
Python自动化筛选Excel工作簿中多个工作表的实战教学
1. 问题背景与写作目标
本文主题是 筛选一个工作簿中的所有工作表数据。这一节的价值不在于“会不会点 Excel 筛选按钮”,而是把重复筛选动作变成一套可以复用的自动化流程。
在日常办公里,经常会遇到这样的表格:一个工作簿里有很多张工作表,例如 1 月、2 月、3 月、4 月,或者华北、华东、华南等区域表。现在我们要按同一个条件筛选每张表,比如只保留 销售区域 = 华东 的记录。如果手工做,就要一张表一张表点筛选、复制、粘贴、保存,表一多就很容易漏掉。
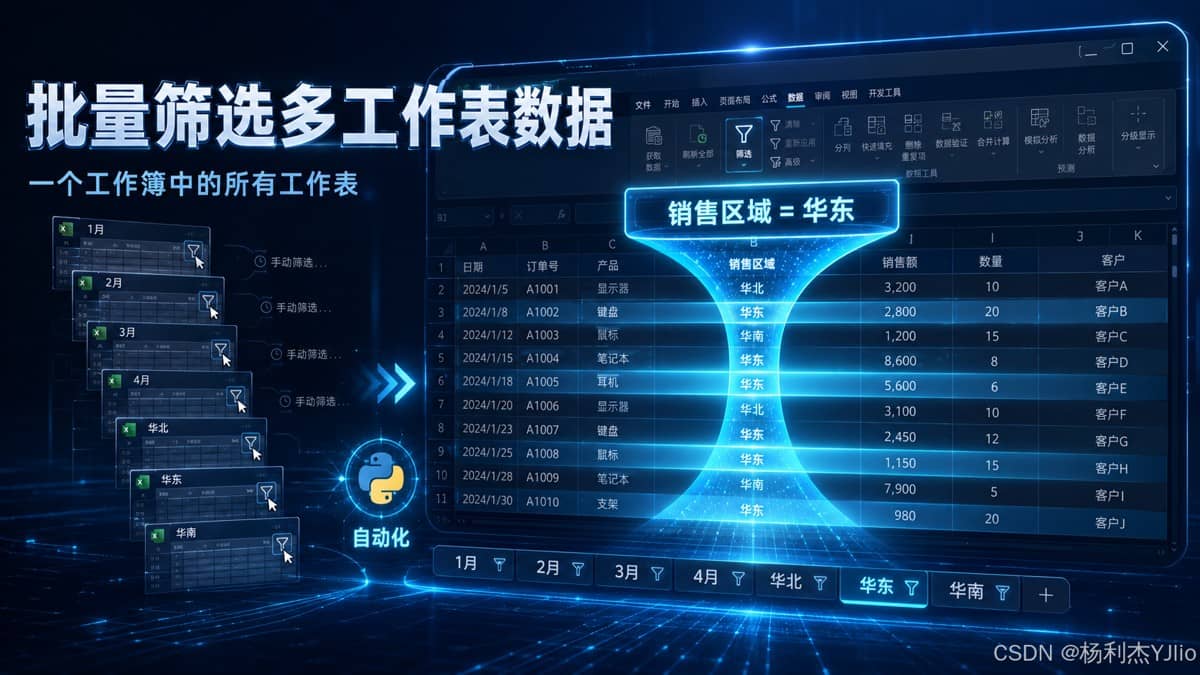
这张图展示了本文要解决的核心问题:对一个工作簿中的多个工作表,统一按照同一个条件进行批量筛选。

从这张图中我们可以看出,左侧有多个工作表,右侧通过“销售区域 = 华东”的条件把目标数据筛选出来。这里真正值得注意的是:筛选对象不是一张表,而是整个工作簿里的所有工作表。这就是 Python 自动化比手工操作更有价值的地方。
原理说明:本案例的本质是“批量遍历 + 条件过滤 + 结果写入”。Excel 负责存储表格,pandas 负责数据筛选,xlwings 负责连接和操作工作簿。
2. 适用场景与限制条件
这个案例适合处理“多个工作表结构相似,并且需要按照同一个字段筛选”的场景。比如所有工作表里都有“销售区域”字段,现在只保留“华东”;或者所有工作表里都有“状态”字段,只保留“有效”;再或者所有工作表里都有“金额”字段,只保留大于 1000 的记录。
常见适用场景包括:
1. 多个月份销售表中,只筛选某个区域的数据;
2. 多个部门明细表中,只筛选某个状态的数据;
3. 多张订单表中,只筛选指定产品类别或指定客户的数据;
4. 多个库存表中,只筛选库存不足、状态异常或金额超过阈值的记录。
限制条件:这类脚本默认每张工作表的数据结构比较接近。如果有的表第一行不是表头、有的表字段名称不一致、有的表中间有空行,那么脚本就需要额外做兼容处理,不能直接照搬最简单版本。
推荐做法:正式运行前,先打开源工作簿确认三件事:表头是否在第一行、筛选字段是否一致、数据区域是否连续。只要这三点不稳定,批量筛选就容易出现漏筛或跳过。
3. 核心原理与实现流程
这一节的核心流程可以拆成五步:打开工作簿、遍历每张工作表、读取数据为 DataFrame、按字段条件筛选、把筛选结果写入新的工作簿。只要这个流程理解清楚,代码就不会显得乱。
这张图展示了批量筛选工作表数据的完整处理链路。
从这张图中我们可以看出,程序不是直接在 Excel 界面上“模拟点击筛选按钮”,而是把每张工作表的数据读取出来,转换成 DataFrame,再通过条件表达式筛选出目标记录,最后写入结果文件。这种方式比模拟鼠标点击更稳定,也更容易加日志和校验。
原理说明:pandas 的优势是数据过滤能力强,适合做 data[data[字段] == 条件] 这类判断;xlwings 的优势是可以直接和 Excel 工作簿交互,适合读取、写入、保存文件。
4. 完整代码:筛选一个工作簿中所有工作表的数据
下面这段代码演示一个常见场景:遍历 销售明细.xlsx 中的所有工作表,只保留 销售区域 等于 华东 的数据,并将筛选结果写入一个新的工作簿。
