -> ARCHIVE_ITEM_PYSOURCE
# Entry point are expected to be python scripts
print('[+] Possible entry point: {0}.pyc'.format(entry.name))
if self.pycMagic == b'\0' * 4:
# if we don't have the pyc header yet, fix them in a later pass
self.barePycList.append(entry.name + '.pyc')
self._writePyc(entry.name + '.pyc', data)
elif entry.typeCmprsData == b'M' or entry.typeCmprsData == b'm':
# M -> ARCHIVE_ITEM_PYPACKAGE
# m -> ARCHIVE_ITEM_PYMODULE
# packages and modules are pyc files with their header intact
# From PyInstaller 5.3 and above pyc headers are no longer stored
# https://github.com/pyinstaller/pyinstaller/commit/a97fdf
if data[2:4] == b'\r\n':
# < pyinstaller 5.3
if self.pycMagic == b'\0' * 4:
self.pycMagic = data[0:4]
self._writeRawData(entry.name + '.pyc', data)
else:
# >= pyinstaller 5.3
if self.pycMagic == b'\0' * 4:
# if we don't have the pyc header yet, fix them in a later pass
self.barePycList.append(entry.name + '.pyc')
self._writePyc(entry.name + '.pyc', data)
else:
self._writeRawData(entry.name, data)
if entry.typeCmprsData == b'z' or entry.typeCmprsData == b'Z':
self._extractPyz(entry.name)
# Fix bare pyc's if any
self._fixBarePycs()
def _fixBarePycs(self):
for pycFile in self.barePycList:
with open(pycFile, 'r+b') as pycFile:
# Overwrite the first four bytes
pycFile.write(self.pycMagic)
def _writePyc(self, filename, data):
with open(filename, 'wb') as pycFile:
pycFile.write(self.pycMagic) # pyc magic
if self.pymaj >= 3 and self.pymin >= 7: # PEP 552 -- Deterministic pycs
pycFile.write(b'\0' * 4) # Bitfield
pycFile.write(b'\0' * 8) # (Timestamp + size) || hash
else:
pycFile.write(b'\0' * 4) # Timestamp
if self.pymaj >= 3 and self.pymin >= 3:
pycFile.write(b'\0' * 4) # Size parameter added in Python 3.3
pycFile.write(data)
def _extractPyz(self, name):
dirName = name + '_extracted'
# Create a directory for the contents of the pyz
if not os.path.exists(dirName):
os.mkdir(dirName)
with open(name, 'rb') as f:
pyzMagic = f.read(4)
assert pyzMagic == b'PYZ\0' # Sanity Check
pyzPycMagic = f.read(4) # Python magic value
if self.pycMagic == b'\0' * 4:
self.pycMagic = pyzPycMagic
elif self.pycMagic != pyzPycMagic:
self.pycMagic = pyzPycMagic
print('[!] Warning: pyc magic of files inside PYZ archive are different from those in CArchive')
# Skip PYZ extraction if not running under the same python version
if self.pymaj != sys.version_info.major or self.pymin != sys.version_info.minor:
print('[!] Warning: This script is running in a different Python version than the one used to build the executable.')
