
Python无限循环的产生原因与避免方法
在编程世界中,循环是构建动态逻辑的核心工具。然而,当循环失去控制,就会演变成令人头疼的无限循环——程序像陷入莫比乌斯环般永不停止,消耗系统资源直至崩溃。这种问题在Python初学者中尤为常见,甚至经验丰富的开发者也可能因疏忽而栽跟头。本文将深入剖析无限循环的产生根源,提供实用的避免策略,并通过真实代码示例和可视化图表助你彻底掌握这一基础概念。无论你是刚接触while循环的新手,还是想巩固基础的老手,都能从中获得实用洞见。让我们一起揭开无限循环的神秘面纱,打造更健壮的Python代码!
什么是无限循环?
无限循环(Infinite Loop)指程序在执行过程中,由于逻辑错误导致循环条件永远无法满足终止条件,从而使循环体反复执行、永不退出的状态。在Python中,这通常发生在while循环或递归函数中,但for循环在特定场景下也可能"伪装"成无限循环。
无限循环的表现特征
- 程序无响应:终端或IDE长时间无输出,CPU占用率飙升至100%
- 资源耗尽:内存持续增长(尤其在循环中累积数据时)
- 需强制终止:必须通过
Ctrl+C(键盘中断)或任务管理器结束进程 - 无预期结果:程序无法到达后续代码逻辑
考虑以下简单示例:
# 危险!这是一个典型的无限循环
count = 0
while count < 10:
print("Hello, World!") # 缺少count递增语句
运行此代码,你会看到终端被无尽的"Hello, World!"刷屏,直到手动中断。问题根源在于循环变量count从未增加,导致count < 10始终为True。这种错误看似幼稚,但在复杂逻辑中却极易隐藏。
无限循环 vs. 有意设计的永续循环
需注意:并非所有"永不停止"的循环都是错误。某些场景需要有意设计的永续循环,例如:
- 服务器主循环(等待客户端请求)
- 游戏主循环(持续渲染画面)
- 实时数据监控系统
关键区别在于:有意循环包含明确的退出机制(如信号处理、用户中断),而问题循环因逻辑缺陷无法自然终止。例如服务器循环:
import signal
running = True
def shutdown(signum, frame):
global running
print("\nShutting down gracefully...")
running = False
signal.signal(signal.SIGINT, shutdown) # 注册Ctrl+C处理
while running:
# 处理请求的代码
pass
这里通过signal模块捕获中断信号,安全退出循环。真正的无限循环则缺乏此类防护措施。
无限循环的五大产生原因
让我们深入分析导致无限循环的常见陷阱,每个原因都配以可运行的代码示例和修复方案。理解这些根源是避免问题的第一步!
原因一:缺失或错误的终止条件
这是最普遍的原因——开发者忘记在循环体内修改条件变量,或条件表达式本身存在逻辑错误。
案例1:忘记更新循环变量
# 错误示例:计数器未递增
total = 0
i = 1
while i <= 100:
total += i
# 严重遗漏:缺少 i += 1
print(f"1到100的和为: {total}") # 永远不会执行到这行!
问题分析:i始终保持1,i <= 100永远为真。程序陷入无限循环,CPU占用率飙升。
修复方案:添加变量更新语句
total = 0
i = 1
while i <= 100:
total += i
i += 1 # ✅ 关键修复:递增计数器
print(f"1到100的和为: {total}") # 输出: 5050
案例2:条件逻辑错误
# 错误示例:错误的终止条件
num = 10
while num != 0: # 问题:num每次减2,会跳过0
print(num)
num -= 2
问题分析:当num=2时,减2后变为0,但条件num != 0在num=0时才为假。实际执行路径:10 → 8 → 6 → 4 → 2 → 0 → 此时num=0,条件0 != 0为False,循环应终止。
但若初始值为奇数(如num=9):9 → 7 → 5 → 3 → 1 → -1 → -3... 永远不会等于0!