这张图展示了 pandas + xlwings 配合完成自动筛选的场景:左侧是 Python 代码,右侧是 Excel 数据源和筛选结果。
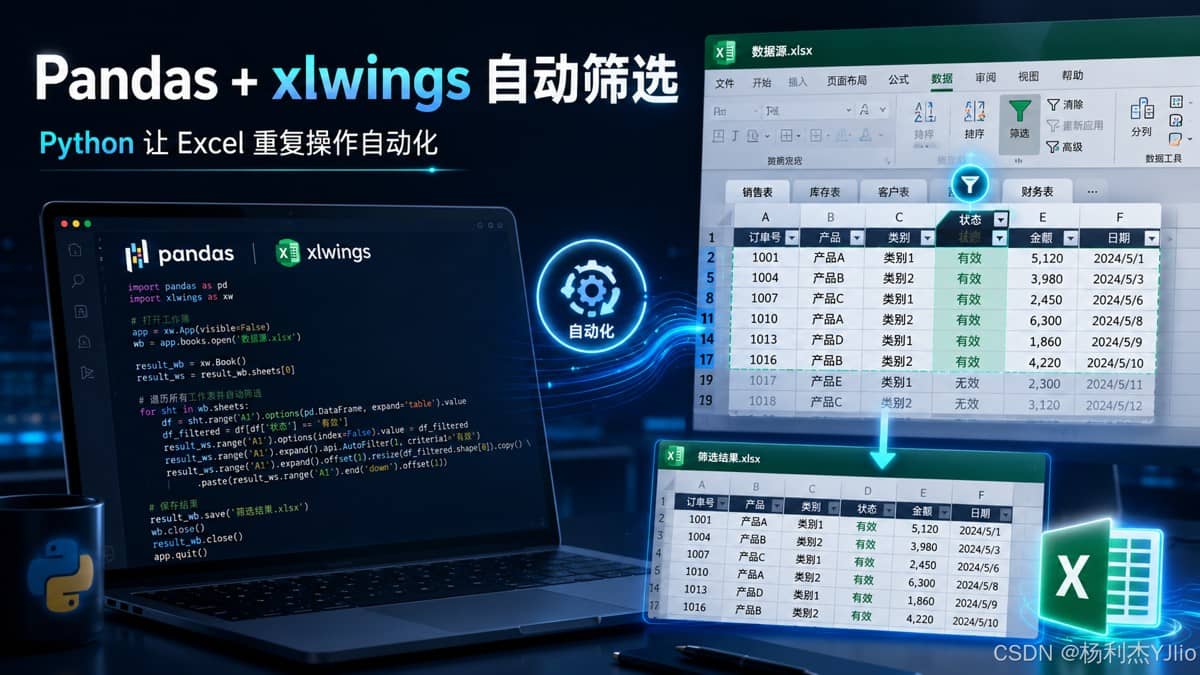
从这张图中我们可以看出,pandas 负责把数据筛出来,xlwings 负责打开工作簿和写入结果。这个分工要理解清楚,否则很容易把 pandas 和 xlwings 的职责混在一起。
import os
import re
import pandas as pd
import xlwings as xw
def safe_sheet_name(name):
"""
清理工作表名称,避免超过 Excel 限制或包含非法字符
"""
name = str(name).strip()
name = re.sub(r'[\\/:*?\[\]]', "_", name)
return name[:31] if name else "筛选结果"
# ====== 需要根据实际情况修改的参数 ======
source_file = r"E:\example\销售明细.xlsx"
result_file = r"E:\example\筛选结果_华东.xlsx"
filter_column = "销售区域"
filter_value = "华东"
# =====================================
app = xw.App(visible=False, add_book=False)
try:
wb = app.books.open(source_file)
result_wb = app.books.add()
# 删除默认工作簿中多余的空白工作表,只保留第一张备用
while len(result_wb.sheets) > 1:
result_wb.sheets[-1].delete()
output_count = 0
for sht in wb.sheets:
print(f"正在处理工作表:{sht.name}")
# 读取当前连续数据区域为 DataFrame
try:
data = sht.range("A1").options(
pd.DataFrame,
header=1,
index=False,
expand="table"
).value
except Exception as e:
print(f"跳过:{sht.name},读取失败:{e}")
continue
if data is None or data.empty:
print(f"跳过:{sht.name},空表或无有效数据")
continue
# 清理字段名前后空格
data.columns = [str(col).strip() for col in data.columns]
if filter_column not in data.columns:
print(f"跳过:{sht.name},缺少字段:{filter_column}")
continue
# 条件筛选
result = data[data[filter_column].astype(str).str.strip() == filter_value]