print('[!] Please run this script in Python {0}.{1} to prevent extraction errors during unmarshalling'.format(self.pymaj, self.pymin))
print('[!] Skipping pyz extraction')
return
(tocPosition, ) = struct.unpack('!i', f.read(4))
f.seek(tocPosition, os.SEEK_SET)
try:
toc = marshal.load(f)
except:
print('[!] Unmarshalling FAILED. Cannot extract {0}. Extracting remaining files.'.format(name))
return
print('[+] Found {0} files in PYZ archive'.format(len(toc)))
# From pyinstaller 3.1+ toc is a list of tuples
if type(toc) == list:
toc = dict(toc)
for key in toc.keys():
(ispkg, pos, length) = toc[key]
f.seek(pos, os.SEEK_SET)
fileName = key
try:
# for Python > 3.3 some keys are bytes object some are str object
fileName = fileName.decode('utf-8')
except:
pass
# Prevent writing outside dirName
fileName = fileName.replace('..', '__').replace('.', os.path.sep)
if ispkg == 1:
filePath = os.path.join(dirName, fileName, '__init__.pyc')
else:
filePath = os.path.join(dirName, fileName + '.pyc')
fileDir = os.path.dirname(filePath)
if not os.path.exists(fileDir):
os.makedirs(fileDir)
try:
data = f.read(length)
data = zlib.decompress(data)
except:
print('[!] Error: Failed to decompress {0}, probably encrypted. Extracting as is.'.format(filePath))
open(filePath + '.encrypted', 'wb').write(data)
else:
self._writePyc(filePath, data)
def main():
if len(sys.argv) < 2:
print('[+] Usage: pyinstxtractor.py <filename>')
else:
arch = PyInstArchive(sys.argv[1])
if arch.open():
if arch.checkFile():
if arch.getCArchiveInfo():
arch.parseTOC()
arch.extractFiles()
arch.close()
print('[+] Successfully extracted pyinstaller archive: {0}'.format(sys.argv[1]))
print('')
print('You can now use a python decompiler on the pyc files within the extracted directory')
return
arch.close()
if __name__ == '__main__':
main()
- 将
暴富.exe跟unpack.py放在同一个目录中,cmd执行如下命令:等待出现Successfully
python unpack.py 暴富.exe
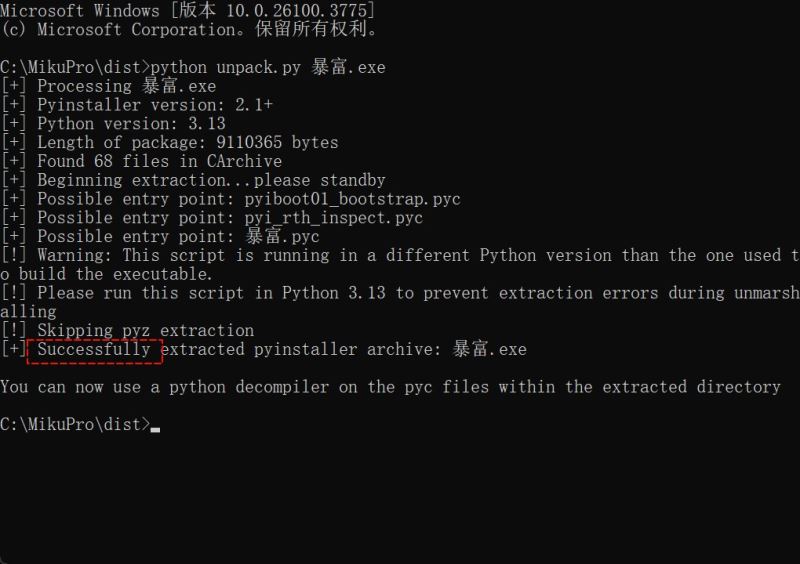
