
科普:搜索引擎的基本工作原理
那么问题来了,什么是关键词。
英文来说,比如 this is a book,中文,这是一本书。
英文很自然是四个单词,空格是天然的分词符,中文呢?你不能把一句话当作关键词吧(如果把一句话当作关键词,那么你搜索其中部分信息的时候,是无法索引命中的,比如搜索一本书,就搜索不出来了,而这显然是不符合搜索引擎诉求的)。所以要分词。
最开始,最简单的思路是,每个字都切开,这个以前叫字索引,每个字建立索引,并标注位置,如果用户搜索一个关键词,也是把关键词拆成字来搜索再组合结果,但这样问题就来了。
比如搜索关键词 “海鲜”的时候,会出现结果,上海鲜花,这显然不是应该的搜索结果。
比如搜索关键词 “和服”的时候,会出现结果,交换机和服务器。
这些都是蛮荒期的google也不能幸免的问题。
到后来有个梗,别笑,这些都是血泪梗,半夜电话过来,说网监通过搜索发现你社区有淫秽内容要求必须删除,否则就关闭你的网站,夜半惊醒认真排查,百思不得其解,苦苦哀求提供信息线索,最后发现,有人发了一条小广告,“求购二十四口交换机” 。 还有,涉嫌政治敏感,查到最后 “提供三台独立服务器”, 看出其中敏感词了没?你说冤不冤。 这两个故事可能并不是真的,因为都是网上看到的,但是我想说,类似这样的事情真的有,并非都是空穴来风。
所以,分词,是亚洲很多语言需要额外处理的事情,而西方语言不存在的问题。
但分词不是说说那么简单,比如几点,1:如何识别人名?2、互联网新词如何识别?比如 “不明觉厉”。3、中英混排的坑,比如QQ表情。
做一个分词系统,说到底也不难,但是要做一个自动学习,与时俱进,又能高效率灵活的分词引擎,还是很有技术难度的。 当然,这方面我不是专家,不敢妄言了。
现在机器学习技术发达了,特别是google在深度学习领域拥有领先优势,以前很多通过人工做标定,做分类的工作可以交给算法完成,从某种意义来说,本地化的工作可以让机器学习去完成;未来,也许深度学习技术可以自己学习掌握本地化的技巧。 但我想说两点,第一,从搜索引擎发展历史看,在深度学习技术还没成熟的情况下,本地化的工作是非常重要的,也是很重要的决定竞争成败的要素;第二,即便现在深度学习已经很强大,基于当地语言的人工参与,标定,测试,反馈,一些本地化的工作依然对深度学习的效率和效果拥有不可替代的作用。
索引系统除了分词之外,还有一些要点,比如实时索引,因为一次索引库的更新是个大动静,一般网站运营者知道,自己网站内容更新后,需要等索引库下一次更新才能看到效果,而且索引库针对不同权重的网站内容,更新的频次也不太一样。 但诸如一些高优先的资讯网站,以及新闻搜索,索引库是可以做到近似实时索引的,所以我们在新闻搜索里,几分钟前的信息就已经可以搜索到了。
我以前经常吐槽一个事情,我在百度空间发表的文章,每次都是google率先索引收录,当时他们的解释是,猜测是因为很多人通过google阅读器订阅我的博客,而google阅读器很可能是google快速索引的入口。(然并卵,百度空间已经没有了,google阅读器也没有了。)
索引系统的权值体系,是所有SEOER们最关心的问题,他们经常通过不同方式组合策略,观察搜索引擎的收录,排名,来路情况,然后通过对比分析整理出相关的策略,这玩意说出来可以开很长一篇了,但今天就不提了。
但我说一个事实,很多外面的公司,做SEO的,会误认为百度里面的人熟悉这里的门道和规律,很多人高价去挖百度的搜索产品经理和技术工程师去做SEO,结果,呵呵,呵呵。 而外面那些草根创业者,有些善于此道的,真的比百度的人还清楚,搜索权值的影响关系,和更新频次等等,比如前面说到的,身价几十亿的那个80后创业者。