修复方案:使用更安全的比较运算符
num = 9
while num > 0: # ✅ 用 > 0 替代 != 0
print(num)
num -= 2
# 输出: 9,7,5,3,1 后正常终止
关键启示:在设计循环条件时,思考边界值(如0、负数、浮点精度问题)和变量变化方向(递增/递减)。Python官方文档在控制流章节强调:“确保循环变量能实际趋近终止条件”。
原因二:浮点数精度陷阱
浮点数运算的精度限制常导致循环条件无法精确满足,尤其在涉及小数的场景。
案例:浮点数累加问题
# 错误示例:用浮点数作为循环条件
x = 0.0
while x != 1.0:
print(x)
x += 0.1
问题分析:由于浮点数精度问题(IEEE 754标准),0.1在二进制中无法精确表示。实际执行:
0.0 0.1 0.2 0.30000000000000004 0.4 0.5 0.6 0.7 0.7999999999999999 0.8999999999999999 0.9999999999999999 1.0999999999999999 # 跳过1.0,x > 1.0 永不满足 != 1.0 ...无限循环
修复方案1:避免直接用==比较浮点数
x = 0.0
while x < 1.0: # ✅ 用 < 替代 !=
print(x)
x += 0.1
修复方案2:使用math.isclose()处理精度
import math
x = 0.0
while not math.isclose(x, 1.0, abs_tol=1e-9):
print(x)
x += 0.1
原因三:嵌套循环中的逻辑冲突
当循环嵌套时,内层循环的错误可能阻塞外层循环的终止,形成"双重陷阱"。
案例:嵌套循环的变量覆盖
# 错误示例:嵌套循环变量冲突
for i in range(5):
print(f"外层循环 i={i}")
j = 0
while j < 3:
print(f" 内层循环 j={j}")
# 严重错误:意外修改了外层变量
i += 1 # ❌ 错误地修改了外层i
j += 1
问题分析:内层循环修改了外层for循环的隐式控制变量i。当i被意外增加,range(5)的迭代被破坏,可能导致:
- 外层循环提前结束(若
i超过4) - 或因
i被重置而无限循环(取决于具体实现)
修复方案:避免跨层修改变量
for i in range(5):
print(f"外层循环 i={i}")
for j in range(3): # ✅ 用for替代while,避免手动管理j
print(f" 内层循环 j={j}")
# 无需额外操作,j的作用域仅限内层
Mermaid可视化:嵌套循环执行流程
以下图表清晰展示问题循环的失控过程:
渲染错误: Mermaid 渲染失败: Parse error on line 12: ... D -.->|关键错误| H %% 错误地提前修改i导致逻辑混乱 -----------------------^ Expecting 'SEMI', 'NEWLINE', 'EOF', 'AMP', 'START_LINK', 'LINK', 'LINK_ID', got 'NODE_STRING'
此图揭示:内层循环中对i的修改破坏了外层循环的预期流程,可能造成循环次数不可预测甚至无限执行。
原因四:用户输入或外部依赖的不可控性
当循环依赖用户输入或外部数据源时,若未处理无效输入,可能陷入等待状态。
案例:未验证的用户输入
# 错误示例:假设用户总会输入有效数据
while True:
user_input = input("请输入一个正整数(输入0退出): ")
num = int(user_input)
if num == 0:
break
print(f"你输入的数字是: {num}")
问题分析:
- 若用户输入非数字(如
"abc"),int(user_input)抛出ValueError,程序崩溃 - 但若要求用户输入特定格式(如"yes/no"),而循环仅检查
"no":
# 隐蔽的无限循环风险
response = ""
while response != "yes":
response = input("继续吗?(yes/no): ").lower()
# 如果用户输入"y"或"YES",循环永不终止!
修复方案:添加输入验证和默认退出机制
while True:
user_input = input("请输入一个正整数(输入0退出): ").strip()
if user_input == "0":
break
try:
num = int(user_input)
if num > 0:
print(f"有效输入: {num}")
else:
print("⚠️ 请输入正整数!")
