
2026年入门AI还来得及?Python是最好的选择!
【前言】
大家好,我是一名深耕AI入门教学的开发者,最近收到很多小伙伴的提问:2026年入门AI,还来得及吗?Python和AI到底该怎么搭配学?
答案很明确:来得及,且Python是AI入门的唯一最优解。2026年AI圈的核心趋势是“轻量化、低门槛、高落地”,不再需要你啃完厚厚的高数、线代才能入门,借助Python的成熟生态和轻量化工具,0基础也能在1个月内跑通第一个AI项目。
本文拒绝冗余理论,全程以“热点+实战”为核心,包含2026年最火的AI入门方向、可直接复制的代码、清晰的学习流程图和工具对比表,完全贴合CSDN读者的学习需求,新手看完就能上手。
一、2026 Python+AI入门,必抓3个热门新趋势
很多新手入门走弯路,核心是没找对方向。2026年AI入门不再追求“高深算法”,而是“快速落地”,这3个热点方向,新手优先选,就业和实用性双在线:
轻量化AI工具开发:无需搭建复杂环境,用Python+Streamlit/FastAPI,30行代码就能开发AI小工具(如文本总结、图片识别),是2026年新手最易出成果的方向;
大模型微调入门:不用训练大模型,基于开源大模型(如Llama 3、Qwen),用Python快速微调,适配自己的需求(如专属问答机器人),门槛比2025年降低60%;
AI数据标注自动化:用Python+OpenCV结合AI模型,自动完成数据标注(图像、文本),解决AI开发中“数据标注耗时”的痛点,企业需求激增。
| 2026热门入门方向 | 核心Python工具 | 入门难度 | 落地周期 |
|---|---|---|---|
| 轻量化AI工具开发 | Streamlit、FastAPI、LangChain | ★★☆☆☆ | 1-3天(完成第一个工具) |
| 大模型微调入门 | Transformers、Peft、Accelerate | ★★★☆☆ | 1周(完成简单微调) |
| AI数据标注自动化 | OpenCV、YOLOv11、Pandas | ★★★☆☆ | 5-7天(完成自动化标注脚本) |
二、入门前提:不用啃硬骨头,掌握这2点就够了
新手最大的误区:“学AI必须先精通高数”。2026年入门AI,核心是“先会用,再懂原理”,前提知识极简:
<1. Python基础:掌握变量、循环、列表/字典、函数,能看懂简单代码(无需深入面向对象、装饰器等高级特性);
<2. 数学基础:了解基本的加减乘除、矩阵概念即可,后续边实战边补线代、概率论(重点补“特征工程”相关数学知识)。
环境搭建(10分钟搞定,Windows/Mac通用)
避免版本冲突,直接用以下命令一键安装核心工具,附验证代码:
# 1. 安装Python(推荐3.11版本,兼容所有入门工具)
# 官网:https://www.python.org/downloads/,安装时勾选Add Python to PATH
# 验证安装
python --version # 输出Python 3.11.x即为成功
# 2. 升级pip,避免安装失败
pip install --upgrade pip
# 3. 一键安装入门必备工具(覆盖所有热门方向)
pip install streamlit fastapi langchain transformers opencv-python pandas numpy
# 4. 验证工具安装成功
import streamlit as st
import pandas as pd
import cv2
print("所有工具安装成功!")
三、3个实战案例
实战是入门的核心,以下3个案例,从简单到复杂,覆盖上面的3个热门方向,每句代码都有注释,新手也能跑通。
案例1:30行代码开发AI文本总结工具(轻量化工具,最易上手)
用Streamlit+LangChain,快速开发一个文本总结工具,输入任意文本,一键生成精简总结,可直接部署使用:
# 导入必备库
import streamlit as st
from langchain.llms import OpenAI
from langchain.chains import SummarizationChain
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 页面配置(美化界面,CSDN博客展示更美观)
st.set_page_config(page_title="AI文本总结工具", page_icon="📝")
st.title("📝 2026 AI文本总结工具(Python+Streamlit)")
# 输入API密钥(可替换为通义千问、文心一言API)
api_key = st.text_input("请输入你的OpenAI API密钥", type="password")
# 输入需要总结的文本
input_text = st.text_area("请输入需要总结的文本(支持长文本)", height=200)
# 总结按钮
if st.button("开始总结"):
if not api_key or not input_text:
st.warning("请输入API密钥和文本!")
else:
# 初始化大模型
llm = OpenAI(api_key=api_key, model_name="gpt-3.5-turbo-instruct")
# 分割长文本(避免超出模型长度限制)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_text(input_text)
# 初始化总结链
chain = SummarizationChain.from_llm(llm=llm, chain_type="map_reduce")
# 生成总结
summary = chain.run(texts)
# 展示结果
st.success("总结完成!")