if result.empty:
print(f"未命中:{sht.name},没有符合条件的数据")
continue
# 写入结果工作簿
if output_count == 0:
result_sht = result_wb.sheets[0]
result_sht.name = safe_sheet_name(sht.name)
else:
result_sht = result_wb.sheets.add(name=safe_sheet_name(sht.name), after=result_wb.sheets[-1])
result_sht.range("A1").value = result
result_sht.autofit()
output_count += 1
print(f"已写入:{sht.name},筛选结果 {len(result)} 行")
wb.close()
if output_count == 0:
print("没有任何工作表筛选出结果,结果文件未保存。")
result_wb.close()
else:
result_wb.save(result_file)
result_wb.close()
print(f"筛选完成:{result_file}")
finally:
app.quit()
这段代码比最基础版本多做了几个保护:字段名前后空格清理、目标字段是否存在判断、空结果跳过、工作表名称合法化、结果数量统计。这些细节不是为了“显得复杂”,而是为了让脚本更接近真实办公环境。
风险提醒:如果你直接使用最简单的筛选代码,不判断字段是否存在,那么只要某一张工作表字段名不一致,整个脚本就可能中断。批量处理时,稳定性比代码短更重要。
5. 关键判断:为什么要先检查字段是否存在
批量处理 Excel 时,不要默认所有工作表都完全规范。现实里最常见的问题不是代码不会写,而是数据源不干净。比如同一个字段,有的表叫“销售区域”,有的表叫“区域”,还有的表干脆缺少这一列。
这张图展示了批量筛选前必须做的字段检查:字段正确可以继续执行,字段不匹配或字段缺失则需要跳过并提示。
从这张图中我们可以看出,字段检查不是可有可无的步骤。左侧表格中存在“销售区域”字段,可以安全执行筛选;右侧表格虽然也有区域数据,但字段名不是“销售区域”,或者直接缺少目标字段,程序就不能强行筛选。
原理说明:pandas 按列名筛选时,本质上是通过 data[filter_column] 定位目标列。如果列名不存在,就会触发异常。因此在正式筛选前,必须先执行 if filter_column not in data.columns。
if filter_column not in data.columns:
print(f"跳过:{sht.name},缺少字段:{filter_column}")
continue
推荐做法:如果你的数据来源比较混乱,可以维护一个字段别名列表,把“销售区域”“区域”“所属区域”都识别为同一个筛选字段。
candidate_columns = ["销售区域", "区域", "所属区域"]
real_column = None