基于结果反推策略,比身在其中却不识全局的参与者,更能找到系统的关键点,有意思不。
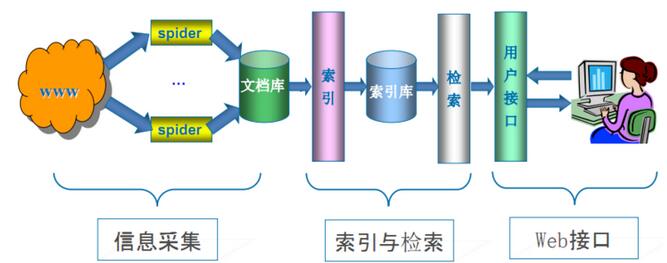
3、查询展现
用户在浏览器或者在手机客户端输入一个关键词,或者几个关键词,甚至一句话,这个在服务端,应答程序获取后处理步骤如下
第一步,会检查最近时间有没有人搜索过同样的关键词,如果存在这样的缓存,最快的处理是将这块缓存提供给你,这样查询效率最高,对后端负载压力最低。
第二步,发现这个输入查询最近没有搜索,或者有其他条件的原因必须更新结果,那么会将这个用户输入的词,进行分词,没错,如果不止一个关键词,或者是一句话的情况下,应答程序会又一次分词,将搜索的查询拆成几个不同的关键词。
第三步,将切分后的关键词分发到查询系统中,查询系统会去索引库查询,索引库是个庞大的分布式系统,先分析这个关键词属于哪一块哪一台服务器,索引是一种有序的数据组合,我们用可以用近似二分法的方式思考,不管数据规模多大,你用二分法去查找一个结果,查询频次是log2(N),这个就保证了海量数据下,查询一个关键词是非常快非常快的。 当然,实际情况会比二分法复杂很多,这样说比较容易理解而已,再复杂些不是我不告诉大家,是我自己都不是很清楚呢。
第四步,不同关键词的查询结果(只是按权值排序的部分顶部结果,绝对不是全部结果),基于权值倒序,会再汇总在一起,然后把共同命中的部分反馈回来,并做最后的权值排序。
记住,搜索引擎绝对不会返回所有结果,这个开销谁都受不了,百度也不行,google也不行,翻页都是有限制的。
再记住,如果你多个关键词里有多个不同品类冷门词,搜索引擎有可能会舍弃其中一个冷门词,因为汇总数据很可能不包含共同结果。搜索技术不要神话,这样的范例偶尔会出现。
这是三大部分,多说一点,其实还有第四部分。
4、用户点击行为采集和反馈部分
基于用户的翻页,点击分布,对搜索结果的优劣做判定,并对权值做调整,但这个早期搜索引擎是没有的,后面才有,所以暂时不列为必备的三大块。
此外,一些对搜索优化的机器学习策略,对易混词识别,同音词识别等等,相当部分也都基于用户行为反馈进行,这是后话,这里不展开。
关于第四部分,我以前说过一个词,点击提权,我说这个词价值千金,我猜很多人并没理解。没理解就好,要不我要被一些同行骂死了。
以上是单指搜索引擎的工作原理,和一些技术逻辑,当然,只是入门级的解读,毕竟再深入就不是我能讲解的了。
但搜索引擎的本地化,并不局限于搜索技术的本地化。
百度的强大,不只是搜索技术,当然有些人会说百度没有搜索技术,这种言论我就不争论了,我不试图改变任何人的观点,我只列一些事实而已。
百度的强大还来自于两大块,第一是内容护城河,第二是入口把控。
前者是百度贴吧,百度mp3,百度知道,百度百科,百度文库
后者是hao123和百度联盟。
这两块都是本地化,google进中国的时候,在这两块都有动作。
投资天涯,收购265,以及大力发展google联盟,这些都是本地化。
此外,重申一下,百度全家桶的出现以及,百度全家桶和hao123的捆绑,是360崛起之后的事情,hao123从百度收购到360崛起之前,一直风平浪静的没做任何推广和捆绑,从历史事实而言,请勿将本地化等同于流氓化。
作者:江西SEO曾庆平(www.qingpingseo.com)
版权所有。转载时必须以链接形式注明作者和原始出处。请大家尊重原创,珍惜别人的汗水!
