
Python构建多模态AI应用的开发指南
更新时间:2026年04月16日 08:33:54 作者:Halcyon.平安
本文介绍了多模态AI的概念、应用场景和技术架构,并通过实战案例讲解了使用Python构建多模态AI的方法,本文详细介绍了技术架构、环境搭建、实战案例和性能优化等多个方面内容,并并提供了丰富的应用场景示例,需要的朋友可以参考下
单模态AI已经不够用了。2026年,多模态是AI应用的标配能力——让AI同时"看"图片、"听"语音、"读"文字。本文从原理到实战,手把手教你用Python构建多模态AI应用
一、什么是多模态AI?
多模态AI是指能够同时处理和理解多种类型数据(文本、图像、音频、视频等)的AI系统。
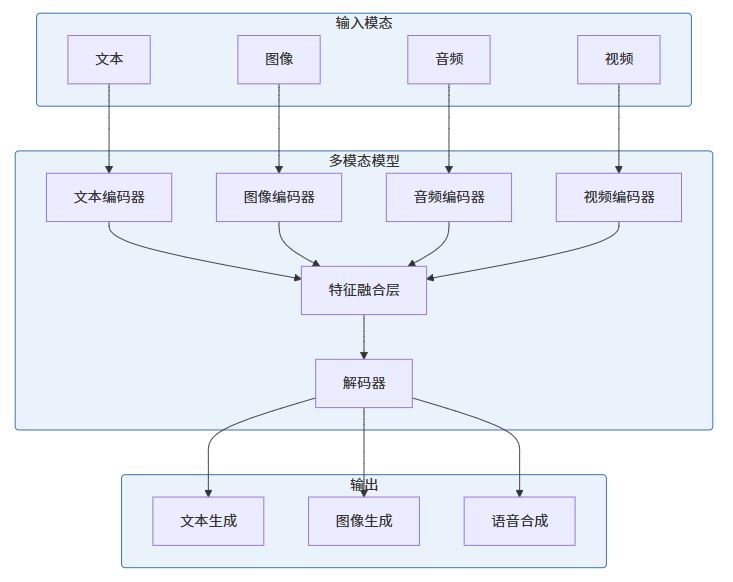
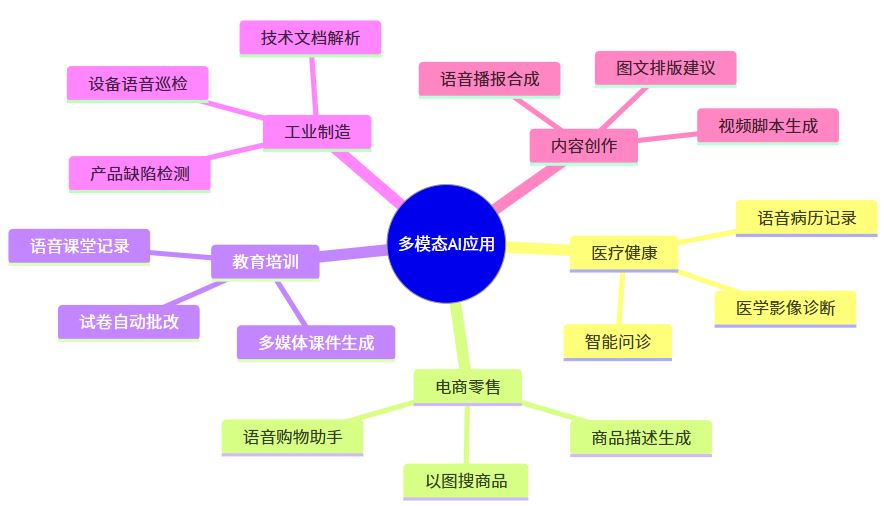
多模态AI的核心价值
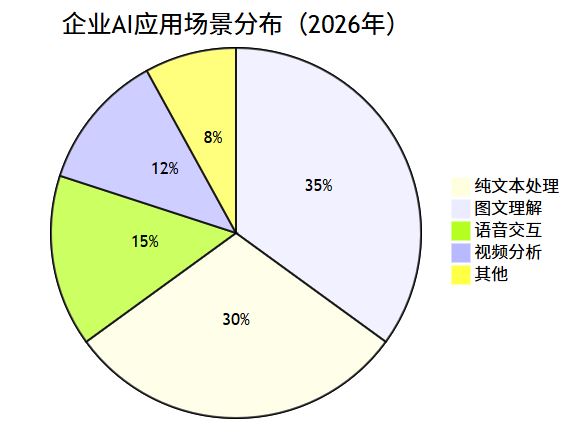
超过70%的企业AI场景需要处理不止一种数据类型。
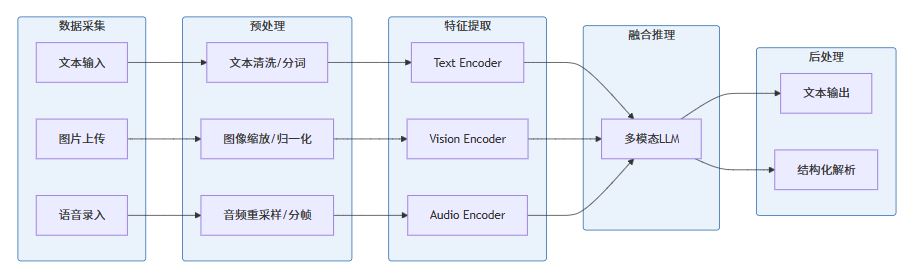
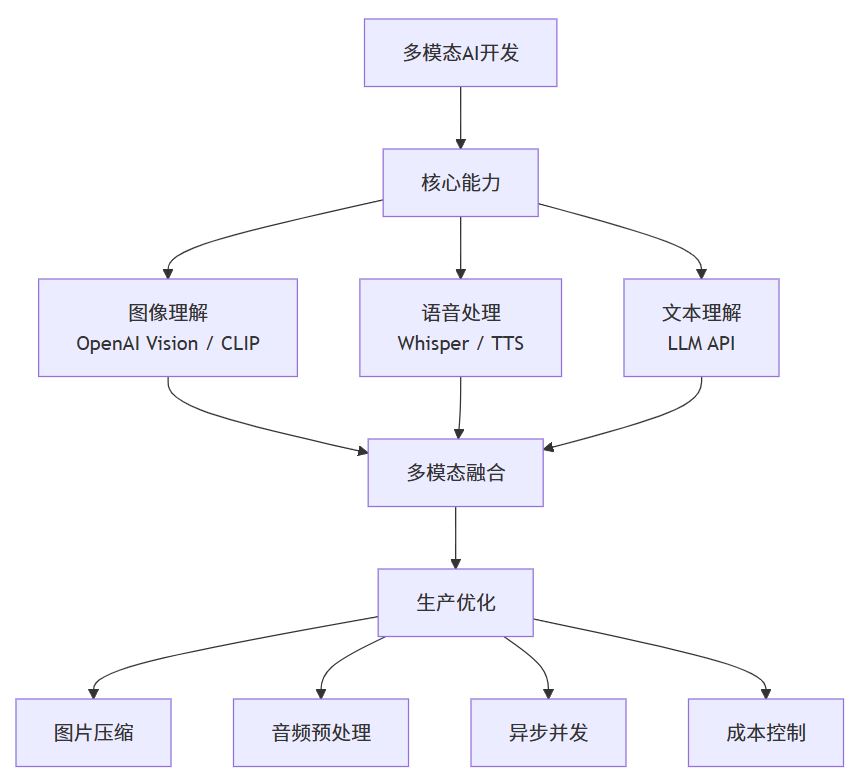
二、技术架构总览
一个完整的多模态AI应用通常包含以下组件:
三、环境搭建
3.1 安装依赖
# 核心依赖 pip install openai>=1.30.0 pip install pillow>=10.0.0 pip install pydub>=0.25.1 pip install requests>=2.31.0 # 语音处理 pip install faster-whisper>=1.0.0 pip install pyttsx3>=2.90 # 图像处理 pip install opencv-python>=4.9.0 pip install ultralytics>=8.2.0
3.2 项目结构
multimodal_app/ ├── config.py # 配置文件 ├── text_handler.py # 文本处理模块 ├── vision_handler.py # 图像处理模块 ├── audio_handler.py # 音频处理模块 ├── multimodal.py # 多模态融合核心 └── main.py # 主入口
四、实战一:文本 + 图像理解
4.1 使用OpenAI多模态API
import base64
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
def encode_image(image_path: str) -> str:
"""将图片编码为base64字符串"""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def analyze_image(image_path: str, question: str) -> str:
"""
多模态图像理解:结合图片内容回答问题
Args:
image_path: 图片路径
question: 要提问的问题
Returns:
模型的回答文本
"""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "你是一个专业的图像分析助手,请详细描述图片内容并回答用户问题。",
},
{
"role": "user",
"content": [
{"type": "text", "text": question},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "high",
},
},
],
},
],
max_tokens=1000,
)
return response.choices[0].message.content
# 使用示例
result = analyze_image(
"dashboard.png",
"请分析这张数据看板截图,告诉我哪个指标表现最好,哪个需要关注。",
)
print(result)
4.2 批量图文分析
from dataclasses import dataclass
from typing import Optional