for col in candidate_columns:
if col in data.columns:
real_column = col
break
if real_column is None:
print(f"跳过:{sht.name},未找到可用区域字段")
continue
result = data[data[real_column].astype(str).str.strip() == filter_value]
注意:字段别名虽然能提高兼容性,但也可能带来误判。如果“区域”和“销售区域”在业务含义上不是同一个字段,就不要强行合并。
6. 效果验证与数据对比
脚本运行完成以后,不要只看有没有生成结果文件。真正要验证的是:结果文件能不能打开,筛选出来的数据是不是都符合条件,行数是否符合预期,关键字段有没有丢失。
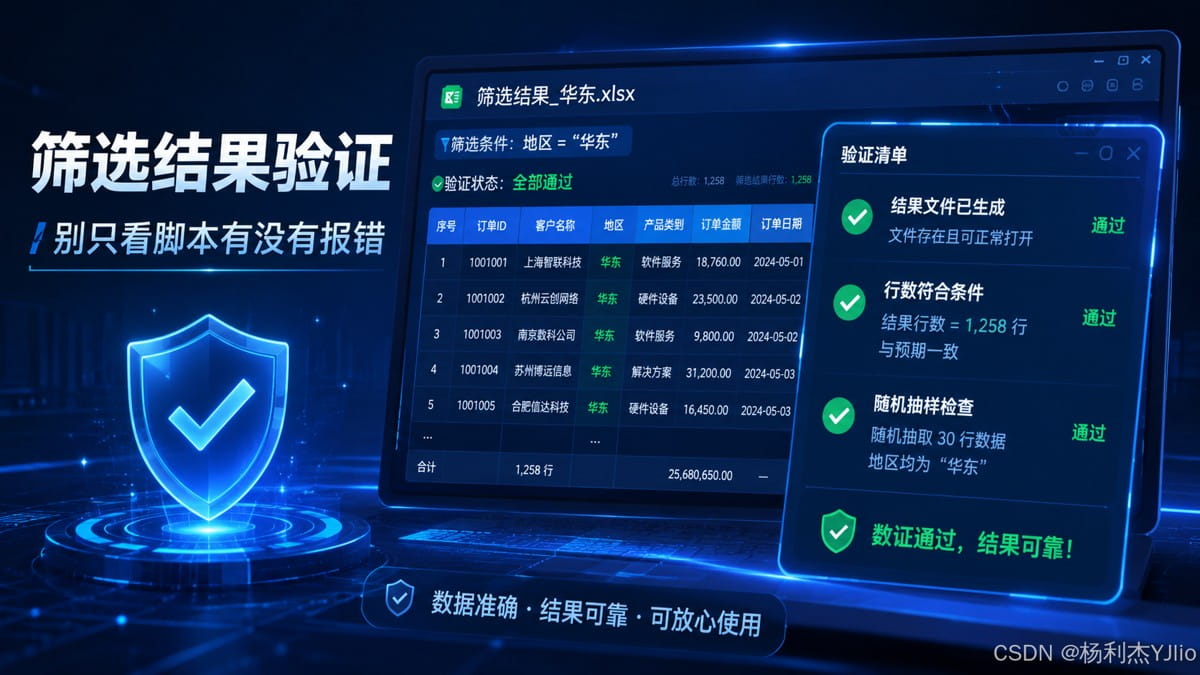
这张图展示了筛选结果验证的思路:不仅要确认结果文件生成,还要检查行数、条件和抽样数据。

从这张图中我们可以看出,结果验证至少包含三层:第一,结果文件已经生成并且可以正常打开;第二,结果行数与预期一致;第三,随机抽样检查时,筛选字段确实都满足“华东”。这一步决定了脚本结果是否可靠。
我建议运行后至少检查以下几项:
1. 输出目录中是否生成了 筛选结果_华东.xlsx;
2. 结果工作簿中是否存在对应的工作表;
3. 每张结果表中的 销售区域 是否全部为 华东;
4. 筛选结果行数是否和源表中手工筛选结果一致;
5. 金额、日期、客户名称等关键字段是否完整保留。
# 简单验证某个结果表中的销售区域是否都为目标值
check_result = result[filter_column].astype(str).str.strip().eq(filter_value).all()
if check_result:
print(f"{sht.name} 验证通过:筛选结果全部为 {filter_value}")
else:
print(f"{sht.name} 验证失败:存在不符合条件的数据")
推荐做法:正式交付前,随机抽查 2~3 张结果表,再回到源表中用 Excel 手工筛选一次进行对照。批量脚本最怕“整体看起来成功,但某几张表处理错了”。
7. 常见问题与踩坑记录
这个案例看起来不难,但真实运行时很容易踩坑。问题通常不是 pandas 的筛选语法,而是 Excel 文件本身不规范。
坑 1:字段名有隐藏空格。例如表头显示为“销售区域”,但实际是“销售区域 ”。肉眼不容易发现,但程序会认为这是两个不同字段。代码里用 strip() 清理字段名,就是为了处理这种问题。
坑 2:筛选值不统一。有的表写“华东”,有的表写“华东区”,还有的写“华东区域”。如果业务上这些代表同一个意思,就需要先做标准化。
data[filter_column] = data[filter_column].astype(str).str.strip()
data[filter_column] = data[filter_column].replace({
"华东区": "华东",
"华东区域": "华东"
})