相关文章

宝塔面板屏蔽 Censys的配置方法(防止源站 IP 泄露)
Censys 搜索引擎很强大,Censys 每天都会扫描 IPv4 地址空间,以搜索所有联网设备并收集相关的信息,并返回一份有关资源(如设备、网站和证书)配置和部署信息的总体报告2025-03-01 近来站长们应该基本都遇到过 DDOS 攻击,特别是 CC,如果放任不管,会导致服务器资源紧张,导致用户无法正常访问,有时间就算接入了高防服务器,源站 IP 还是被打,网站打不2025-03-01
近来站长们应该基本都遇到过 DDOS 攻击,特别是 CC,如果放任不管,会导致服务器资源紧张,导致用户无法正常访问,有时间就算接入了高防服务器,源站 IP 还是被打,网站打不2025-03-01 当我们谈论绕过CDN查找真实IP的时候,不得不提到SSL证书,它确实是我们寻找真实IP的一大利器,至于为什么SSL证书会导致源站IP泄露?很多人或许没有深入了解这个问题,目前好2025-03-01
当我们谈论绕过CDN查找真实IP的时候,不得不提到SSL证书,它确实是我们寻找真实IP的一大利器,至于为什么SSL证书会导致源站IP泄露?很多人或许没有深入了解这个问题,目前好2025-03-01 默认CloudFlare都是让大家通过dns接入,但大家因为已经习惯了dnspod等解析方式,那么cname就比较方便大家使用了,下面为大家分享一下cname的接入方法,需要的朋友可以参考下2025-02-20
默认CloudFlare都是让大家通过dns接入,但大家因为已经习惯了dnspod等解析方式,那么cname就比较方便大家使用了,下面为大家分享一下cname的接入方法,需要的朋友可以参考下2025-02-20- 是否需要高防服务器呢,最近很多网站遭受ddos与cc攻击,双11之际旅途云特为大家提供了性价比更高的高防服务器套餐需要的朋友可以咨询2023-11-12
- 在本篇文章里小编给大家整理的是关于华为云优惠券领取的方法和入口,有此需要的朋友们可以领取下,希望对你有帮助。2020-03-12
- 在本篇文章里小编给大家整理了关于华为云优惠券使用方法和详细步骤,有兴趣的朋友们可以学习下。2020-03-12
 我们给大家带来如何用优惠的方法购买华为云主机的方法以及给大家分享华为云的优惠券和代金券,希望能够帮助到大家。2020-02-26
我们给大家带来如何用优惠的方法购买华为云主机的方法以及给大家分享华为云的优惠券和代金券,希望能够帮助到大家。2020-02-26
进行https证书申请安装和tomcat https证书安装的方法
对于https证书,想必大家已经非常熟悉了,这是一种可以保护网站安全的证书,以https开头的网站都是具有这一证书的网站。今天给大家介绍怎样进行https证书申请安装和tomcat2019-10-31 库店创始人郑剑豪,原寺库商城总经理,2010年聚划算创始团队成员,5年时间帮助寺库成功上市。库店,是美国纳斯达克上市企业寺库旗下高品质社交电商平台,获京东与LVMH集团旗下基2018-11-01
库店创始人郑剑豪,原寺库商城总经理,2010年聚划算创始团队成员,5年时间帮助寺库成功上市。库店,是美国纳斯达克上市企业寺库旗下高品质社交电商平台,获京东与LVMH集团旗下基2018-11-01







最新评论