@dataclass
class ImageAnalysisResult:
"""图像分析结果"""
image_path: str
description: str
labels: list[str]
confidence: float
class MultiImageAnalyzer:
"""批量多图分析器"""
def __init__(self, model: str = "gpt-4o"):
self.client = OpenAI()
self.model = model
def analyze_single(
self, image_path: str, prompt: str
) -> ImageAnalysisResult:
"""分析单张图片"""
base64_img = encode_image(image_path)
response = self.client.chat.completions.create(
model=self.model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_img}",
},
},
],
}
],
response_format={"type": "json_object"},
)
import json
data = json.loads(response.choices[0].message.content)
return ImageAnalysisResult(
image_path=image_path,
description=data.get("description", ""),
labels=data.get("labels", []),
confidence=data.get("confidence", 0.0),
)
def analyze_batch(
self, image_paths: list[str], prompt: str
) -> list[ImageAnalysisResult]:
"""批量分析多张图片"""
results = []
for path in image_paths:
result = self.analyze_single(path, prompt)
results.append(result)
print(f"已分析: {path} -> {result.labels}")
return results
# 使用示例
analyzer = MultiImageAnalyzer()
results = analyzer.analyze_batch(
["img1.jpg", "img2.jpg", "img3.jpg"],
"请分析图片内容,返回JSON格式:{description, labels, confidence}",
)
for r in results:
print(f"{r.image_path}: {r.description[:50]}... (置信度: {r.confidence})")
五、实战二:语音识别 + 文本理解
5.1 语音转文字
from faster_whisper import WhisperModel
from pathlib import Path
class AudioProcessor:
"""音频处理器:语音转文字"""
def __init__(self, model_size: str = "large-v3"):
# 使用GPU加速(device="cuda"),无GPU则用"cpu"
self.model = WhisperModel(
model_size,
device="cpu",
compute_type="int8",
)
def transcribe(
self, audio_path: str, language: str = "zh"
) -> dict:
"""
语音转文字
Args:
audio_path: 音频文件路径(支持mp3/wav/m4a等)
language: 语言代码,zh=中文, en=英文
Returns:
包含完整文本和分段信息的字典
"""
segments, info = self.model.transcribe(
audio_path,
language=language,