st.subheader("总结结果:")
st.write(summary)
运行方法:终端输入 streamlit run 文件名.py,打开浏览器即可使用,适合新手快速体验AI工具开发的乐趣。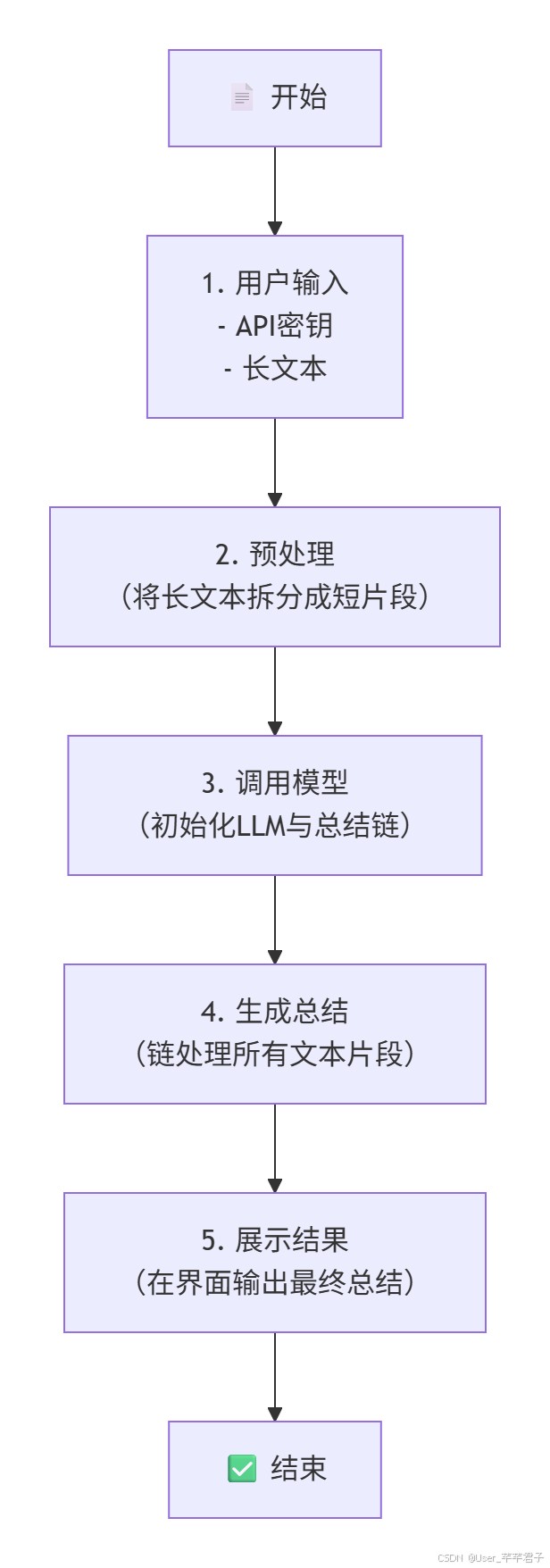
案例2:大模型微调入门(Llama 3微调,2026热门)
用Transformers+Peft,实现Llama 3模型的简单微调,让模型学会专属回答(如“Python入门知识点”),代码简化,新手可快速上手:
# 导入必备库
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
import torch
# 加载Llama 3模型和Tokenizer(开源模型,可免费使用)
model_name = "meta-llama/Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto" # 自动分配GPU/CPU
)
# 配置LoRA微调(轻量化微调,无需大量显存)
lora_config = LoraConfig(
r=8, # 秩,越小显存占用越少
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# 准备微调数据(简单示例,可替换为自己的数据集)
data = [
{"input": "请介绍Python基础语法", "output": "Python基础语法包括变量、循环、条件判断、函数等..."}
]
# 数据预处理(将数据转换为模型可识别的格式)
def format_data(sample):
return f"用户:{sample['input']}\n助手:{sample['output']}"
tokenized_data = tokenizer(
[format_data(sample) for sample in data],
truncation=True,
max_length=256,
padding="max_length"
)
# 配置训练参数(简化配置,新手无需修改)
training_args = TrainingArguments(
output_dir="./llama3-finetune",
per_device_train_batch_size=1,
num_train_epochs=3,
logging_steps=10,
learning_rate=2e-4
)
# 开始微调
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_data
)
trainer.train()
# 保存微调后的模型
model.save_pretrained("./llama3-finetune-final")
print("微调完成!")
案例3:AI自动数据标注(图像标注,企业刚需)
用OpenCV+YOLOv11,实现图像中目标的自动标注,无需手动标注,节省大量时间,贴合企业实际需求:
# 导入必备库
import cv2
from ultralytics import YOLO
# 加载YOLOv11模型(预训练模型,可直接用于目标检测)
model = YOLO("yolov11n.pt") # 轻量化模型,适合新手
# 读取图像(可替换为自己的图像路径)
image = cv2.imread("test.jpg")
# 目标检测(自动识别图像中的目标,如人、车、物体)
results = model(image)
# 自动标注(在图像上绘制边界框和类别)
annotated_image = results[0].plot()
# 保存标注后的图像
cv2.imwrite("annotated_test.jpg", annotated_image)
# 显示标注结果
cv2.imshow("AI自动标注结果", annotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
print("自动标注完成,标注后的图像已保存!")