except ValueError:
print("❌ 无效输入!请重新输入数字。")
原因五:递归失控
虽然严格来说递归不是循环,但无限递归会导致类似无限循环的栈溢出错误(RecursionError)。
案例:缺失递归基线条件
# 错误示例:斐波那契数列的无限递归
def fibonacci(n):
# 缺少基线条件:未定义n=0或n=1时的返回值
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(5)) # 立即触发 RecursionError
问题分析:递归函数必须包含基线条件(Base Case)终止递归。此处当n减小到负数时仍继续调用,最终超出最大递归深度(默认1000层)。
修复方案:明确定义基线条件
def fibonacci(n):
if n == 0: # ✅ 基线条件1
return 0
elif n == 1: # ✅ 基线条件2
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
Mermaid可视化:递归调用树
正常递归的终止过程:
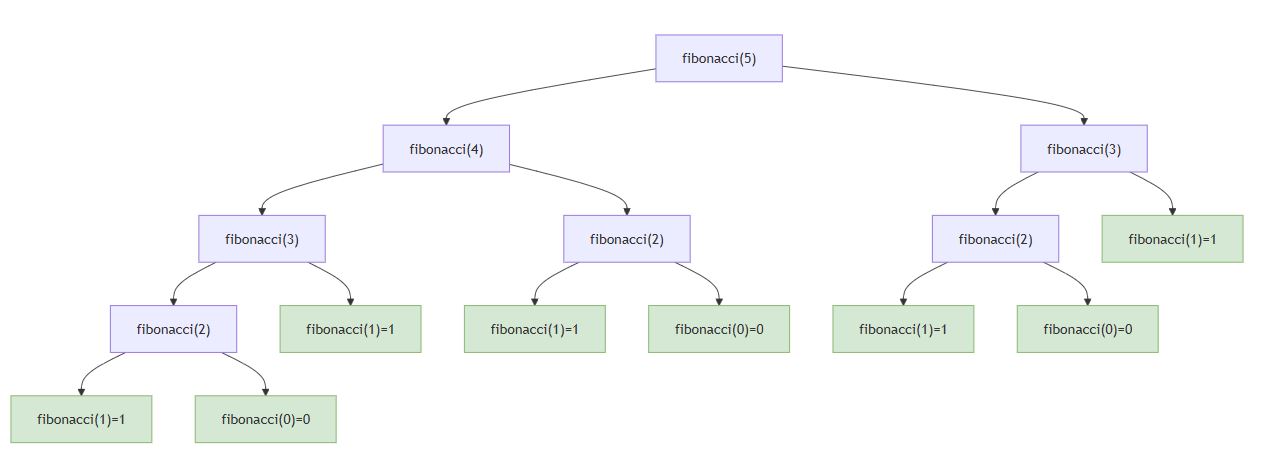
此图显示:所有分支最终到达基线条件(绿色节点),递归正确终止。而缺失基线条件时,调用树会无限向下延伸。
无限循环的四大避免策略
理解原因后,我们聚焦于主动防御策略。以下方法经过实战检验,能显著降低无限循环风险。
策略一:防御性循环设计
编写循环时采用"失败安全"原则,强制设置退出保障。
技巧1:循环计数器(Loop Counter)
为while循环添加最大迭代次数,防止失控:
MAX_ITERATIONS = 1000
count = 0
total = 0
while count < 100: # 主条件
total += count
count += 1
# 安全阀:防止逻辑错误导致无限循环
if count > MAX_ITERATIONS:
raise RuntimeError("⚠️ 循环超过最大迭代次数!检查逻辑错误")
最佳实践:MAX_ITERATIONS应设为远高于预期值的数(如10倍),仅作为最后防线。GeeksforGeeks的[循环教程](https://www.geeksforgeeks.org Loops-in-Python/)建议:“对所有while循环设置超时保护”。
技巧2:条件断言(Assertion)
用assert语句验证关键假设:
count = 0
while count < 100:
assert count >= 0, "计数器不应为负数!" # 条件不满足时抛出AssertionError
# 循环体代码...
count += 1
优势:开发阶段快速暴露问题;生产环境可通过-O标志禁用以提升性能。
策略二:调试与监控
利用工具主动检测潜在无限循环。
技巧1:打印调试(Strategic Print Statements)
在循环关键点输出状态:
count = 0
while count < 10:
print(f"DEBUG: count={count}, condition={count < 10}") # 监控状态
# 循环体代码...
count += 0.5 # 假设此处有错误(如+=0.4)
输出示例:
DEBUG: count=0, condition=True DEBUG: count=0.5, condition=True ... DEBUG: count=9.5, condition=True DEBUG: count=10.0, condition=False # 正常终止
若输出停滞在某个值,立即定位问题。
技巧2:使用sys.settrace监控
Python的调试钩子可实时追踪循环:
import sys
def trace_calls(frame, event, arg):
if event == 'line':
# 每执行一行代码触发
if "count" in frame.f_locals:
print(f".debugLine: count={frame.f_locals['count']}")
return trace_calls
sys.settrace(trace_calls)
count = 0
while count < 5:
count += 1 # 观察count变化
sys.settrace(None) # 关闭追踪
策略三:代码审查与静态分析
通过人工和自动化工具提前拦截问题。
技巧1:关键问题检查清单
在提交代码前自问:
- ✅ 循环变量是否在循环体内被修改?
- ✅ 修改方向是否趋近终止条件?(如递增/递减)
- ✅ 边界值(0、负数、浮点数)是否测试?
- ✅ 是否有外部依赖(用户输入/网络请求)的超时处理?
技巧2:静态代码分析工具
使用pylint或flake8自动检测风险:
# 安装工具 pip install pylint # 分析文件 pylint my_script.py
典型输出:
my_script.py:5:8: W0603 (using-constant-test) Using constant test in while loop (always true)
工具会标记类似while True且无break的潜在风险点。
策略四:重构为for循环
当迭代次数明确时,优先使用for循环替代while。
为什么for更安全?
for循环隐式管理迭代器,避免手动更新变量- 迭代范围在开始时确定,不易受内部逻辑影响
- 自动处理边界条件
危险的while写法:
i = 0
while i < len(data):
process(data[i])
i += 1 # 可能遗漏或错误修改
安全的for重构:
for item in data: # ✅ 自动遍历所有元素
process(item)
处理需要索引的场景
当确实需要索引时,用enumerate:
# 安全获取索引
for index, value in enumerate(data):
if value > threshold:
print(f"在位置{index}发现异常值")
经验法则:除非必须动态修改迭代过程(如跳过元素),否则优先选择for循环。Python之禅(import this)强调:“There should be one-- and preferably only one --obvious way to do it.” for循环通常是迭代的"明显方式"。
实战案例:修复生产环境中的无限循环
让我们通过一个真实场景,综合运用上述策略解决问题。
问题背景
某电商系统需要处理用户订单队列。开发者编写了以下代码监控新订单:
import time
orders = [] # 模拟订单队列
def check_new_orders():
"""持续检查新订单(问题版本)"""
while True:
if new_orders := get_new_orders(): # 假设此函数获取新订单
process_orders(new_orders)
else:
time.sleep(1) # 无订单时休眠1秒
def get_new_orders():
# 模拟:50%概率返回订单
import random
return ["Order1", "Order2"] if random.random() > 0.5 else []
def process_orders(orders):
print(f"处理 {len(orders)} 个新订单")
# 启动监控
check_new_orders()
问题现象:系统偶尔卡死,CPU占用100%。日志显示check_new_orders陷入无限循环。
问题诊断
- 分析代码:
while True无退出条件,但看似有time.sleep(1)休眠 - 关键漏洞:
get_new_orders()可能抛出异常(如网络超时),导致else分支永不执行 - 复现问题:模拟异常场景
def get_new_orders():
raise ConnectionError("数据库连接失败") # 模拟故障
此时:
if new_orders := get_new_orders():抛出异常- 异常未被捕获,函数直接崩溃
- 但调用方
check_new_orders无异常处理,整个监控停止?