beam_size=5,
vad_filter=True, # 启用VAD过滤静音
vad_parameters=dict(
min_silence_duration_ms=500,
),
)
print(f"检测到语言: {info.language} (概率: {info.language_probability:.2%})")
transcript_segments = []
full_text_parts = []
for segment in segments:
entry = {
"start": round(segment.start, 2),
"end": round(segment.end, 2),
"text": segment.text.strip(),
}
transcript_segments.append(entry)
full_text_parts.append(segment.text.strip())
return {
"full_text": "".join(full_text_parts),
"segments": transcript_segments,
"language": info.language,
"duration": round(info.duration, 2),
}
# 使用示例
processor = AudioProcessor()
result = processor.transcribe("meeting_recording.mp3", language="zh")
print(f"时长: {result['duration']}s")
print(f"全文: {result['full_text']}")
for seg in result["segments"]:
print(f"[{seg['start']}s - {seg['end']}s] {seg['text']}")
5.2 语音 + 文本联合理解
from openai import OpenAI
class VoiceQA:
"""语音问答:听懂问题,生成回答"""
def __init__(self):
self.client = OpenAI()
self.audio_processor = AudioProcessor()
def ask(self, audio_path: str, context: str = "") -> str:
"""
听取语音问题并回答
Args:
audio_path: 语音问题文件路径
context: 可选的上下文信息
Returns:
AI的回答文本
"""
# Step 1: 语音转文字
transcript = self.audio_processor.transcribe(audio_path)
question = transcript["full_text"]
print(f"识别到的问题: {question}")
# Step 2: 基于文本生成回答
messages = [
{
"role": "system",
"content": "你是一个智能助手,请根据用户的问题给出准确、详细的回答。",
},
]
if context:
messages.append(
{"role": "system", "content": f"参考上下文:{context}"}
)
messages.append({"role": "user", "content": question})
response = self.client.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=1000,
)
return response.choices[0].message.content
# 使用示例
qa = VoiceQA()
answer = qa.ask(
"question.mp3",
context="这是一个关于Python多模态AI开发的技术讨论会。",
)
print(f"回答: {answer}")
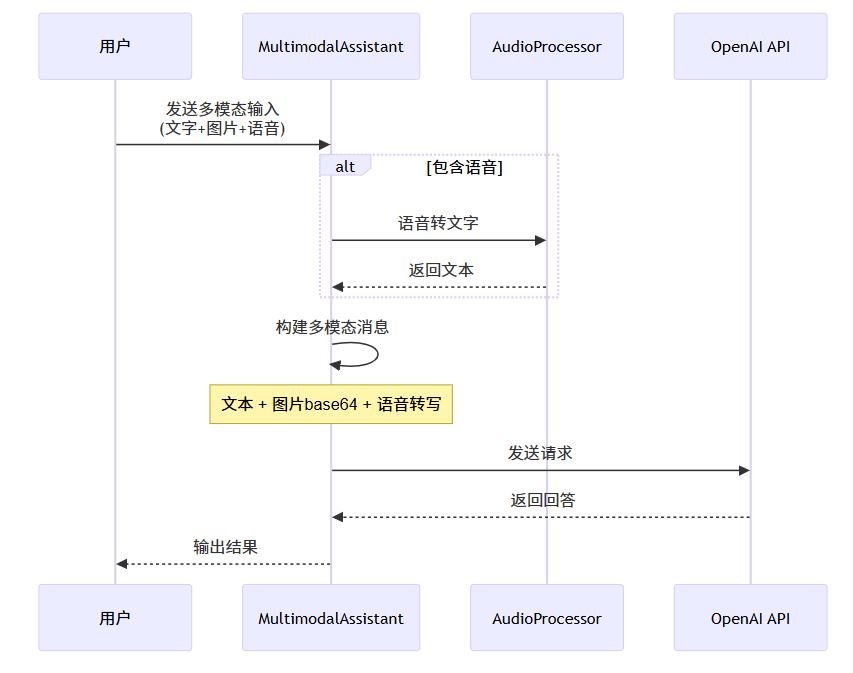
六、实战三:完整的图文音多模态应用
6.1 多模态智能客服
import json
from dataclasses import dataclass