四、Python+AI入门学习流程图(2026最新,不绕路)
整理了新手最易遵循的学习流程,避开所有弯路,跟着走,1个月入门,3个月能独立做小项目:
五、2026新手避坑指南
避坑1:不要盲目跟风学深度学习——新手先从轻量化工具、大模型调用入手,再学深度学习,循序渐进;
避坑2:不要只看代码不运行——哪怕复制代码,也要亲手跑通,解决报错,才能真正掌握;
避坑3:不要忽视工具学习——2026年AI开发,工具使用能力比算法能力更重要(企业更看重落地);
避坑4:不要囤太多资料——精选1套教程+本文的案例,反复练习,比囤100套资料有用。
六、总结
2026年,Python+AI的入门门槛已经降到最低,不再是“算法大神”的专属,0基础也能快速切入。核心是找对热门方向、多实战、少走弯路。
本文的案例、代码、流程图,足够新手入门使用,建议大家先复制代码跑通,再慢慢理解原理,每天花1-2小时,1个月就能看到明显进步。
到此这篇关于2026年入门AI还来得及?Python是最好的选择!的文章就介绍到这了,更多相关Python+AI入门内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 使用Python的内置json库可以实现JSON和Python对象的互相转换,有效的JSON格式字符串是指使用双引号、键唯一且没有尾随逗号的字符串,json.loads()用于将JSON字符串转换为Python对象,json.dumps()则将Python对象转化为JSON字符串2024-09-09
使用Python的内置json库可以实现JSON和Python对象的互相转换,有效的JSON格式字符串是指使用双引号、键唯一且没有尾随逗号的字符串,json.loads()用于将JSON字符串转换为Python对象,json.dumps()则将Python对象转化为JSON字符串2024-09-09 这篇文章主要介绍了python数字图像处理之高级滤波代码详解,介绍了许多对图像处理的滤波方法,具有一定参考价值,需要的朋友可以了解下。2017-11-11
这篇文章主要介绍了python数字图像处理之高级滤波代码详解,介绍了许多对图像处理的滤波方法,具有一定参考价值,需要的朋友可以了解下。2017-11-11 一个简单的用户注册和登录的页面,涉及到验证,数据库存储等等,本文主要介绍了Flask登录注册项目的简单实现,从目录结构开始,感兴趣的可以了解一下2021-05-05
一个简单的用户注册和登录的页面,涉及到验证,数据库存储等等,本文主要介绍了Flask登录注册项目的简单实现,从目录结构开始,感兴趣的可以了解一下2021-05-05 这篇文章主要介绍了基于Tkinter实现的垃圾分类答题软件代码,图形用户界面是一种人与计算机通信的界面显示格式,允许用户使用鼠标等输入设备操纵屏幕上的图标或菜单选项,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了基于Tkinter实现的垃圾分类答题软件代码,图形用户界面是一种人与计算机通信的界面显示格式,允许用户使用鼠标等输入设备操纵屏幕上的图标或菜单选项,需要的朋友可以参考下2023-04-04 这篇文章主要介绍了套娃式文件夹如何通过Python批量处理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08
这篇文章主要介绍了套娃式文件夹如何通过Python批量处理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08 这篇文章主要介绍了python实现支持目录FTP上传下载文件的方法,适用于windows及Linux平台FTP传输文件及文件夹,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了python实现支持目录FTP上传下载文件的方法,适用于windows及Linux平台FTP传输文件及文件夹,需要的朋友可以参考下2015-06-06 这篇文章主要介绍了使用Python将图片转正方形的两种方法,本文通过实例代码给大家给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-04-04
这篇文章主要介绍了使用Python将图片转正方形的两种方法,本文通过实例代码给大家给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-04-04 检测两个文本文件的相似性是一个常见的任务,可以用于文本去重、抄袭检测等场景,Python 提供了多种方法来实现这一功能,x下面小编就来简单介绍一下吧2025-03-03
检测两个文本文件的相似性是一个常见的任务,可以用于文本去重、抄袭检测等场景,Python 提供了多种方法来实现这一功能,x下面小编就来简单介绍一下吧2025-03-03 这篇文章主要为大家详细介绍了python实现书法碑帖图片分割,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-03-03
这篇文章主要为大家详细介绍了python实现书法碑帖图片分割,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-03-03 这篇文章主要介绍了OpenCV 读取图像imread的使用详解,文章围绕主题展开详细的内容介绍,具有一定的参考价值,感兴趣的小伙伴可以参考一下2022-09-09
这篇文章主要介绍了OpenCV 读取图像imread的使用详解,文章围绕主题展开详细的内容介绍,具有一定的参考价值,感兴趣的小伙伴可以参考一下2022-09-09










最新评论