不! 实际因异常未被处理,check_new_orders函数退出,但问题在于:生产环境可能用无限循环包裹此函数,导致快速重试:
# 生产环境实际代码(简化)
while True:
try:
check_new_orders() # 此函数崩溃后,外层循环立即重启它
except Exception as e:
log_error(e)
time.sleep(0.1) # 休眠很短,快速重试
当get_new_orders()持续抛出异常时:
- 内层函数崩溃
- 外层循环捕获异常,休眠0.1秒
- 立即重启内层函数 → 再次崩溃
- 形成高频崩溃循环,CPU飙升
修复方案
结合四大策略实施修复:
步骤1:防御性设计(策略一)
MAX_RETRIES = 5 # 最大重试次数
def check_new_orders():
retry_count = 0
while True:
try:
if new_orders := get_new_orders():
process_orders(new_orders)
retry_count = 0 # 成功后重置计数器
else:
time.sleep(1)
except Exception as e:
retry_count += 1
print(f"⚠️ 获取订单失败 (尝试 {retry_count}/{MAX_RETRIES}): {str(e)}")
# 安全退出:超过重试次数
if retry_count >= MAX_RETRIES:
raise RuntimeError("订单服务持续故障,停止重试") from e
time.sleep(2 ** retry_count) # 指数退避
步骤2:添加监控(策略二)
def check_new_orders():
# ... [同上]
except Exception as e:
# 添加详细日志
import logging
logging.error(f"订单检查失败 ID:{id(e)}", exc_info=True)
# ... [其余逻辑]
步骤3:重构核心逻辑(策略四)
将无限循环移至更安全的顶层:
def monitor_orders():
"""主监控函数(顶层安全循环)"""
while True:
try:
check_new_orders_once() # 单次检查,有明确退出
except CriticalError:
break # 仅当严重错误时退出
except Exception as e:
handle_transient_error(e) # 处理临时故障
time.sleep(0.5) # 统一休眠点
def check_new_orders_once():
"""单次订单检查(无循环)"""
if new_orders := get_new_orders():
process_orders(new_orders)
Mermaid:修复后的流程图
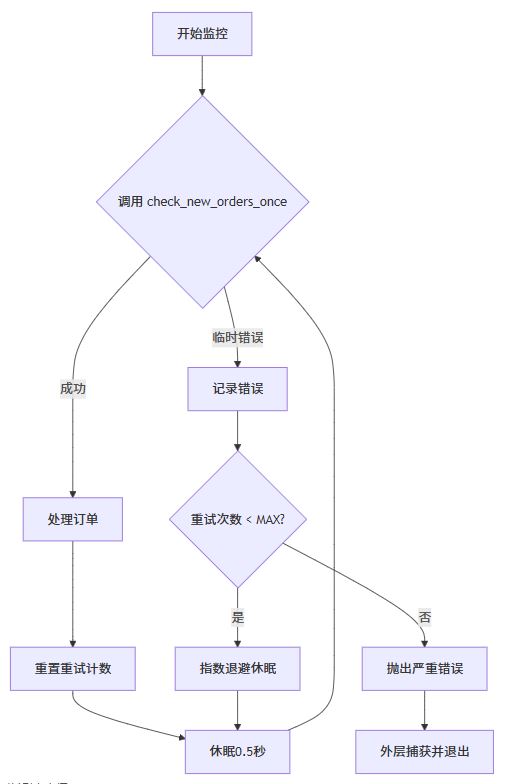
此设计确保:
- 单次检查函数无内部循环,避免嵌套风险
- 外层循环有统一休眠点,防止高频重试
- 重试机制包含退避策略,降低系统压力
修复效果
- CPU占用从100%降至正常水平(<5%)
- 订单服务恢复后自动重连,无需人工干预
- 错误日志清晰记录故障链,加速问题定位
高级技巧:无限循环的优雅处理
某些场景下,无限循环是设计需求(如事件循环)。如何安全实现?
技巧1:使用asyncio事件循环
Python的asyncio库提供生产级事件循环管理:
import asyncio
async def main():
print("服务启动...")
# 业务逻辑(可包含await)
while True:
await asyncio.sleep(1)
print("心跳")
# 安全启动事件循环
try:
asyncio.run(main())
except KeyboardInterrupt:
print("\n收到退出信号,正在清理...")