坑 3:工作表名称超过 31 个字符。Excel 工作表名称有长度限制,如果直接拿原表名创建结果表,可能保存失败。所以代码中使用了 safe_sheet_name() 做截断处理。
坑 4:结果文件正在打开。如果 筛选结果_华东.xlsx 已经被 Excel 打开,脚本保存时可能失败。运行前建议关闭源文件和结果文件。
坑 5:默认空白工作表没有处理。新建结果工作簿时,Excel 通常会自带一个空白工作表。如果不处理,最后结果文件里可能多出一个无用空表。上面的代码通过复用第一张表或删除多余表来减少这个问题。
经验判断:批量脚本不是写完能跑一次就算完成。真正可用的脚本,必须能在遇到空表、缺字段、字段名有空格、结果为空时给出明确提示,而不是直接中断。
8. 总结与进阶建议
这一节的核心,不是记住某一段 pandas 代码,而是理解批量筛选 Excel 工作表的完整处理模式:打开工作簿、遍历工作表、读取数据、判断字段、执行筛选、写入结果、验证输出。
我认为这篇笔记最值得带走的经验有三点。
第一,批量处理前必须明确对象和边界。你要处理的是一个工作簿里的所有工作表,不是一张表,也不是多个文件夹中的文件。对象不同,代码结构就不同。
第二,字段校验比筛选语法更重要。筛选语法很简单,但字段不一致会直接影响结果可靠性。真实办公数据里,字段名异常比语法错误更常见。
第三,结果验证不能省。生成文件只是第一步,结果是否符合条件才是交付标准。尤其是涉及销售金额、订单、客户、资产等数据时,必须核对行数和关键字段。
如果后续继续扩展,可以把筛选字段、筛选条件、源文件路径和输出路径做成参数,甚至做成一个小工具界面。这样就能从“读书笔记中的脚本”升级成“真实办公场景可复用的自动化工具”。
以上就是Python自动化筛选Excel工作簿中多个工作表的实战教学的详细内容,更多关于Python筛选Excel工作表的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了通过实例解析python创建进程常用方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了通过实例解析python创建进程常用方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
python面试题之read、readline和readlines的区别详解
当python进行文件的读取会遇到三个不同的函数,它们分别是read(),readline(),和readlines(),下面这篇文章主要给大家介绍了关于python面试题之read、readline和readlines区别的相关资料,需要的朋友可以参考下2022-07-07 在 Python 中处理电子邮件时,标准库中的 email 模块是首选工具,无论你需要发送 HTML 格式的邮件、带附件的邮件,还是解析复杂的邮件结构,email 库都能胜任,这篇博客将带你系统地认识并掌握 email 模块的使用方法与内部机制,需要的朋友可以参考下2025-06-06