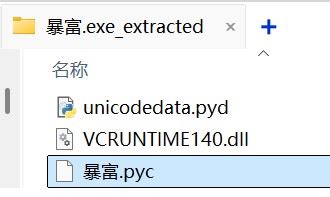
在同目录下生成的暴富.exe_extracted文件夹里找到暴富.pyc
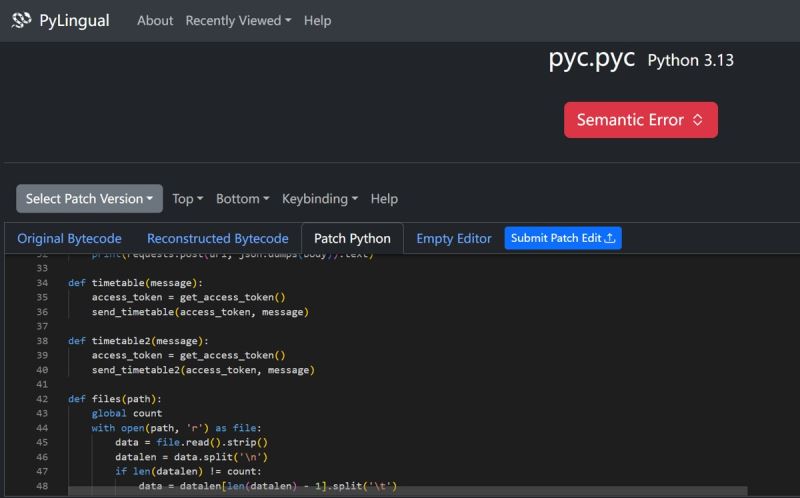
二、将pyc文件反编译成py代码
将暴富.pyc拖入PyLingual反编译器进行反编译,如果打不开网址就使用魔法
以上就是将PyInstaller打包的exe文件转换为pyc文件的方法的详细内容,更多关于PyInstaller exe文件转为pyc文件的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要为大家介绍了Python进阶学习修改闭包内使用的外部变量实现示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06
这篇文章主要为大家介绍了Python进阶学习修改闭包内使用的外部变量实现示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06 JWT是一种用于在各方之间安全传输信息的开放标准,JWT的优势在于无状态、分布式支持和简单性,本文给大家介绍JWT登录鉴权全流程,感兴趣的朋友跟随小编一起看看吧2026-01-01
JWT是一种用于在各方之间安全传输信息的开放标准,JWT的优势在于无状态、分布式支持和简单性,本文给大家介绍JWT登录鉴权全流程,感兴趣的朋友跟随小编一起看看吧2026-01-01 这篇文章主要介绍了Python类的定义、继承及类对象使用方法简明教程,本文用浅显易懂的语言讲解了类的定义、继承及类对象的使用,非常实用易懂,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了Python类的定义、继承及类对象使用方法简明教程,本文用浅显易懂的语言讲解了类的定义、继承及类对象的使用,非常实用易懂,需要的朋友可以参考下2015-05-05 在本篇文章里小编给大家整理的是关于python更新包的相关知识点内容,有兴趣的朋友们可以参考下。2020-06-06
在本篇文章里小编给大家整理的是关于python更新包的相关知识点内容,有兴趣的朋友们可以参考下。2020-06-06 今天小编就为大家分享一篇python 实现矩阵上下/左右翻转,转置的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇python 实现矩阵上下/左右翻转,转置的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 这篇文章主要介绍了Python绘制交通流折线图详情,文章基于python的相关资料展开折线图绘制的实现流程,感兴趣的小伙伴可以参考一下2022-06-06
这篇文章主要介绍了Python绘制交通流折线图详情,文章基于python的相关资料展开折线图绘制的实现流程,感兴趣的小伙伴可以参考一下2022-06-06 这篇文章主要为大家介绍了python return实现汇率转换器教程示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06
这篇文章主要为大家介绍了python return实现汇率转换器教程示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06 这篇文章主要介绍了对于Python的Django框架部署的一些建议,包括项目文件的布局等,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了对于Python的Django框架部署的一些建议,包括项目文件的布局等,需要的朋友可以参考下2015-04-04 俗话说“好记性不如烂笔头”,老祖宗们几千年总结出来的东西还是有些道理的,所以,常用的东西也要记下来,不记不知道,一记吓一跳,乖乖,函数咋这么多捏2014-05-05
俗话说“好记性不如烂笔头”,老祖宗们几千年总结出来的东西还是有些道理的,所以,常用的东西也要记下来,不记不知道,一记吓一跳,乖乖,函数咋这么多捏2014-05-05 本文给大家分享的是使用Python制作爬虫爬取图片的小程序,非常的简单,但是很实用,有需要的小伙伴可以参考下2016-10-10
本文给大家分享的是使用Python制作爬虫爬取图片的小程序,非常的简单,但是很实用,有需要的小伙伴可以参考下2016-10-10










最新评论