from pathlib import Path
from openai import OpenAI
from typing import Optional
@dataclass
class MultimodalInput:
"""多模态输入数据"""
text: Optional[str] = None
image_path: Optional[str] = None
audio_path: Optional[str] = None
class MultimodalAssistant:
"""
多模态智能助手
同时处理文字、图片、语音三种输入
"""
def __init__(self, api_key: str = None):
self.client = OpenAI(api_key=api_key)
self.audio_processor = AudioProcessor()
self.conversation_history: list[dict] = [
{
"role": "system",
"content": (
"你是一个专业的多模态AI助手。"
"你可以同时理解文字描述、图片内容和语音信息。"
"请综合所有输入信息给出准确、有帮助的回答。"
),
}
]
def _build_content(self, user_input: MultimodalInput) -> list[dict]:
"""构建多模态消息内容"""
content = []
# 处理文本
if user_input.text:
content.append({"type": "text", "text": user_input.text})
# 处理语音(先转文字)
if user_input.audio_path:
transcript = self.audio_processor.transcribe(user_input.audio_path)
voice_text = f"[语音转文字] {transcript['full_text']}"
content.append({"type": "text", "text": voice_text})
# 处理图像
if user_input.image_path:
base64_img = encode_image(user_input.image_path)
content.append({
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_img}",
"detail": "auto",
},
})
return content
def chat(self, user_input: MultimodalInput) -> str:
"""
多模态对话
Args:
user_input: 多模态输入,可包含文字/图片/语音
Returns:
AI助手回答
"""
content = self._build_content(user_input)
self.conversation_history.append({
"role": "user",
"content": content,
})
response = self.client.chat.completions.create(
model="gpt-4o",
messages=self.conversation_history,
max_tokens=1500,
temperature=0.7,
)
answer = response.choices[0].message.content
self.conversation_history.append({
"role": "assistant",
"content": answer,
})
return answer
def reset(self):
"""重置对话历史"""
self.conversation_history = [self.conversation_history[0]]
# ===== 使用示例 =====
assistant = MultimodalAssistant()
# 场景1: 纯文本问答
answer = assistant.chat(MultimodalInput(text="什么是多模态AI?"))