在 Python 中处理电子邮件时,标准库中的 email 模块是首选工具,无论你需要发送 HTML 格式的邮件、带附件的邮件,还是解析复杂的邮件结构,email 库都能胜任,这篇博客将带你系统地认识并掌握 email 模块的使用方法与内部机制,需要的朋友可以参考下2025-06-06 本文主要介绍了python实现MongoDB的双活示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了python实现MongoDB的双活示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02 这篇文章主要介绍了Python基于httpx模块实现发送请求,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
这篇文章主要介绍了Python基于httpx模块实现发送请求,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07 这篇文章主要介绍了Python基于QQ邮箱实现SSL发送,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04
这篇文章主要介绍了Python基于QQ邮箱实现SSL发送,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-04-04 这篇文章主要给大家介绍了关于python最短路径的求解Dijkstra算法的相关资料,并使用Python的heapq模块实现该算法,通过示例展示了如何从节点0到节点8求解最短路径,需要的朋友可以参考下2024-11-11
这篇文章主要给大家介绍了关于python最短路径的求解Dijkstra算法的相关资料,并使用Python的heapq模块实现该算法,通过示例展示了如何从节点0到节点8求解最短路径,需要的朋友可以参考下2024-11-11 在 Python 编程里,数字类型是极为基础且关键的数据类型,本文将深入介绍 Python 数字类型的内置方法,同时辅以详细的代码示例,需要的可以了解下2025-04-04
在 Python 编程里,数字类型是极为基础且关键的数据类型,本文将深入介绍 Python 数字类型的内置方法,同时辅以详细的代码示例,需要的可以了解下2025-04-04 由于采用了新的发行计划:PEP 602 -- Annual Release Cycle for Python,我们可以看到更短的开发窗口,我们有望在 2021 年 10 月使用今天分享的这些新特性2021-09-09
由于采用了新的发行计划:PEP 602 -- Annual Release Cycle for Python,我们可以看到更短的开发窗口,我们有望在 2021 年 10 月使用今天分享的这些新特性2021-09-09 这篇文章主要为大家介绍了python神经网络pytorch中BN运算操作自实现示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了python神经网络pytorch中BN运算操作自实现示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05










最新评论