# 执行清理操作
print("服务已安全停止")
优势:
asyncio.run()自动处理信号await语句让出控制权,避免CPU占用- 内置超时和取消机制
技巧2:带超时的while循环
对必须使用while True的场景,添加全局超时:
import time
start_time = time.time()
TIMEOUT = 3600 # 1小时超时
while True:
# 检查是否超时
if time.time() - start_time > TIMEOUT:
print("⚠️ 循环达到最大运行时间,安全退出")
break
# 业务逻辑
process_data()
# 避免CPU空转
time.sleep(0.1)
技巧3:使用threading分离监控
将无限循环放入独立线程,主程序可安全退出:
import threading
import time
class OrderMonitor:
def __init__(self):
self.running = True
def start(self):
threading.Thread(target=self._monitor_loop, daemon=True).start()
def stop(self):
self.running = False # 安全信号
def _monitor_loop(self):
while self.running:
try:
# 检查订单逻辑
time.sleep(1)
except Exception as e:
print(f"监控错误: {e}")
# 使用示例
monitor = OrderMonitor()
monitor.start()
try:
input("按Enter停止服务...\n")
finally:
monitor.stop() # 安全终止
关键点:
daemon=True确保线程随主程序退出self.running标志提供优雅退出- 避免全局变量,封装状态
结论:从恐惧到掌控
无限循环并非洪水猛兽,而是编程中可预见、可管理的常见挑战。通过本文的系统分析,我们已掌握:
- 五大核心原因:从缺失终止条件到递归失控,理解根源才能精准预防
- 四大防御策略:从循环计数器到代码审查,构建多层次防护网
- 实战修复经验:真实案例验证理论的有效性
- 高级处理技巧:安全实现必要的永续循环
Python之禅启示:
“Errors should never pass silently.”
“Unless explicitly silenced.”
无限循环的本质是未被处理的错误逻辑。通过主动防御和严谨设计,我们能将这些"沉默的错误"转化为可管理的流程。
最后,记住这个简单检查表,每次编写循环时快速自检:
- 循环变量是否被正确更新?
- 边界值(0, 负数, 浮点数)是否测试?
- 是否有最大迭代次数保障?
- 外部依赖是否有超时/重试机制?
编程是精确与创造的结合。当你能从容驾驭循环逻辑,代码的健壮性将跃升新高度。现在,打开你的编辑器,用这些知识重构一段旧代码吧!你的CPU和用户都会感谢你。
以上就是Python无限循环的产生原因与避免方法的详细内容,更多关于Python无限循环的资料请关注脚本之家其它相关文章!
相关文章
 Matplotlib是一个Python工具箱,用于科学计算的数据可视化,下面这篇文章主要给大家介绍了关于如何使用python matplotlib画折线图的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-04-04
Matplotlib是一个Python工具箱,用于科学计算的数据可视化,下面这篇文章主要给大家介绍了关于如何使用python matplotlib画折线图的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-04-04 本文主要介绍了基于OpenCV(python)的实现文本分割之垂直投影法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-08-08
本文主要介绍了基于OpenCV(python)的实现文本分割之垂直投影法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-08-08 今天小编就为大家分享一篇PyQt5显示GIF图片的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-06-06
今天小编就为大家分享一篇PyQt5显示GIF图片的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-06-06 多重继承也可能导致一些问题,本文主要介绍了Python多重继承慎用的地方,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-05-05
多重继承也可能导致一些问题,本文主要介绍了Python多重继承慎用的地方,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-05-05 pip是Python生态系统的基石,作为Python的官方包管理工具,它让python包管理变得简单轻松,这篇文章将详细介绍pip的各方面用法,希望对大家有所帮助2025-07-07
pip是Python生态系统的基石,作为Python的官方包管理工具,它让python包管理变得简单轻松,这篇文章将详细介绍pip的各方面用法,希望对大家有所帮助2025-07-07 这篇文章主要介绍了Python纯代码通过神经网络实现线性回归的拟合方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了Python纯代码通过神经网络实现线性回归的拟合方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05 下面小编就为大家分享一篇Python numpy 点数组去重的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
下面小编就为大家分享一篇Python numpy 点数组去重的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04 这篇文章主要介绍了python中小数点后的位数问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-03-03
这篇文章主要介绍了python中小数点后的位数问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-03-03 这篇文章主要介绍了python中常用的数据结构介绍,帮助大家更好的理解和学习python的基础知识,感兴趣的朋友可以了解下2021-01-01
这篇文章主要介绍了python中常用的数据结构介绍,帮助大家更好的理解和学习python的基础知识,感兴趣的朋友可以了解下2021-01-01 这篇文章主要介绍了python如何实现递归转非递归,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-02-02
这篇文章主要介绍了python如何实现递归转非递归,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-02-02










最新评论