print(f"文本问答: {answer}\n")
# 场景2: 图片 + 文字
answer = assistant.chat(MultimodalInput(
text="这张图片里有什么问题?请帮我分析一下。",
image_path="screenshot.png",
))
print(f"图文分析: {answer}\n")
# 场景3: 语音 + 图片 + 文字(全模态)
answer = assistant.chat(MultimodalInput(
text="结合我发的语音和图片,给我一个完整的解决方案。",
image_path="error_log.png",
audio_path="bug_description.mp3",
))
print(f"多模态回答: {answer}\n")
6.2 完整处理流程图
七、性能优化技巧
7.1 图片压缩
from PIL import Image
import io
def compress_image(
image_path: str,
max_size: tuple[int, int] = (1024, 1024),
quality: int = 85,
) -> str:
"""
压缩图片以减少API调用开销
Args:
image_path: 原图路径
max_size: 最大尺寸(宽, 高)
quality: JPEG压缩质量 (1-100)
Returns:
压缩后的base64字符串
"""
img = Image.open(image_path)
# 保持比例缩放
img.thumbnail(max_size, Image.Resampling.LANCZOS)
# 转为RGB(处理RGBA/P模式图片)
if img.mode in ("RGBA", "P"):
img = img.convert("RGB")
# 压缩为JPEG
buffer = io.BytesIO()
img.save(buffer, format="JPEG", quality=quality)
return base64.b64encode(buffer.getvalue()).decode("utf-8")
7.2 音频预处理
from pydub import AudioSegment
def preprocess_audio(
audio_path: str,
target_format: str = "wav",
sample_rate: int = 16000,
) -> str:
"""
音频预处理:统一格式和采样率
Args:
audio_path: 原始音频路径
target_format: 目标格式
sample_rate: 目标采样率
Returns:
处理后的音频文件路径
"""
audio = AudioSegment.from_file(audio_path)
# 转为单声道
audio = audio.set_channels(1)
# 设置采样率
audio = audio.set_frame_rate(sample_rate)
# 导出
output_path = Path(audio_path).stem + "_processed." + target_format
audio.export(output_path, format=target_format)
return output_path
7.3 异步批量处理
import asyncio
from openai import AsyncOpenAI
async_client = AsyncOpenAI()
async def process_single(
image_path: str, prompt: str
) -> dict:
"""异步处理单张图片"""
base64_img = encode_image(image_path)
response = await async_client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_img}",
},
},
],
}
],
max_tokens=500,
)
return {
"image": image_path,
"result": response.choices[0].message.content,
}
async def process_batch(
image_paths: list[str], prompt: str, concurrency: int = 5
) -> list[dict]:
"""
异步批量处理图片
Args:
image_paths: 图片路径列表
prompt: 统一提示词
concurrency: 最大并发数
Returns:
处理结果列表
"""
semaphore = asyncio.Semaphore(concurrency)
async def limited_process(path: str):
async with semaphore:
return await process_single(path, prompt)
tasks = [limited_process(p) for p in image_paths]
return await asyncio.gather(*tasks)
# 运行批量处理
results = asyncio.run(process_batch(
["img1.jpg", "img2.jpg", "img3.jpg", "img4.jpg", "img5.jpg"],
"请描述这张图片的主要内容,用一句话概括。",
))
for r in results:
print(f"{r['image']}: {r['result']}")
八、多模态应用场景速查
| 场景 | 涉及模态 | 推荐模型 | 难度 |
|---|---|---|---|
| 智能客服 | 文本+图片+语音 | GPT-4o | 中 |
| 以图搜物 | 图片+文本 | CLIP | 中 |
| 会议纪要 | 语音+文本 | Whisper + GPT-4o | 低 |
| 视频理解 | 视频+音频+文本 | GPT-4o | 高 |
| 医疗辅助 | 图像+文本+语音 | GPT-4o + Whisper | 高 |
九、注意事项
- API调用成本:多模态请求的Token消耗远高于纯文本,图片按
tiles计费,建议先用detail: "low"测试 - 图片大小限制:单张图片建议不超过20MB,分辨率不超过4096x4096
- 音频格式:Whisper支持mp3/wav/m4a/flac等常见格式,建议先用pydub统一转wav
- 并发控制:生产环境注意API速率限制,使用信号量控制并发数
- 隐私合规:图片和语音可能包含敏感信息,上传前做好脱敏处理
十、总结
多模态AI不再是前沿研究,而是2026年的工程标配。掌握本文的技术栈,你就能构建出真正"看得见、听得着、会思考"的AI应用。
核心要点回顾:
- 使用 OpenAI Vision API 实现图文理解
- 使用 Whisper 实现高质量语音转文字
- 用 MultimodalAssistant 类统一调度多模态输入
- 注意图片压缩、音频预处理和并发控制等生产优化
多模态的大门已经敞开,现在就开始构建你的第一个多模态应用吧!
以上就是Python构建多模态AI应用的开发指南的详细内容,更多关于Python多模态AI应用开发的资料请关注脚本之家其它相关文章!
相关文章
 大家好,我是Lex 喜欢欺负超人那个Lex 建议大家收藏哦,以后帮小姐姐P自拍,证件照,调尺寸,背景,抠图,直接10行代码搞定,瞬间高大上2021-08-08
大家好,我是Lex 喜欢欺负超人那个Lex 建议大家收藏哦,以后帮小姐姐P自拍,证件照,调尺寸,背景,抠图,直接10行代码搞定,瞬间高大上2021-08-08 这篇文章主要介绍了python操作sqlite的CRUD实现方法,涉及Python操作SQLite数据库CURD相关技巧,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了python操作sqlite的CRUD实现方法,涉及Python操作SQLite数据库CURD相关技巧,需要的朋友可以参考下2015-05-05 这篇文章主要介绍了python批量替换页眉页脚实例代码,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下2018-01-01
这篇文章主要介绍了python批量替换页眉页脚实例代码,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下2018-01-01 这篇文章主要介绍了django模板加载静态文件的方法步骤,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-03-03
这篇文章主要介绍了django模板加载静态文件的方法步骤,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2019-03-03
解决pandas无法在pycharm中使用plot()方法显示图像的问题
今天小编就为大家分享一篇解决pandas无法在pycharm中使用plot()方法显示图像的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
用Python把csv文件批量修改编码为UTF-8格式并转为Excel格式的方法
有时候用excel打开一个csv文件,中文全部显示乱码,然后手动用notepad++打开,修改编码为utf-8并保存后,再用excel打开显示正常,本文将给大家介绍一下用Python把csv文件批量修改编码为UTF-8格式并转为Excel格式的方法,需要的朋友可以参考下2023-09-09 这篇文章主要介绍了python颜色随机生成器的实例代码,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2020-01-01
这篇文章主要介绍了python颜色随机生成器的实例代码,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2020-01-01 这篇文章主要为大家详细介绍了如何使用Python制作Windows凭据添加工具,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2024-12-12
这篇文章主要为大家详细介绍了如何使用Python制作Windows凭据添加工具,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2024-12-12 这篇文章主要介绍了如何用python写个博客迁移工具,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03
这篇文章主要介绍了如何用python写个博客迁移工具,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03 这篇文章主要介绍了python编写扎金花小程序的实例代码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-02-02
这篇文章主要介绍了python编写扎金花小程序的实例代码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-02-02










最新评论